 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Code LLMs with Reinforcement Learning in Code Generation
Dec 29, 2024



With the rapid evolution of large language models (LLM), reinforcement learning (RL) has emerged as a pivotal technique for code generation and optimization in various domains. This paper presents a systematic survey of the application of RL in code optimization and generation, highlighting its role in enhancing compiler optimization, resource allocation, and the development of frameworks and tools. Subsequent sections first delve into the intricate processes of compiler optimization, where RL algorithms are leveraged to improve efficiency and resource utilization. The discussion then progresses to the function of RL in resource allocation, emphasizing register allocation and system optimization. We also explore the burgeoning role of frameworks and tools in code generation, examining how RL can be integrated to bolster their capabilities. This survey aims to serve as a comprehensive resource for researchers and practitioners interested in harnessing the power of RL to advance code generation and optimization techniques.
Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage
Nov 02, 2024



Despite the impressive capabilities of large language models (LLMs), they currently exhibit two primary limitations, \textbf{\uppercase\expandafter{\romannumeral 1}}: They struggle to \textbf{autonomously solve the real world engineering problem}. \textbf{\uppercase\expandafter{\romannumeral 2}}: They remain \textbf{challenged in reasoning through complex logic problems}. To address these challenges, we developed the \textsc{Infant Agent}, integrating task-aware functions, operators, a hierarchical management system, and a memory retrieval mechanism. Together, these components enable large language models to sustain extended reasoning processes and handle complex, multi-step tasks efficiently, all while significantly reducing API costs. Using the \textsc{Infant Agent}, GPT-4o's accuracy on the SWE-bench-lite dataset rises from $\mathbf{0.33\%}$ to $\mathbf{30\%}$, and in the AIME-2024 mathematics competition, it increases GPT-4o's accuracy from $\mathbf{13.3\%}$ to $\mathbf{37\%}$.
FALCON: Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization system
Oct 28, 2024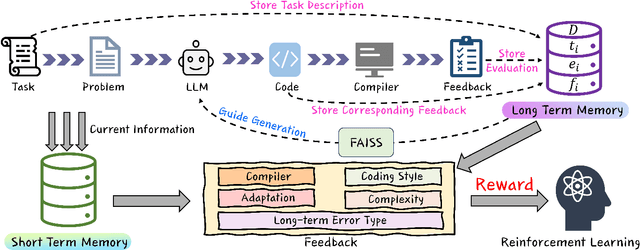
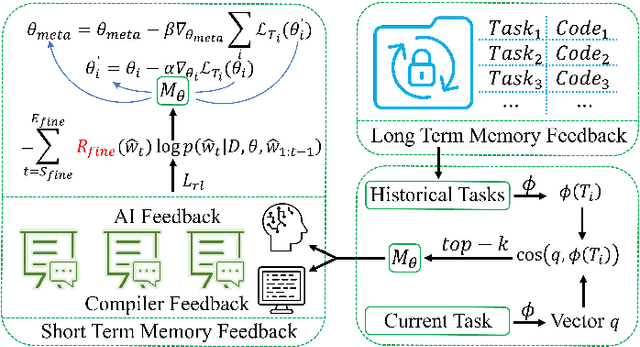
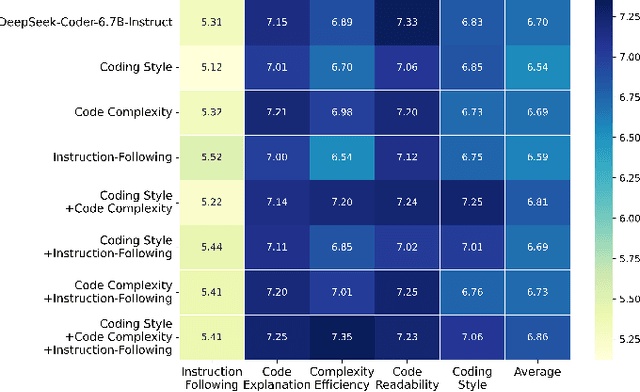
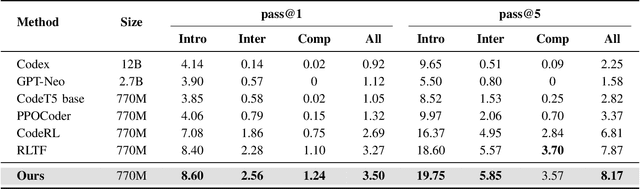
Recently, large language models (LLMs) have achieved significant progress in automated code generation. Despite their strong instruction-following capabilities, these models frequently struggled to align with user intent in coding scenarios. In particular, they were hampered by datasets that lacked diversity and failed to address specialized tasks or edge cases. Furthermore, challenges in supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) led to failures in generating precise, human-intent-aligned code. To tackle these challenges and improve the code generation performance for automated programming systems, we propose Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization (i.e., FALCON). FALCON is structured into two hierarchical levels. From the global level, long-term memory improves code quality by retaining and applying learned knowledge. At the local level, short-term memory allows for the incorporation of immediate feedback from compilers and AI systems. Additionally, we introduce meta-reinforcement learning with feedback rewards to solve the global-local bi-level optimization problem and enhance the model's adaptability across diverse code generation tasks. Extensive experiments demonstrate that our technique achieves state-of-the-art performance, leading other reinforcement learning methods by more than 4.5 percentage points on the MBPP benchmark and 6.1 percentage points on the Humaneval benchmark. The open-sourced code is publicly available at https://github.com/titurte/FALCON.
AutoCoder: Enhancing Code Large Language Model with \textsc{AIEV-Instruct}
May 23, 2024



We introduce AutoCoder, the first Large Language Model to surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval benchmark test ($\mathbf{90.9\%}$ vs. $\mathbf{90.2\%}$). In addition, AutoCoder offers a more versatile code interpreter compared to GPT-4 Turbo and GPT-4o. It's code interpreter can install external packages instead of limiting to built-in packages. AutoCoder's training data is a multi-turn dialogue dataset created by a system combining agent interaction and external code execution verification, a method we term \textbf{\textsc{AIEV-Instruct}} (Instruction Tuning with Agent-Interaction and Execution-Verified). Compared to previous large-scale code dataset generation methods, \textsc{AIEV-Instruct} reduces dependence on proprietary large models and provides execution-validated code dataset. The code and the demo video is available in \url{https://github.com/bin123apple/AutoCoder}.