 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolutionary algorithms driven by neuron coverage metrics for semi-supervised classification
Mar 05, 2023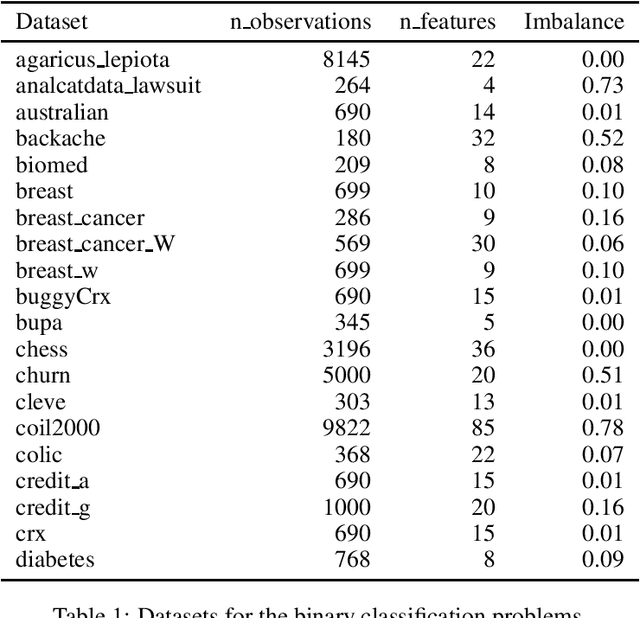



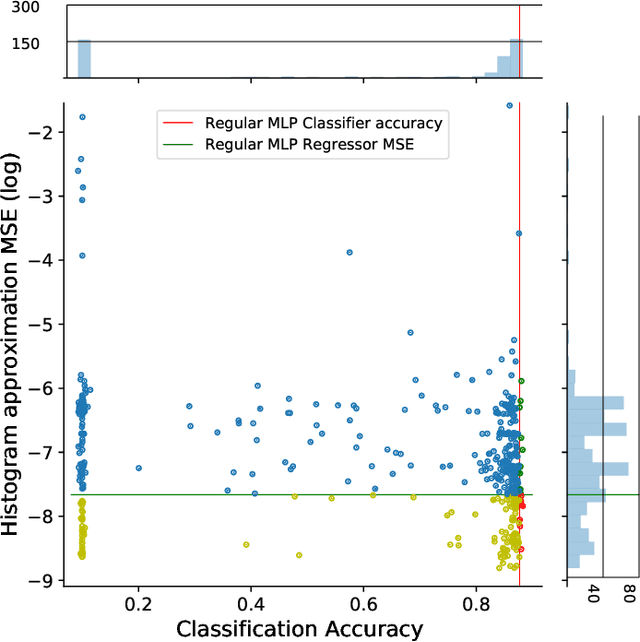
In some machine learning applications the availability of labeled instances for supervised classification is limited while unlabeled instances are abundant. Semi-supervised learning algorithms deal with these scenarios and attempt to exploit the information contained in the unlabeled examples. In this paper, we address the question of how to evolve neural networks for semi-supervised problems. We introduce neuroevolutionary approaches that exploit unlabeled instances by using neuron coverage metrics computed on the neural network architecture encoded by each candidate solution. Neuron coverage metrics resemble code coverage metrics used to test software, but are oriented to quantify how the different neural network components are covered by test instances. In our neuroevolutionary approach, we define fitness functions that combine classification accuracy computed on labeled examples and neuron coverage metrics evaluated using unlabeled examples. We assess the impact of these functions on semi-supervised problems with a varying amount of labeled instances. Our results show that the use of neuron coverage metrics helps neuroevolution to become less sensitive to the scarcity of labeled data, and can lead in some cases to a more robust generalization of the learned classifiers.
