 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Population-Based Architectures for Neural Combinatorial Optimization
Jan 13, 2026Neural Combinatorial Optimization (NCO) has mostly focused on learning policies, typically neural networks, that operate on a single candidate solution at a time, either by constructing one from scratch or iteratively improving it. In contrast, decades of work in metaheuristics have shown that maintaining and evolving populations of solutions improves robustness and exploration, and often leads to stronger performance. To close this gap, we study how to make NCO explicitly population-based by learning policies that act on sets of candidate solutions. We first propose a simple taxonomy of population awareness levels and use it to highlight two key design challenges: (i) how to represent a whole population inside a neural network, and (ii) how to learn population dynamics that balance intensification (generating good solutions) and diversification (maintaining variety). We make these ideas concrete with two complementary tools: one that improves existing solutions using information shared across the whole population, and the other generates new candidate solutions that explicitly balance being high-quality with diversity. Experimental results on Maximum Cut and Maximum Independent Set indicate that incorporating population structure is advantageous for learned optimization methods and opens new connections between NCO and classical population-based search.
MARCO: A Memory-Augmented Reinforcement Framework for Combinatorial Optimization
Aug 05, 2024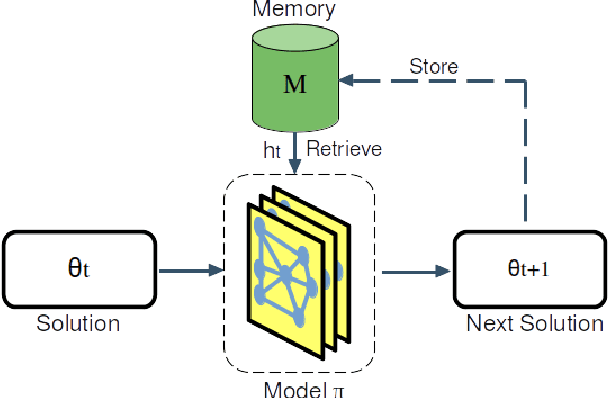

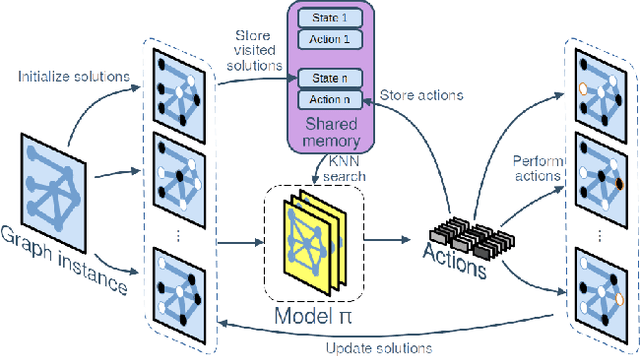
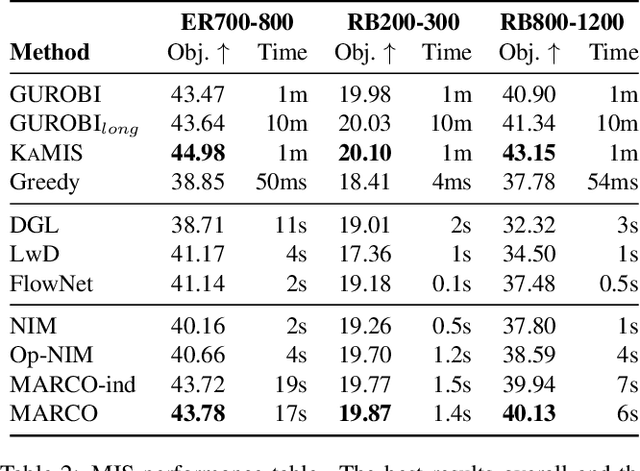
Neural Combinatorial Optimization (NCO) is an emerging domain where deep learning techniques are employed to address combinatorial optimization problems as a standalone solver. Despite their potential, existing NCO methods often suffer from inefficient search space exploration, frequently leading to local optima entrapment or redundant exploration of previously visited states. This paper introduces a versatile framework, referred to as Memory-Augmented Reinforcement for Combinatorial Optimization (MARCO), that can be used to enhance both constructive and improvement methods in NCO through an innovative memory module. MARCO stores data collected throughout the optimization trajectory and retrieves contextually relevant information at each state. This way, the search is guided by two competing criteria: making the best decision in terms of the quality of the solution and avoiding revisiting already explored solutions. This approach promotes a more efficient use of the available optimization budget. Moreover, thanks to the parallel nature of NCO models, several search threads can run simultaneously, all sharing the same memory module, enabling an efficient collaborative exploration. Empirical evaluations, carried out on the maximum cut, maximum independent set and travelling salesman problems, reveal that the memory module effectively increases the exploration, enabling the model to discover diverse, higher-quality solutions. MARCO achieves good performance in a low computational cost, establishing a promising new direction in the field of NCO.
