 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecNefLab: A Modular and Interpretable Simulation Framework for Decoded Neurofeedback
Nov 18, 2025Decoded Neurofeedback (DecNef) is a flourishing non-invasive approach to brain modulation with wide-ranging applications in neuromedicine and cognitive neuroscience. However, progress in DecNef research remains constrained by subject-dependent learning variability, reliance on indirect measures to quantify progress, and the high cost and time demands of experimentation. We present DecNefLab, a modular and interpretable simulation framework that formalizes DecNef as a machine learning problem. Beyond providing a virtual laboratory, DecNefLab enables researchers to model, analyze and understand neurofeedback dynamics. Using latent variable generative models as simulated participants, DecNefLab allows direct observation of internal cognitive states and systematic evaluation of how different protocol designs and subject characteristics influence learning. We demonstrate how this approach can (i) reproduce empirical phenomena of DecNef learning, (ii) identify conditions under which DecNef feedback fails to induce learning, and (iii) guide the design of more robust and reliable DecNef protocols in silico before human implementation. In summary, DecNefLab bridges computational modeling and cognitive neuroscience, offering a principled foundation for methodological innovation, robust protocol design, and ultimately, a deeper understanding of DecNef-based brain modulation.
Benchmarking MOEAs for solving continuous multi-objective RL problems
May 19, 2025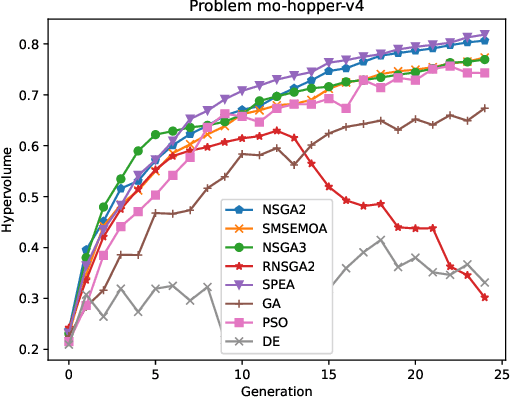

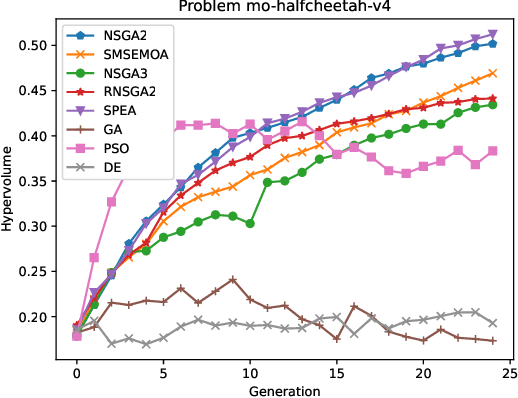

Multi-objective reinforcement learning (MORL) addresses the challenge of simultaneously optimizing multiple, often conflicting, rewards, moving beyond the single-reward focus of conventional reinforcement learning (RL). This approach is essential for applications where agents must balance trade-offs between diverse goals, such as speed, energy efficiency, or stability, as a series of sequential decisions. This paper investigates the applicability and limitations of multi-objective evolutionary algorithms (MOEAs) in solving complex MORL problems. We assess whether these algorithms can effectively address the unique challenges posed by MORL and how MORL instances can serve as benchmarks to evaluate and improve MOEA performance. In particular, we propose a framework to characterize the features influencing MORL instance complexity, select representative MORL problems from the literature, and benchmark a suite of MOEAs alongside single-objective EAs using scalarized MORL formulations. Additionally, we evaluate the utility of existing multi-objective quality indicators in MORL scenarios, such as hypervolume conducting a comparison of the algorithms supported by statistical analysis. Our findings provide insights into the interplay between MORL problem characteristics and algorithmic effectiveness, highlighting opportunities for advancing both MORL research and the design of evolutionary algorithms.