Redefining Neural Architecture Search of Heterogeneous Multi-Network Models by Characterizing Variation Operators and Model Components
Jun 16, 2021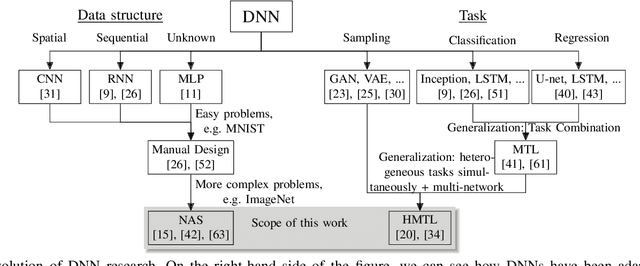
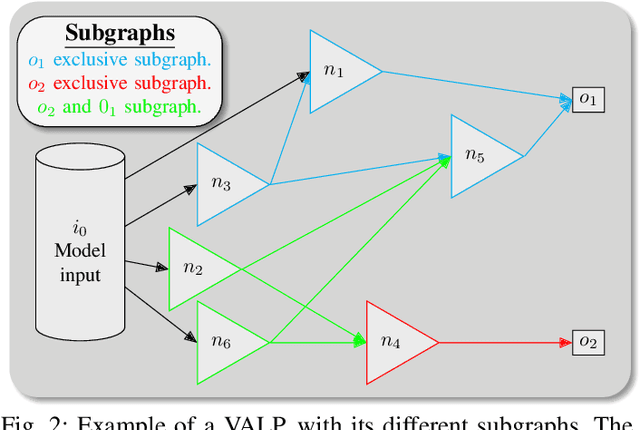
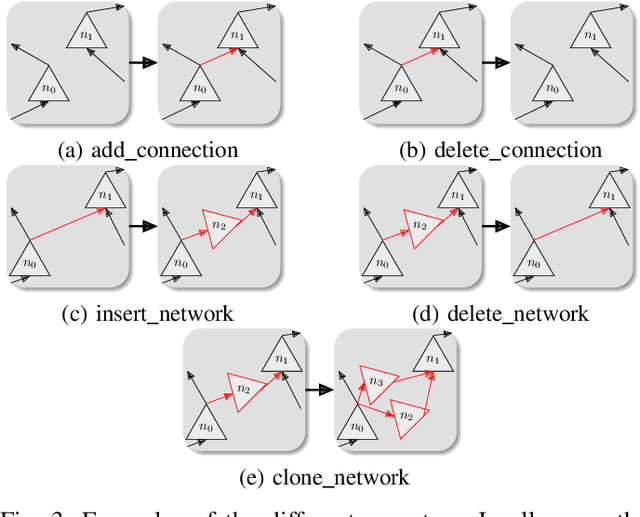
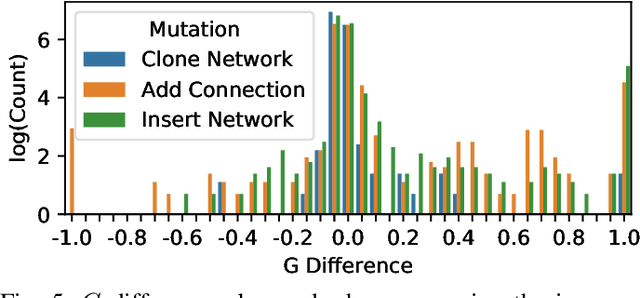
With neural architecture search methods gaining ground on manually designed deep neural networks -even more rapidly as model sophistication escalates-, the research trend shifts towards arranging different and often increasingly complex neural architecture search spaces. In this conjuncture, delineating algorithms which can efficiently explore these search spaces can result in a significant improvement over currently used methods, which, in general, randomly select the structural variation operator, hoping for a performance gain. In this paper, we investigate the effect of different variation operators in a complex domain, that of multi-network heterogeneous neural models. These models have an extensive and complex search space of structures as they require multiple sub-networks within the general model in order to answer to different output types. From that investigation, we extract a set of general guidelines, whose application is not limited to that particular type of model, and are useful to determine the direction in which an architecture optimization method could find the largest improvement. To deduce the set of guidelines, we characterize both the variation operators, according to their effect on the complexity and performance of the model; and the models, relying on diverse metrics which estimate the quality of the different parts composing it.