Light up that Droid! On the Effectiveness of Static Analysis Features against App Obfuscation for Android Malware Detection
Oct 24, 2023



Malware authors have seen obfuscation as the mean to bypass malware detectors based on static analysis features. For Android, several studies have confirmed that many anti-malware products are easily evaded with simple program transformations. As opposed to these works, ML detection proposals for Android leveraging static analysis features have also been proposed as obfuscation-resilient. Therefore, it needs to be determined to what extent the use of a specific obfuscation strategy or tool poses a risk for the validity of ML malware detectors for Android based on static analysis features. To shed some light in this regard, in this article we assess the impact of specific obfuscation techniques on common features extracted using static analysis and determine whether the changes are significant enough to undermine the effectiveness of ML malware detectors that rely on these features. The experimental results suggest that obfuscation techniques affect all static analysis features to varying degrees across different tools. However, certain features retain their validity for ML malware detection even in the presence of obfuscation. Based on these findings, we propose a ML malware detector for Android that is robust against obfuscation and outperforms current state-of-the-art detectors.
Neuroevolutionary algorithms driven by neuron coverage metrics for semi-supervised classification
Mar 05, 2023



In some machine learning applications the availability of labeled instances for supervised classification is limited while unlabeled instances are abundant. Semi-supervised learning algorithms deal with these scenarios and attempt to exploit the information contained in the unlabeled examples. In this paper, we address the question of how to evolve neural networks for semi-supervised problems. We introduce neuroevolutionary approaches that exploit unlabeled instances by using neuron coverage metrics computed on the neural network architecture encoded by each candidate solution. Neuron coverage metrics resemble code coverage metrics used to test software, but are oriented to quantify how the different neural network components are covered by test instances. In our neuroevolutionary approach, we define fitness functions that combine classification accuracy computed on labeled examples and neuron coverage metrics evaluated using unlabeled examples. We assess the impact of these functions on semi-supervised problems with a varying amount of labeled instances. Our results show that the use of neuron coverage metrics helps neuroevolution to become less sensitive to the scarcity of labeled data, and can lead in some cases to a more robust generalization of the learned classifiers.
