 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying every building's function in large-scale urban areas with multi-modality remote-sensing data
May 08, 2024
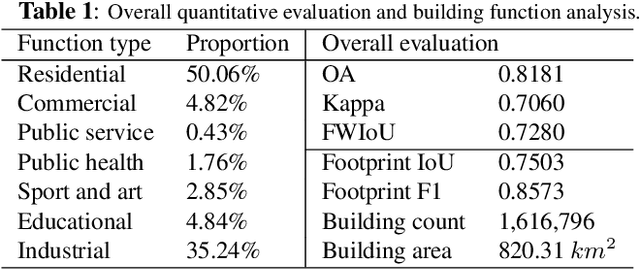

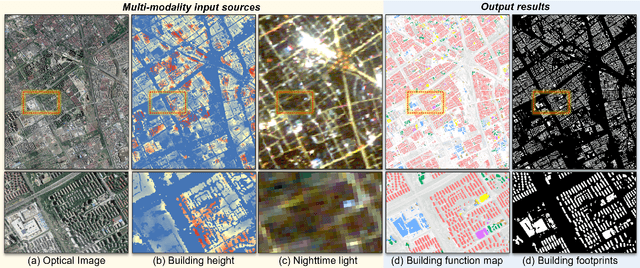
Buildings, as fundamental man-made structures in urban environments, serve as crucial indicators for understanding various city function zones. Rapid urbanization has raised an urgent need for efficiently surveying building footprints and functions. In this study, we proposed a semi-supervised framework to identify every building's function in large-scale urban areas with multi-modality remote-sensing data. In detail, optical images, building height, and nighttime-light data are collected to describe the morphological attributes of buildings. Then, the area of interest (AOI) and building masks from the volunteered geographic information (VGI) data are collected to form sparsely labeled samples. Furthermore, the multi-modality data and weak labels are utilized to train a segmentation model with a semi-supervised strategy. Finally, results are evaluated by 20,000 validation points and statistical survey reports from the government. The evaluations reveal that the produced function maps achieve an OA of 82% and Kappa of 71% among 1,616,796 buildings in Shanghai, China. This study has the potential to support large-scale urban management and sustainable urban development. All collected data and produced maps are open access at https://github.com/LiZhuoHong/BuildingMap.
Generalized Few-Shot Meets Remote Sensing: Discovering Novel Classes in Land Cover Mapping via Hybrid Semantic Segmentation Framework
Apr 19, 2024Land-cover mapping is one of the vital applications in Earth observation, aiming at classifying each pixel's land-cover type of remote-sensing images. As natural and human activities change the landscape, the land-cover map needs to be rapidly updated. However, discovering newly appeared land-cover types in existing classification systems is still a non-trivial task hindered by various scales of complex land objects and insufficient labeled data over a wide-span geographic area. In this paper, we propose a generalized few-shot segmentation-based framework, named SegLand, to update novel classes in high-resolution land-cover mapping. Specifically, the proposed framework is designed in three parts: (a) Data pre-processing: the base training set and the few-shot support sets of novel classes are analyzed and augmented; (b) Hybrid segmentation structure; Multiple base learners and a modified Projection onto Orthogonal Prototypes (POP) network are combined to enhance the base-class recognition and to dig novel classes from insufficient labels data; (c) Ultimate fusion: the semantic segmentation results of the base learners and POP network are reasonably fused. The proposed framework has won first place in the leaderboard of the OpenEarthMap Land Cover Mapping Few-Shot Challenge. Experiments demonstrate the superiority of the framework for automatically updating novel land-cover classes with limited labeled data.