On the Exploitation of Neuroevolutionary Information: Analyzing the Past for a More Efficient Future
May 26, 2021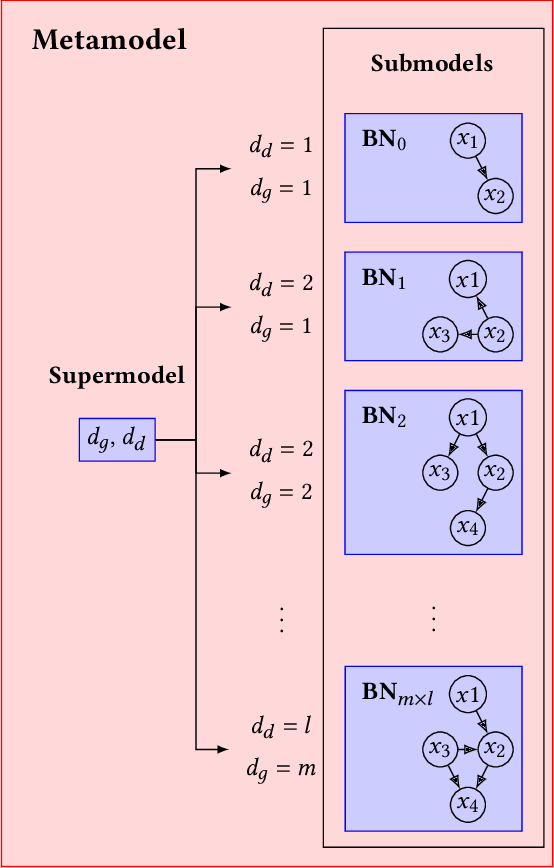
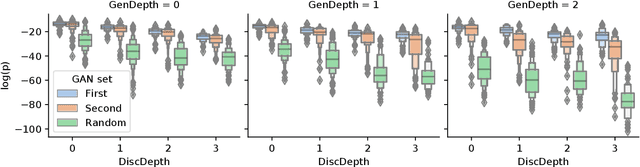
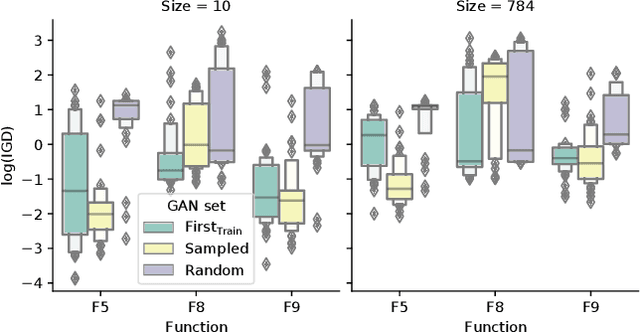
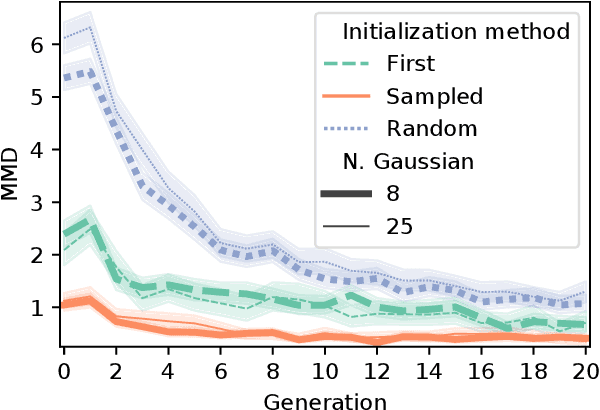
Neuroevolutionary algorithms, automatic searches of neural network structures by means of evolutionary techniques, are computationally costly procedures. In spite of this, due to the great performance provided by the architectures which are found, these methods are widely applied. The final outcome of neuroevolutionary processes is the best structure found during the search, and the rest of the procedure is commonly omitted in the literature. However, a good amount of residual information consisting of valuable knowledge that can be extracted is also produced during these searches. In this paper, we propose an approach that extracts this information from neuroevolutionary runs, and use it to build a metamodel that could positively impact future neural architecture searches. More specifically, by inspecting the best structures found during neuroevolutionary searches of generative adversarial networks with varying characteristics (e.g., based on dense or convolutional layers), we propose a Bayesian network-based model which can be used to either find strong neural structures right away, conveniently initialize different structural searches for different problems, or help future optimization of structures of any type to keep finding increasingly better structures where uninformed methods get stuck into local optima.