Neural Improvement Heuristics for Preference Ranking
Jun 01, 2022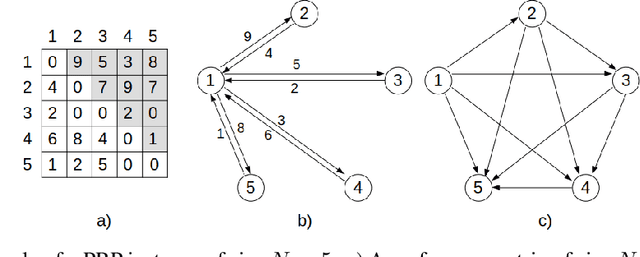
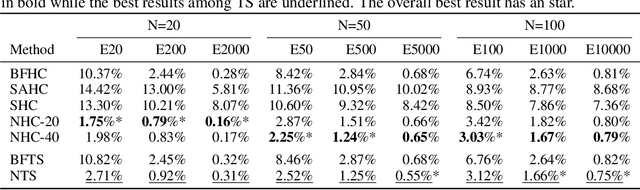
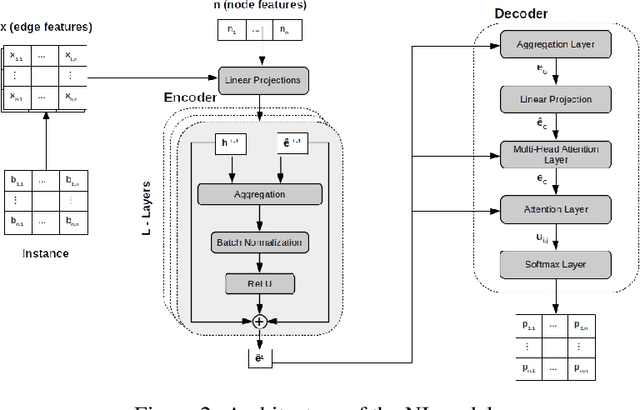
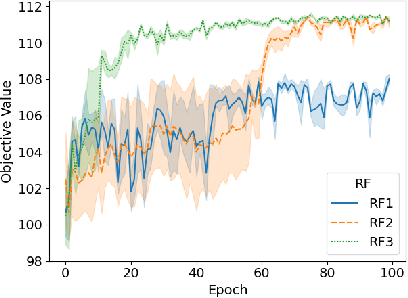
In recent years, Deep Learning based methods have been a revolution in the field of combinatorial optimization. They learn to approximate solutions and constitute an interesting choice when dealing with repetitive problems drawn from similar distributions. Most effort has been devoted to investigating neural constructive methods, while the works that propose neural models to iteratively improve a candidate solution are less frequent. In this paper, we present a Neural Improvement (NI) model for graph-based combinatorial problems that, given an instance and a candidate solution, encodes the problem information by means of edge features. Our model proposes a modification on the pairwise precedence of items to increase the quality of the solution. We demonstrate the practicality of the model by applying it as the building block of a Neural Hill Climber and other trajectory-based methods. The algorithms are used to solve the Preference Ranking Problem and results show that they outperform conventional alternatives in simulated and real-world data. Conducted experiments also reveal that the proposed model can be a milestone in the development of efficiently guided trajectory-based optimization algorithms.
Towards a Fair Comparison and Realistic Design and Evaluation Framework of Android Malware Detectors
May 25, 2022

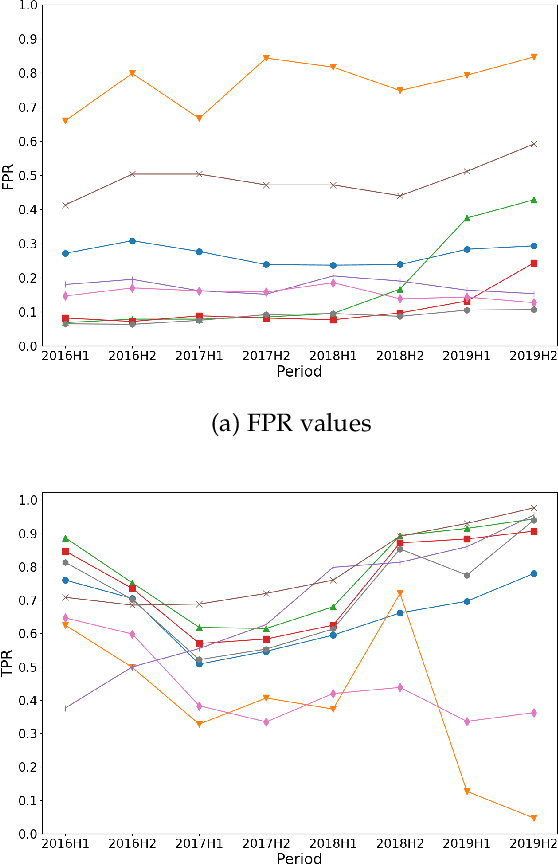
