 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Feature-Driven Deep Learning for the Prediction of Duck Body Dimensions and Weight
Mar 19, 2025Accurate body dimension and weight measurements are critical for optimizing poultry management, health assessment, and economic efficiency. This study introduces an innovative deep learning-based model leveraging multimodal data-2D RGB images from different views, depth images, and 3D point clouds-for the non-invasive estimation of duck body dimensions and weight. A dataset of 1,023 Linwu ducks, comprising over 5,000 samples with diverse postures and conditions, was collected to support model training. The proposed method innovatively employs PointNet++ to extract key feature points from point clouds, extracts and computes corresponding 3D geometric features, and fuses them with multi-view convolutional 2D features. A Transformer encoder is then utilized to capture long-range dependencies and refine feature interactions, thereby enhancing prediction robustness. The model achieved a mean absolute percentage error (MAPE) of 6.33% and an R2 of 0.953 across eight morphometric parameters, demonstrating strong predictive capability. Unlike conventional manual measurements, the proposed model enables high-precision estimation while eliminating the necessity for physical handling, thereby reducing animal stress and broadening its application scope. This study marks the first application of deep learning techniques to poultry body dimension and weight estimation, providing a valuable reference for the intelligent and precise management of the livestock industry with far-reaching practical significance.
Efficient One-Step Diffusion Refinement for Snapshot Compressive Imaging
Sep 11, 2024Coded Aperture Snapshot Spectral Imaging (CASSI) is a crucial technique for capturing three-dimensional multispectral images (MSIs) through the complex inverse task of reconstructing these images from coded two-dimensional measurements. Current state-of-the-art methods, predominantly end-to-end, face limitations in reconstructing high-frequency details and often rely on constrained datasets like KAIST and CAVE, resulting in models with poor generalizability. In response to these challenges, this paper introduces a novel one-step Diffusion Probabilistic Model within a self-supervised adaptation framework for Snapshot Compressive Imaging (SCI). Our approach leverages a pretrained SCI reconstruction network to generate initial predictions from two-dimensional measurements. Subsequently, a one-step diffusion model produces high-frequency residuals to enhance these initial predictions. Additionally, acknowledging the high costs associated with collecting MSIs, we develop a self-supervised paradigm based on the Equivariant Imaging (EI) framework. Experimental results validate the superiority of our model compared to previous methods, showcasing its simplicity and adaptability to various end-to-end or unfolding techniques.
Identifying every building's function in large-scale urban areas with multi-modality remote-sensing data
May 08, 2024
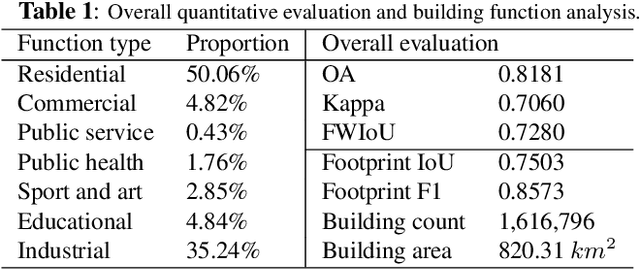