Towards automatic construction of multi-network models for heterogeneous multi-task learning
Mar 21, 2019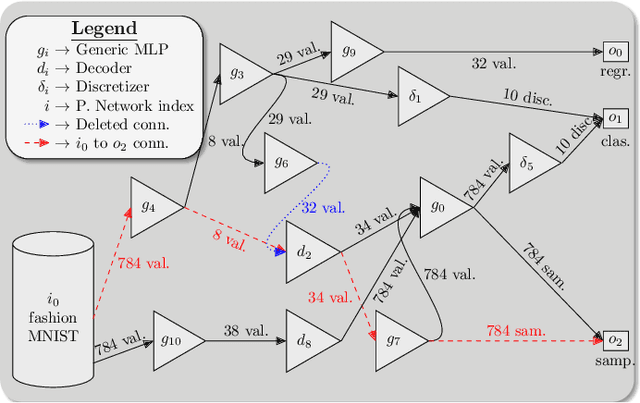
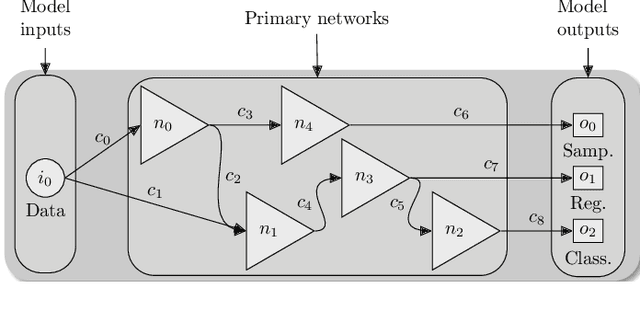
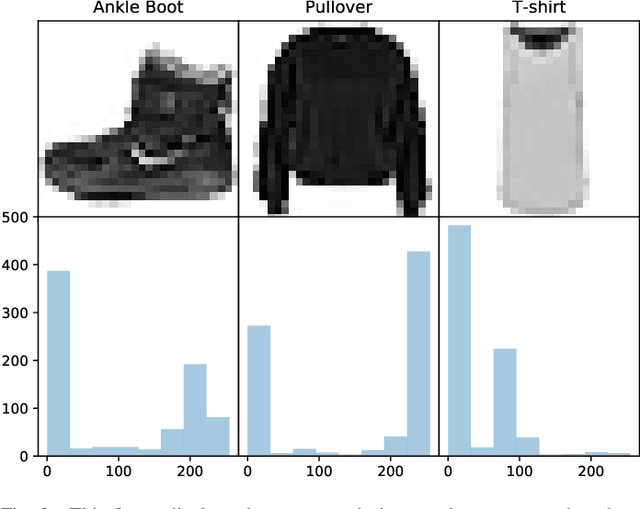
Multi-task learning, as it is understood nowadays, consists of using one single model to carry out several similar tasks. From classifying hand-written characters of different alphabets to figuring out how to play several Atari games using reinforcement learning, multi-task models have been able to widen their performance range across different tasks, although these tasks are usually of a similar nature. In this work, we attempt to widen this range even further, by including heterogeneous tasks in a single learning procedure. To do so, we firstly formally define a multi-network model, identifying the necessary components and characteristics to allow different adaptations of said model depending on the tasks it is required to fulfill. Secondly, employing the formal definition as a starting point, we develop an illustrative model example consisting of three different tasks (classification, regression and data sampling). The performance of this model implementation is then analyzed, showing its capabilities. Motivated by the results of the analysis, we enumerate a set of open challenges and future research lines over which the full potential of the proposed model definition can be exploited.