As in other cybersecurity areas, machine learning (ML) techniques have emerged as a promising solution to detect Android malware. In this sense, many proposals employing a variety of algorithms and feature sets have been presented to date, often reporting impresive detection performances. However, the lack of reproducibility and the absence of a standard evaluation framework make these proposals difficult to compare. In this paper, we perform an analysis of 10 influential research works on Android malware detection using a common evaluation framework. We have identified five factors that, if not taken into account when creating datasets and designing detectors, significantly affect the trained ML models and their performances. In particular, we analyze the effect of (1) the presence of duplicated samples, (2) label (goodware/greyware/malware) attribution, (3) class imbalance, (4) the presence of apps that use evasion techniques and, (5) the evolution of apps. Based on this extensive experimentation, we conclude that the studied ML-based detectors have been evaluated optimistically, which justifies the good published results. Our findings also highlight that it is imperative to generate realistic datasets, taking into account the factors mentioned above, to enable the design and evaluation of better solutions for Android malware detection.
Neural Combinatorial Optimization: a New Player in the Field
May 03, 2022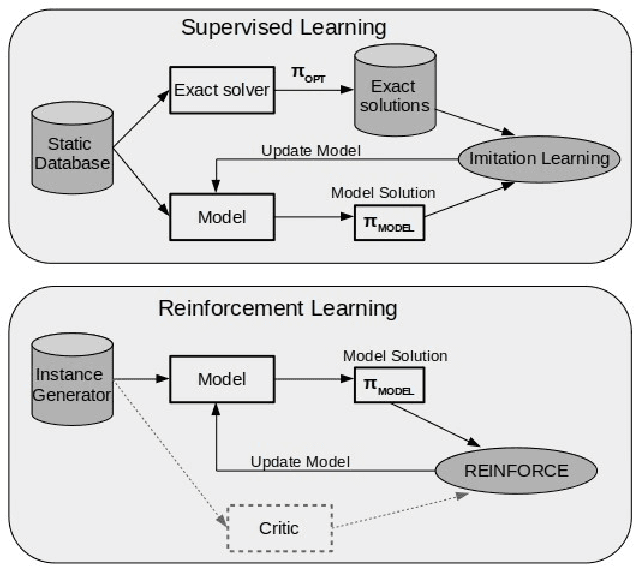
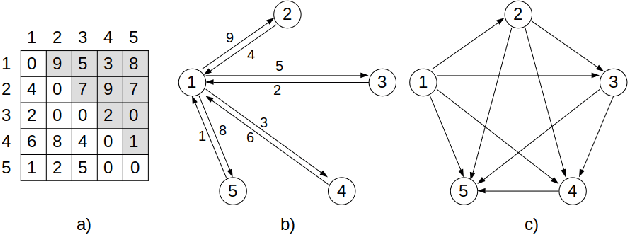
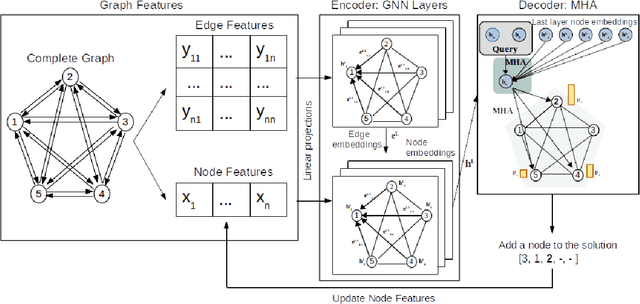
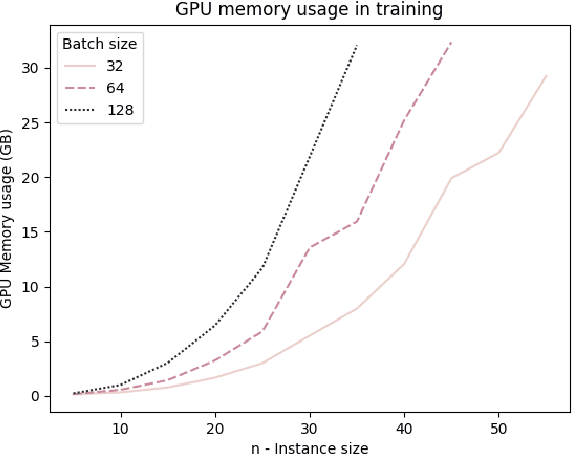
Neural Combinatorial Optimization attempts to learn good heuristics for solving a set of problems using Neural Network models and Reinforcement Learning. Recently, its good performance has encouraged many practitioners to develop neural architectures for a wide variety of combinatorial problems. However, the incorporation of such algorithms in the conventional optimization framework has raised many questions related to their performance and the experimental comparison with other methods such as exact algorithms, heuristics