Buildings, as fundamental man-made structures in urban environments, serve as crucial indicators for understanding various city function zones. Rapid urbanization has raised an urgent need for efficiently surveying building footprints and functions. In this study, we proposed a semi-supervised framework to identify every building's function in large-scale urban areas with multi-modality remote-sensing data. In detail, optical images, building height, and nighttime-light data are collected to describe the morphological attributes of buildings. Then, the area of interest (AOI) and building masks from the volunteered geographic information (VGI) data are collected to form sparsely labeled samples. Furthermore, the multi-modality data and weak labels are utilized to train a segmentation model with a semi-supervised strategy. Finally, results are evaluated by 20,000 validation points and statistical survey reports from the government. The evaluations reveal that the produced function maps achieve an OA of 82% and Kappa of 71% among 1,616,796 buildings in Shanghai, China. This study has the potential to support large-scale urban management and sustainable urban development. All collected data and produced maps are open access at https://github.com/LiZhuoHong/BuildingMap.
Generalized Few-Shot Meets Remote Sensing: Discovering Novel Classes in Land Cover Mapping via Hybrid Semantic Segmentation Framework
Apr 19, 2024Land-cover mapping is one of the vital applications in Earth observation, aiming at classifying each pixel's land-cover type of remote-sensing images. As natural and human activities change the landscape, the land-cover map needs to be rapidly updated. However, discovering newly appeared land-cover types in existing classification systems is still a non-trivial task hindered by various scales of complex land objects and insufficient labeled data over a wide-span geographic area. In this paper, we propose a generalized few-shot segmentation-based framework, named SegLand, to update novel classes in high-resolution land-cover mapping. Specifically, the proposed framework is designed in three parts: (a) Data pre-processing: the base training set and the few-shot support sets of novel classes are analyzed and augmented; (b) Hybrid segmentation structure; Multiple base learners and a modified Projection onto Orthogonal Prototypes (POP) network are combined to enhance the base-class recognition and to dig novel classes from insufficient labels data; (c) Ultimate fusion: the semantic segmentation results of the base learners and POP network are reasonably fused. The proposed framework has won first place in the leaderboard of the OpenEarthMap Land Cover Mapping Few-Shot Challenge. Experiments demonstrate the superiority of the framework for automatically updating novel land-cover classes with limited labeled data.
Learning without Exact Guidance: Updating Large-scale High-resolution Land Cover Maps from Low-resolution Historical Labels
Mar 08, 2024Large-scale high-resolution (HR) land-cover mapping is a vital task to survey the Earth's surface and resolve many challenges facing humanity. However, it is still a non-trivial task hindered by complex ground details, various landforms, and the scarcity of accurate training labels over a wide-span geographic area. In this paper, we propose an efficient, weakly supervised framework (Paraformer) to guide large-scale HR land-cover mapping with easy-access historical land-cover data of low resolution (LR). Specifically, existing land-cover mapping approaches reveal the dominance of CNNs in preserving local ground details but still suffer from insufficient global modeling in various landforms. Therefore, we design a parallel CNN-Transformer feature extractor in Paraformer, consisting of a downsampling-free CNN branch and a Transformer branch, to jointly capture local and global contextual information. Besides, facing the spatial mismatch of training data, a pseudo-label-assisted training (PLAT) module is adopted to reasonably refine LR labels for weakly supervised semantic segmentation of HR images. Experiments on two large-scale datasets demonstrate the superiority of Paraformer over other state-of-the-art methods for automatically updating HR land-cover maps from LR historical labels.
Cross-level Attention with Overlapped Windows for Camouflaged Object Detection
Nov 28, 2023Camouflaged objects adaptively fit their color and texture with the environment, which makes them indistinguishable from the surroundings. Current methods revealed that high-level semantic features can highlight the differences between camouflaged objects and the backgrounds. Consequently, they integrate high-level semantic features with low-level detailed features for accurate camouflaged object detection (COD). Unlike previous designs for multi-level feature fusion, we state that enhancing low-level features is more impending for COD. In this paper, we propose an overlapped window cross-level attention (OWinCA) to achieve the low-level feature enhancement guided by the highest-level features. By sliding an aligned window pair on both the highest- and low-level feature maps, the high-level semantics are explicitly integrated into the low-level details via cross-level attention. Additionally, it employs an overlapped window partition strategy to alleviate the incoherence among windows, which prevents the loss of global information. These adoptions enable the proposed OWinCA to enhance low-level features by promoting the separability of camouflaged objects. The associated proposed OWinCANet fuses these enhanced multi-level features by simple convolution operation to achieve the final COD. Experiments conducted on three large-scale COD datasets demonstrate that our OWinCANet significantly surpasses the current state-of-the-art COD methods.
Building Extraction from Remote Sensing Images via an Uncertainty-Aware Network
Jul 23, 2023



Building extraction aims to segment building pixels from remote sensing images and plays an essential role in many applications, such as city planning and urban dynamic monitoring. Over the past few years, deep learning methods with encoder-decoder architectures have achieved remarkable performance due to their powerful feature representation capability. Nevertheless, due to the varying scales and styles of buildings, conventional deep learning models always suffer from uncertain predictions and cannot accurately distinguish the complete footprints of the building from the complex distribution of ground objects, leading to a large degree of omission and commission. In this paper, we realize the importance of uncertain prediction and propose a novel and straightforward Uncertainty-Aware Network (UANet) to alleviate this problem. To verify the performance of our proposed UANet, we conduct extensive experiments on three public building datasets, including the WHU building dataset, the Massachusetts building dataset, and the Inria aerial image dataset. Results demonstrate that the proposed UANet outperforms other state-of-the-art algorithms by a large margin.
Degradation-Noise-Aware Deep Unfolding Transformer for Hyperspectral Image Denoising
May 06, 2023