Towards a more efficient representation of imputation operators in TPOT
Jan 13, 2018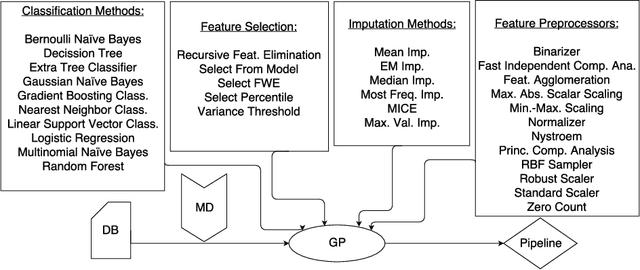

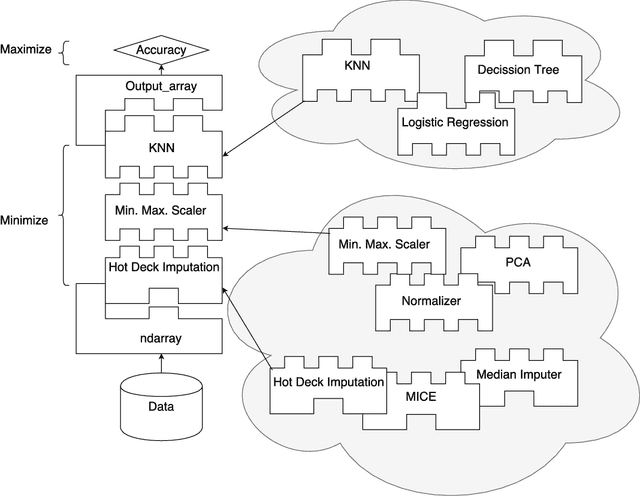
Automated Machine Learning encompasses a set of meta-algorithms intended to design and apply machine learning techniques (e.g., model selection, hyperparameter tuning, model assessment, etc.). TPOT, a software for optimizing machine learning pipelines based on genetic programming (GP), is a novel example of this kind of applications. Recently we have proposed a way to introduce imputation methods as part of TPOT. While our approach was able to deal with problems with missing data, it can produce a high number of unfeasible pipelines. In this paper we propose a strongly-typed-GP based approach that enforces constraint satisfaction by GP solutions. The enhancement we introduce is based on the redefinition of the operators and implicit enforcement of constraints in the generation of the GP trees. We evaluate the method to introduce imputation methods as part of TPOT. We show that the method can notably increase the efficiency of the GP search for optimal pipelines.