and metaheuristics. This paper presents a critical analysis on the incorporation of algorithms based on neural networks into the classical combinatorial optimization framework. Subsequently, a comprehensive study is carried out to analyse the fundamental aspects of such algorithms, including performance, transferability, computational cost and generalization to larger-sized instances. To that end, we select the Linear Ordering Problem as a case of study, an NP-hard problem, and develop a Neural Combinatorial Optimization model to optimize it. Finally, we discuss how the analysed aspects apply to a general learning framework, and suggest new directions for future work in the area of Neural Combinatorial Optimization algorithms.
Redefining Neural Architecture Search of Heterogeneous Multi-Network Models by Characterizing Variation Operators and Model Components
Jun 16, 2021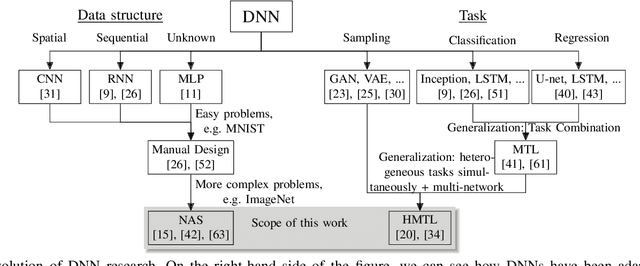
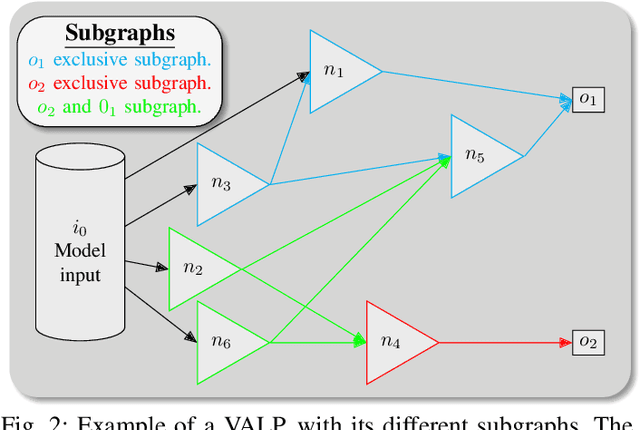
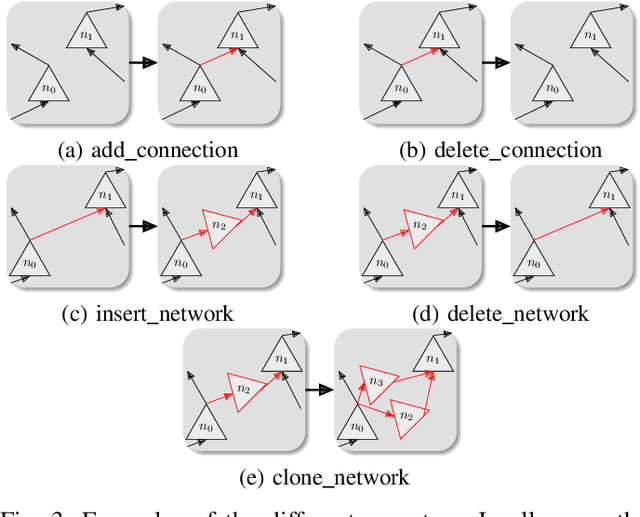
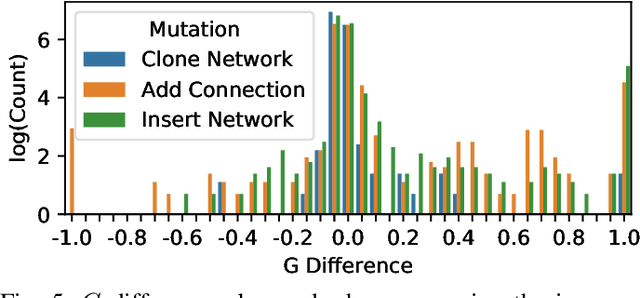
With neural architecture search methods gaining ground on manually designed deep neural networks -even more rapidly as model sophistication escalates-, the research trend shifts towards arranging different and often increasingly complex neural architecture search spaces. In this conjuncture, delineating algorithms which can efficiently explore these search spaces can result in a significant improvement over currently used methods, which, in general, randomly select the structural variation operator, hoping for a performance gain. In this paper, we investigate the effect of different variation operators in a complex domain, that of multi-network heterogeneous neural models. These models have an extensive and complex search space of structures as they require multiple sub-networks within the