Self-Evaluation for Job-Shop Scheduling
Feb 12, 2025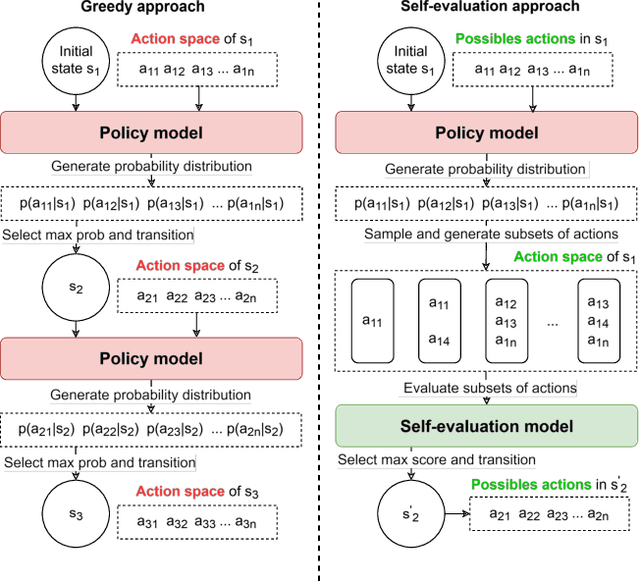
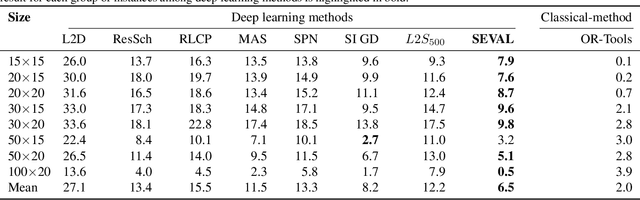
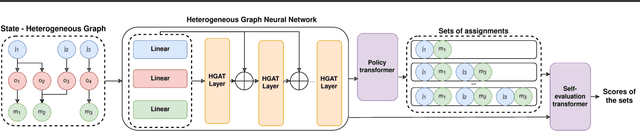
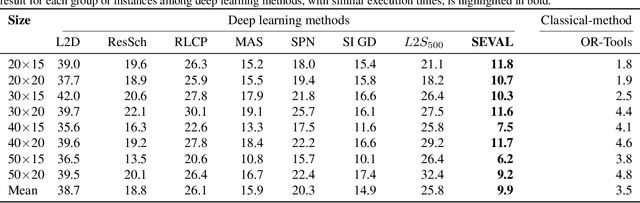
Combinatorial optimization problems, such as scheduling and route planning, are crucial in various industries but are computationally intractable due to their NP-hard nature. Neural Combinatorial Optimization methods leverage machine learning to address these challenges but often depend on sequential decision-making, which is prone to error accumulation as small mistakes propagate throughout the process. Inspired by self-evaluation techniques in Large Language Models, we propose a novel framework that generates and evaluates subsets of assignments, moving beyond traditional stepwise approaches. Applied to the Job-Shop Scheduling Problem, our method integrates a heterogeneous graph neural network with a Transformer to build a policy model and a self-evaluation function. Experimental validation on challenging, well-known benchmarks demonstrates the effectiveness of our approach, surpassing state-of-the-art methods.
Offline reinforcement learning for job-shop scheduling problems
Oct 21, 2024



Recent advances in deep learning have shown significant potential for solving combinatorial optimization problems in real-time. Unlike traditional methods, deep learning can generate high-quality solutions efficiently, which is crucial for applications like routing and scheduling. However, existing approaches like deep reinforcement learning (RL) and behavioral cloning have notable limitations, with deep RL suffering from slow learning and behavioral cloning relying solely on expert actions, which can lead to generalization issues and neglect of the optimization objective. This paper introduces a novel offline RL method designed for combinatorial optimization problems with complex constraints, where the state is represented as a heterogeneous graph and the action space is variable. Our approach encodes actions in edge attributes and balances expected rewards with the imitation of expert solutions. We demonstrate the effectiveness of this method on job-shop scheduling and flexible job-shop scheduling benchmarks, achieving superior performance compared to state-of-the-art techniques.
