 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALCON: Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization system
Paper and Code
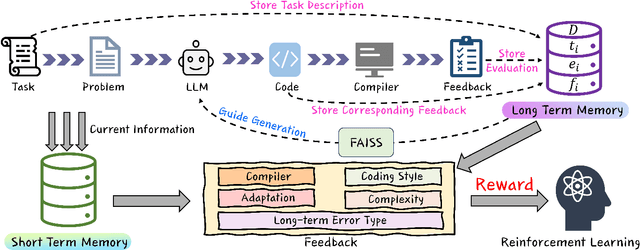
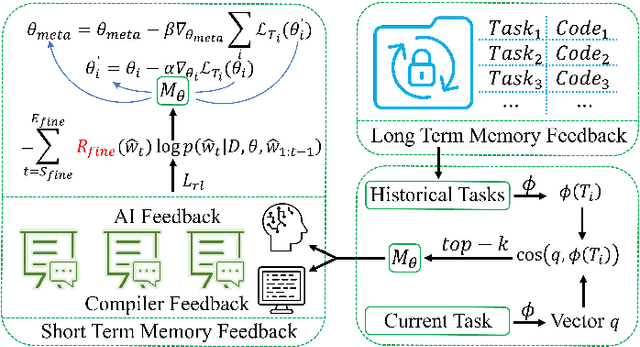
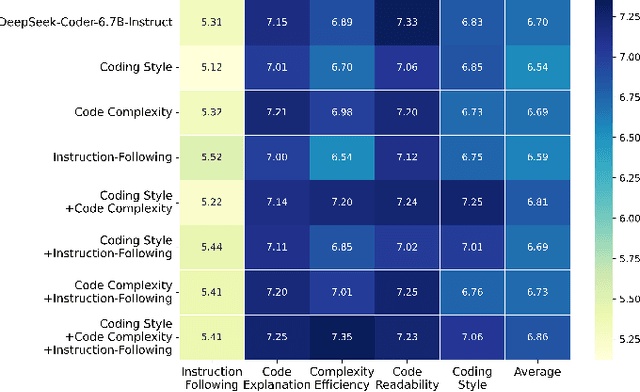
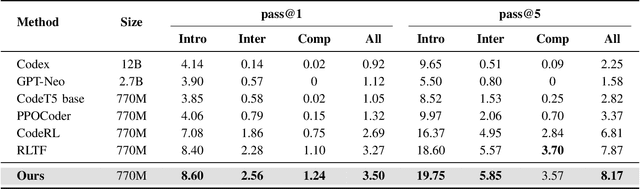
Recently, large language models (LLMs) have achieved significant progress in automated code generation. Despite their strong instruction-following capabilities, these models frequently struggled to align with user intent in coding scenarios. In particular, they were hampered by datasets that lacked diversity and failed to address specialized tasks or edge cases. Furthermore, challenges in supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) led to failures in generating precise, human-intent-aligned code. To tackle these challenges and improve the code generation performance for automated programming systems, we propose Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization (i.e., FALCON). FALCON is structured into two hierarchical levels. From the global level, long-term memory improves code quality by retaining and applying learned knowledge. At the local level, short-term memory allows for the incorporation of immediate feedback from compilers and AI systems. Additionally, we introduce meta-reinforcement learning with feedback rewards to solve the global-local bi-level optimization problem and enhance the model's adaptability across diverse code generation tasks. Extensive experiments demonstrate that our technique achieves state-of-the-art performance, leading other reinforcement learning methods by more than 4.5 percentage points on the MBPP benchmark and 6.1 percentage points on the Humaneval benchmark. The open-sourced code is publicly available at https://github.com/titurte/FALCON.