Learning without Exact Guidance: Updating Large-scale High-resolution Land Cover Maps from Low-resolution Historical Labels
Mar 08, 2024Large-scale high-resolution (HR) land-cover mapping is a vital task to survey the Earth's surface and resolve many challenges facing humanity. However, it is still a non-trivial task hindered by complex ground details, various landforms, and the scarcity of accurate training labels over a wide-span geographic area. In this paper, we propose an efficient, weakly supervised framework (Paraformer) to guide large-scale HR land-cover mapping with easy-access historical land-cover data of low resolution (LR). Specifically, existing land-cover mapping approaches reveal the dominance of CNNs in preserving local ground details but still suffer from insufficient global modeling in various landforms. Therefore, we design a parallel CNN-Transformer feature extractor in Paraformer, consisting of a downsampling-free CNN branch and a Transformer branch, to jointly capture local and global contextual information. Besides, facing the spatial mismatch of training data, a pseudo-label-assisted training (PLAT) module is adopted to reasonably refine LR labels for weakly supervised semantic segmentation of HR images. Experiments on two large-scale datasets demonstrate the superiority of Paraformer over other state-of-the-art methods for automatically updating HR land-cover maps from LR historical labels.
Cross-level Attention with Overlapped Windows for Camouflaged Object Detection
Nov 28, 2023Camouflaged objects adaptively fit their color and texture with the environment, which makes them indistinguishable from the surroundings. Current methods revealed that high-level semantic features can highlight the differences between camouflaged objects and the backgrounds. Consequently, they integrate high-level semantic features with low-level detailed features for accurate camouflaged object detection (COD). Unlike previous designs for multi-level feature fusion, we state that enhancing low-level features is more impending for COD. In this paper, we propose an overlapped window cross-level attention (OWinCA) to achieve the low-level feature enhancement guided by the highest-level features. By sliding an aligned window pair on both the highest- and low-level feature maps, the high-level semantics are explicitly integrated into the low-level details via cross-level attention. Additionally, it employs an overlapped window partition strategy to alleviate the incoherence among windows, which prevents the loss of global information. These adoptions enable the proposed OWinCA to enhance low-level features by promoting the separability of camouflaged objects. The associated proposed OWinCANet fuses these enhanced multi-level features by simple convolution operation to achieve the final COD. Experiments conducted on three large-scale COD datasets demonstrate that our OWinCANet significantly surpasses the current state-of-the-art COD methods.
National-scale 1-m resolution land-cover mapping for the entire China based on a low-cost solution and open-access data
Mar 09, 2023
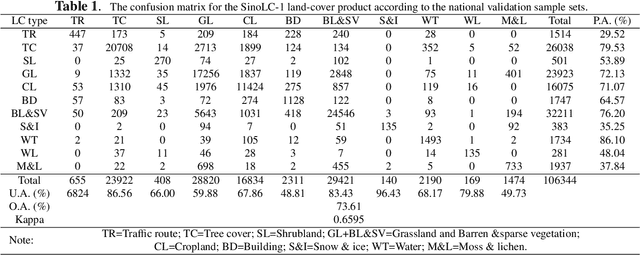


Nowadays, many large-scale land-cover (LC) products have been released, however, current LC products for China either lack a fine resolution or nationwide coverage. With the rapid urbanization of China, there is an urgent need for creating a very-high-resolution (VHR) national-scale LC map for China. In this study, a novel 1-m resolution LC map of China covering $9,600,000 km^2$, called SinoLC-1, was produced by using a deep learning framework and multi-source open-access data. To efficiently generate the VHR national-scale LC map, firstly, the reliable LC labels were collected from three 10-m LC products and Open Street Map data. Secondly, the collected 10-m labels and 1-m Google Earth imagery were utilized in the proposed low-to-high (L2H) framework for training. With weak and self-supervised strategies, the L2H framework resolves the label noise brought by the mismatched resolution between training pairs and produces VHR results. Lastly, we compare the SinoLC-1 with five widely used products and validate it with a sample set including 10,6852 points and a statistical report collected from the government. The results show the SinoLC-1 achieved an OA of 74\% and a Kappa of 0.65. Moreover, as the first 1-m national-scale LC map for China, the SinoLC-1 shows overall acceptable results with the finest landscape details.