Domain Adaptation-Enhanced Searchlight: Enabling brain decoding from visual perception to mental imagery
Aug 02, 2024In cognitive neuroscience and brain-computer interface research, accurately predicting imagined stimuli is crucial. This study investigates the effectiveness of Domain Adaptation (DA) in enhancing imagery prediction using primarily visual data from fMRI scans of 18 subjects. Initially, we train a baseline model on visual stimuli to predict imagined stimuli, utilizing data from 14 brain regions. We then develop several models to improve imagery prediction, comparing different DA methods. Our results demonstrate that DA significantly enhances imagery prediction, especially with the Regular Transfer approach. We then conduct a DA-enhanced searchlight analysis using Regular Transfer, followed by permutation-based statistical tests to identify brain regions where imagery decoding is consistently above chance across subjects. Our DA-enhanced searchlight predicts imagery contents in a highly distributed set of brain regions, including the visual cortex and the frontoparietal cortex, thereby outperforming standard cross-domain classification methods. The complete code and data for this paper have been made openly available for the use of the scientific community.
Optimal synthesis embeddings
Jun 10, 2024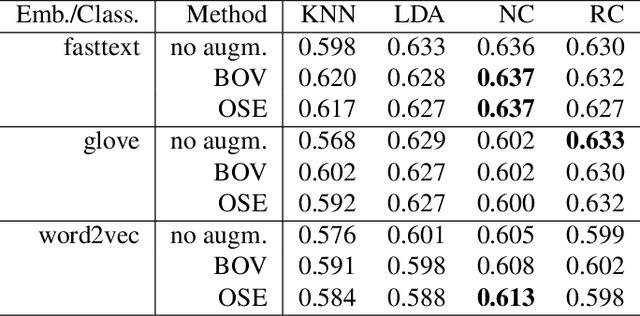
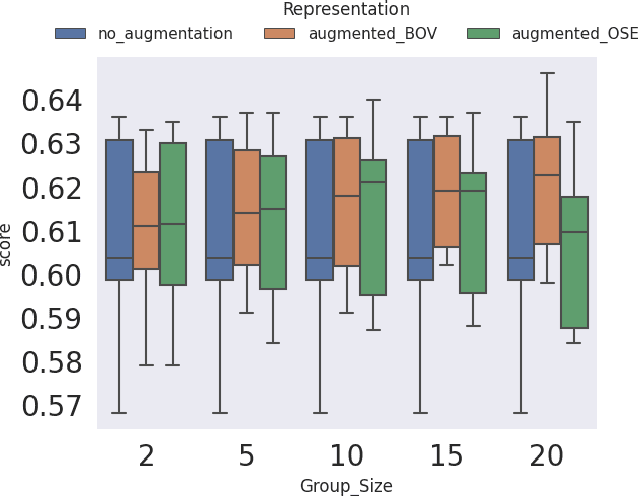
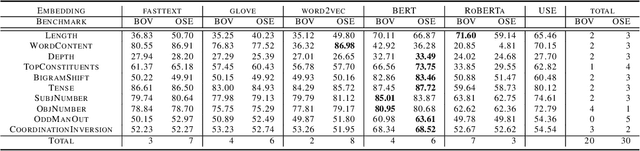
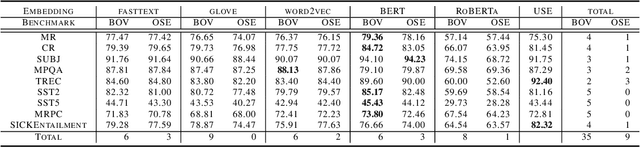
In this paper we introduce a word embedding composition method based on the intuitive idea that a fair embedding representation for a given set of words should satisfy that the new vector will be at the same distance of the vector representation of each of its constituents, and this distance should be minimized. The embedding composition method can work with static and contextualized word representations, it can be applied to create representations of sentences and learn also representations of sets of words that are not necessarily organized as a sequence. We theoretically characterize the conditions for the existence of this type of representation and derive the solution. We evaluate the method in data augmentation and sentence classification tasks, investigating several design choices of embeddings and composition methods. We show that our approach excels in solving probing tasks designed to capture simple linguistic features of sentences.
