 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolutionary algorithms driven by neuron coverage metrics for semi-supervised classification
Paper and Code
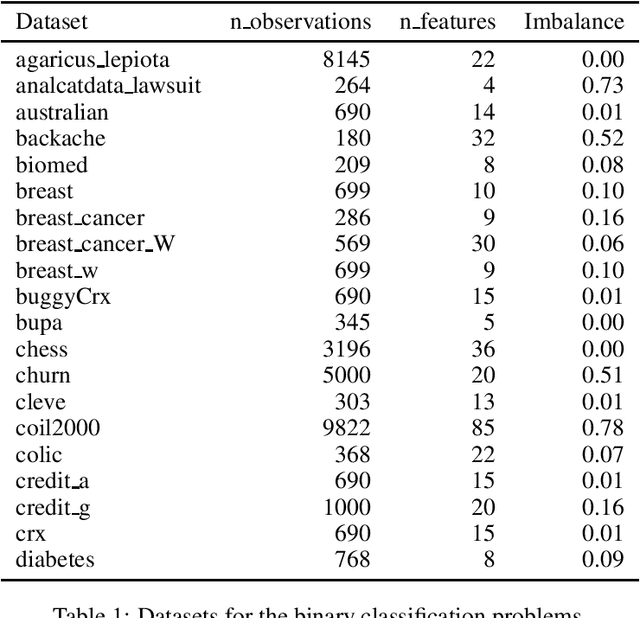



In some machine learning applications the availability of labeled instances for supervised classification is limited while unlabeled instances are abundant. Semi-supervised learning algorithms deal with these scenarios and attempt to exploit the information contained in the unlabeled examples. In this paper, we address the question of how to evolve neural networks for semi-supervised problems. We introduce neuroevolutionary approaches that exploit unlabeled instances by using neuron coverage metrics computed on the neural network architecture encoded by each candidate solution. Neuron coverage metrics resemble code coverage metrics used to test software, but are oriented to quantify how the different neural network components are covered by test instances. In our neuroevolutionary approach, we define fitness functions that combine classification accuracy computed on labeled examples and neuron coverage metrics evaluated using unlabeled examples. We assess the impact of these functions on semi-supervised problems with a varying amount of labeled instances. Our results show that the use of neuron coverage metrics helps neuroevolution to become less sensitive to the scarcity of labeled data, and can lead in some cases to a more robust generalization of the learned classifiers.