general model in order to answer to different output types. From that investigation, we extract a set of general guidelines, whose application is not limited to that particular type of model, and are useful to determine the direction in which an architecture optimization method could find the largest improvement. To deduce the set of guidelines, we characterize both the variation operators, according to their effect on the complexity and performance of the model; and the models, relying on diverse metrics which estimate the quality of the different parts composing it.
On the Exploitation of Neuroevolutionary Information: Analyzing the Past for a More Efficient Future
May 26, 2021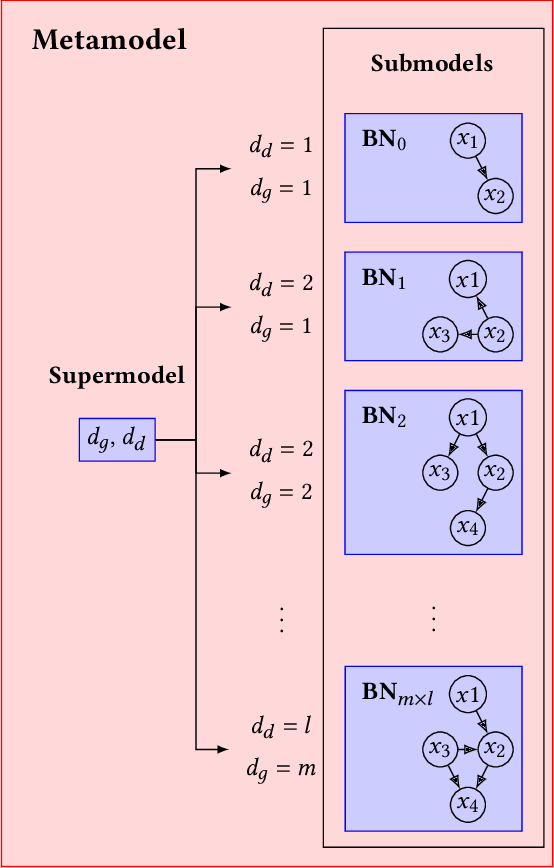
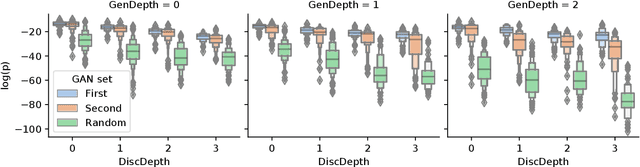
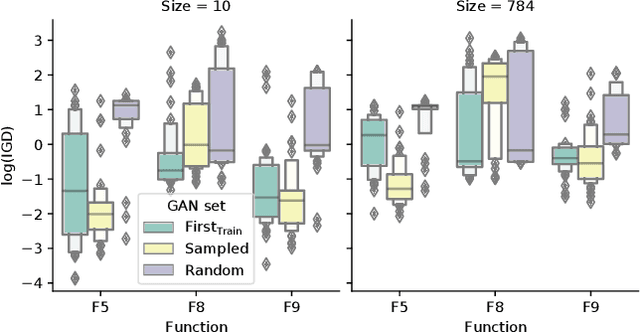
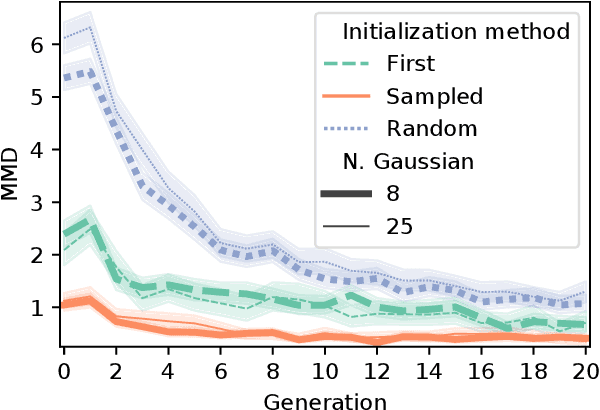
Neuroevolutionary algorithms, automatic searches of neural network structures by means of evolutionary techniques, are computationally costly procedures. In spite of this, due to the great performance provided by the architectures which are found, these methods are widely applied. The final outcome of neuroevolutionary processes is the best structure found during the search, and the rest of the procedure is commonly omitted in the literature. However, a good amount of residual information consisting of valuable knowledge that can be extracted is also produced during these searches. In this paper, we propose an approach that extracts this information from neuroevolutionary runs, and use it to build a metamodel that could positively impact future neural architecture searches. More specifically, by inspecting the best structures found during neuroevolutionary searches of generative adversarial networks with varying characteristics (e.g., based on dense or convolutional layers), we propose a Bayesian network-based model which can be used to either find strong neural structures right away, conveniently initialize different structural searches for different problems, or help future optimization of structures of any type to keep finding increasingly better structures where uninformed methods get stuck into local optima.
Survey of Network Intrusion Detection Methods from the Perspective of the Knowledge Discovery in Databases Process
Jan 27, 2020



The identification of cyberattacks which target information and communication systems has been a focus of the research community for years. Network intrusion detection is a complex problem which presents a diverse number of challenges. Many attacks currently remain undetected, while newer ones emerge due to the proliferation of connected devices and the evolution of communication technology. In this survey, we review the methods that have been applied to network data with the purpose of developing an intrusion detector, but contrary to previous reviews in the area, we analyze them from the perspective of the Knowledge Discovery in Databases (KDD) process. As such, we discuss the techniques used for the capture, preparation and transformation of the data, as well as, the data mining and evaluation methods. In addition, we also present the characteristics and motivations behind the use of each of these techniques and propose more adequate and up-to-date taxonomies and definitions for intrusion detectors based on the terminology used in the area of data mining and KDD. Special importance is given to the evaluation procedures followed to assess the different detectors, discussing their applicability in current real networks. Finally, as a result of this literature review, we investigate some open issues which will need to be considered for further research in the area of network security.