Evolving imputation strategies for missing data in classification problems with TPOT
Aug 14, 2017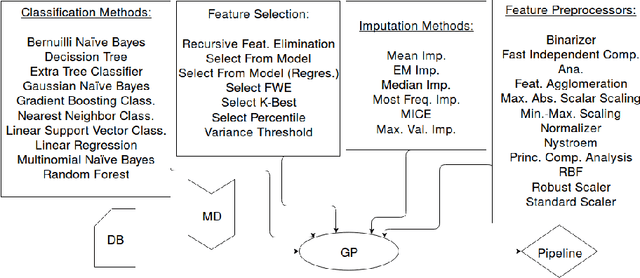

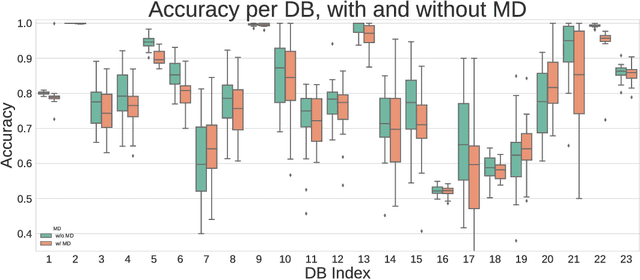
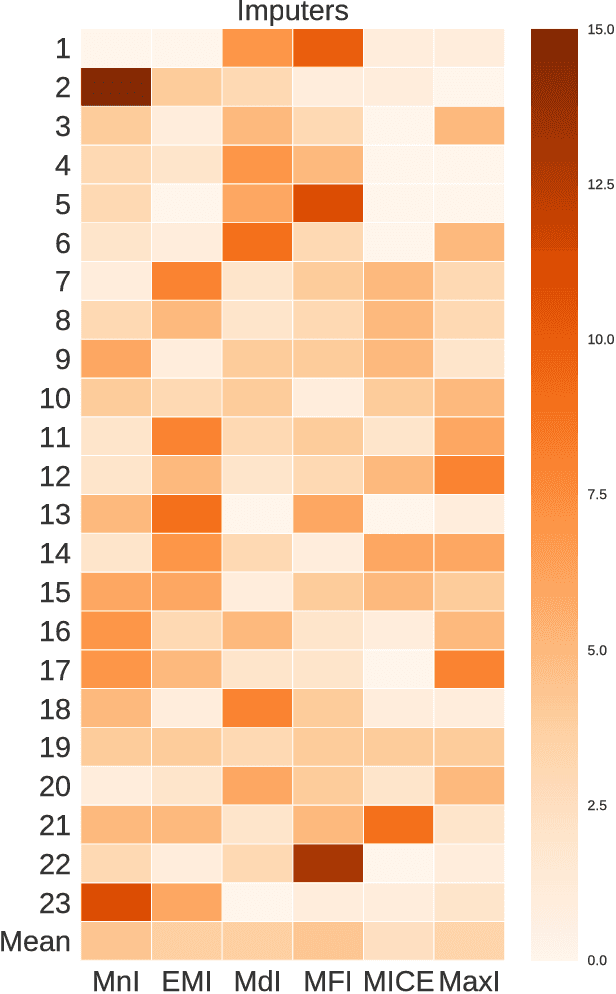
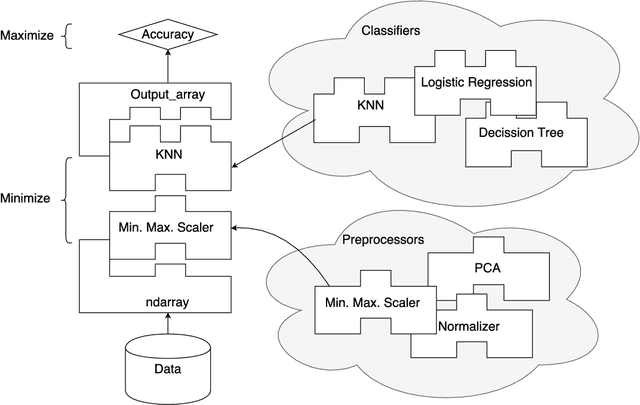
Missing data has a ubiquitous presence in real-life applications of machine learning techniques. Imputation methods are algorithms conceived for restoring missing values in the data, based on other entries in the database. The choice of the imputation method has an influence on the performance of the machine learning technique, e.g., it influences the accuracy of the classification algorithm applied to the data. Therefore, selecting and applying the right imputation method is important and usually requires a substantial amount of human intervention. In this paper we propose the use of genetic programming techniques to search for the right combination of imputation and classification algorithms. We build our work on the recently introduced Python-based TPOT library, and incorporate a heterogeneous set of imputation algorithms as part of the machine learning pipeline search. We show that genetic programming can automatically find increasingly better pipelines that include the most effective combinations of imputation methods, feature pre-processing, and classifiers for a variety of classification problems with missing data.