Hyperspectral imaging (HI) has emerged as a powerful tool in diverse fields such as medical diagnosis, industrial inspection, and agriculture, owing to its ability to detect subtle differences in physical properties through high spectral resolution. However, hyperspectral images (HSIs) are often quite noisy because of narrow band spectral filtering. To reduce the noise in HSI data cubes, both model-driven and learning-based denoising algorithms have been proposed. However, model-based approaches rely on hand-crafted priors and hyperparameters, while learning-based methods are incapable of estimating the inherent degradation patterns and noise distributions in the imaging procedure, which could inform supervised learning. Secondly, learning-based algorithms predominantly rely on CNN and fail to capture long-range dependencies, resulting in limited interpretability. This paper proposes a Degradation-Noise-Aware Unfolding Network (DNA-Net) that addresses these issues. Firstly, DNA-Net models sparse noise, Gaussian noise, and explicitly represent image prior using transformer. Then the model is unfolded into an end-to-end network, the hyperparameters within the model are estimated from the noisy HSI and degradation model and utilizes them to control each iteration. Additionally, we introduce a novel U-Shaped Local-Non-local-Spectral Transformer (U-LNSA) that captures spectral correlation, local contents, and non-local dependencies simultaneously. By integrating U-LNSA into DNA-Net, we present the first Transformer-based deep unfolding HSI denoising method. Experimental results show that DNA-Net outperforms state-of-the-art methods, and the modeling of noise distributions helps in cases with heavy noise.
MSFA-Frequency-Aware Transformer for Hyperspectral Images Demosaicing
Mar 23, 2023



Hyperspectral imaging systems that use multispectral filter arrays (MSFA) capture only one spectral component in each pixel. Hyperspectral demosaicing is used to recover the non-measured components. While deep learning methods have shown promise in this area, they still suffer from several challenges, including limited modeling of non-local dependencies, lack of consideration of the periodic MSFA pattern that could be linked to periodic artifacts, and difficulty in recovering high-frequency details. To address these challenges, this paper proposes a novel de-mosaicing framework, the MSFA-frequency-aware Transformer network (FDM-Net). FDM-Net integrates a novel MSFA-frequency-aware multi-head self-attention mechanism (MaFormer) and a filter-based Fourier zero-padding method to reconstruct high pass components with greater difficulty and low pass components with relative ease, separately. The advantage of Maformer is that it can leverage the MSFA information and non-local dependencies present in the data. Additionally, we introduce a joint spatial and frequency loss to transfer MSFA information and enhance training on frequency components that are hard to recover. Our experimental results demonstrate that FDM-Net outperforms state-of-the-art methods with 6dB PSNR, and reconstructs high-fidelity details successfully.
National-scale 1-m resolution land-cover mapping for the entire China based on a low-cost solution and open-access data
Mar 09, 2023
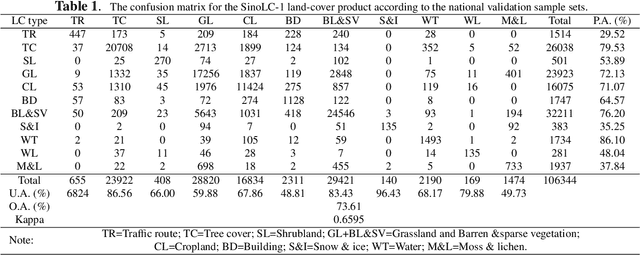


Nowadays, many large-scale land-cover (LC) products have been released, however, current LC products for China either lack a fine resolution or nationwide coverage. With the rapid urbanization of China, there is an urgent need for creating a very-high-resolution (VHR) national-scale LC map for China. In this study, a novel 1-m resolution LC map of China covering $9,600,000 km^2$, called SinoLC-1, was produced by using a deep learning framework and multi-source open-access data. To efficiently generate the VHR national-scale LC map, firstly, the reliable LC labels were collected from three 10-m LC products and Open Street Map data. Secondly, the collected 10-m labels and 1-m Google Earth imagery were utilized in the proposed low-to-high (L2H) framework for training. With weak and self-supervised strategies, the L2H framework resolves the label noise brought by the mismatched resolution between training pairs and produces VHR results. Lastly, we compare the SinoLC-1 with five widely used products and validate it with a sample set including 10,6852 points and a statistical report collected from the government. The results show the SinoLC-1 achieved an OA of 74\% and a Kappa of 0.65. Moreover, as the first 1-m national-scale LC map for China, the SinoLC-1 shows overall acceptable results with the finest landscape details.