Identifying phase transitions in physical systems with neural networks: a neural architecture search perspective
Apr 23, 2024



The use of machine learning algorithms to investigate phase transitions in physical systems is a valuable way to better understand the characteristics of these systems. Neural networks have been used to extract information of phases and phase transitions directly from many-body configurations. However, one limitation of neural networks is that they require the definition of the model architecture and parameters previous to their application, and such determination is itself a difficult problem. In this paper, we investigate for the first time the relationship between the accuracy of neural networks for information of phases and the network configuration (that comprises the architecture and hyperparameters). We formulate the phase analysis as a regression task, address the question of generating data that reflects the different states of the physical system, and evaluate the performance of neural architecture search for this task. After obtaining the optimized architectures, we further implement smart data processing and analytics by means of neuron coverage metrics, assessing the capability of these metrics to estimate phase transitions. Our results identify the neuron coverage metric as promising for detecting phase transitions in physical systems.
Uncertainty-Aware Explanations Through Probabilistic Self-Explainable Neural Networks
Mar 20, 2024The lack of transparency of Deep Neural Networks continues to be a limitation that severely undermines their reliability and usage in high-stakes applications. Promising approaches to overcome such limitations are Prototype-Based Self-Explainable Neural Networks (PSENNs), whose predictions rely on the similarity between the input at hand and a set of prototypical representations of the output classes, offering therefore a deep, yet transparent-by-design, architecture. So far, such models have been designed by considering pointwise estimates for the prototypes, which remain fixed after the learning phase of the model. In this paper, we introduce a probabilistic reformulation of PSENNs, called Prob-PSENN, which replaces point estimates for the prototypes with probability distributions over their values. This provides not only a more flexible framework for an end-to-end learning of prototypes, but can also capture the explanatory uncertainty of the model, which is a missing feature in previous approaches. In addition, since the prototypes determine both the explanation and the prediction, Prob-PSENNs allow us to detect when the model is making uninformed or uncertain predictions, and to obtain valid explanations for them. Our experiments demonstrate that Prob-PSENNs provide more meaningful and robust explanations than their non-probabilistic counterparts, thus enhancing the explainability and reliability of the models.
Leveraging Constraint Programming in a Deep Learning Approach for Dynamically Solving the Flexible Job-Shop Scheduling Problem
Mar 14, 2024



Recent advancements in the flexible job-shop scheduling problem (FJSSP) are primarily based on deep reinforcement learning (DRL) due to its ability to generate high-quality, real-time solutions. However, DRL approaches often fail to fully harness the strengths of existing techniques such as exact methods or constraint programming (CP), which can excel at finding optimal or near-optimal solutions for smaller instances. This paper aims to integrate CP within a deep learning (DL) based methodology, leveraging the benefits of both. In this paper, we introduce a method that involves training a DL model using optimal solutions generated by CP, ensuring the model learns from high-quality data, thereby eliminating the need for the extensive exploration typical in DRL and enhancing overall performance. Further, we integrate CP into our DL framework to jointly construct solutions, utilizing DL for the initial complex stages and transitioning to CP for optimal resolution as the problem is simplified. Our hybrid approach has been extensively tested on three public FJSSP benchmarks, demonstrating superior performance over five state-of-the-art DRL approaches and a widely-used CP solver. Additionally, with the objective of exploring the application to other combinatorial optimization problems, promising preliminary results are presented on applying our hybrid approach to the traveling salesman problem, combining an exact method with a well-known DRL method.
Solving large flexible job shop scheduling instances by generating a diverse set of scheduling policies with deep reinforcement learning
Oct 24, 2023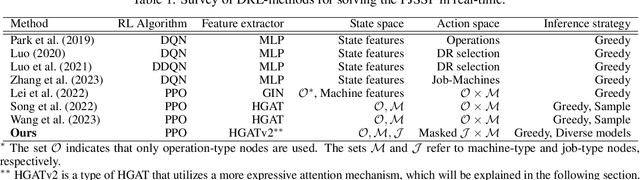
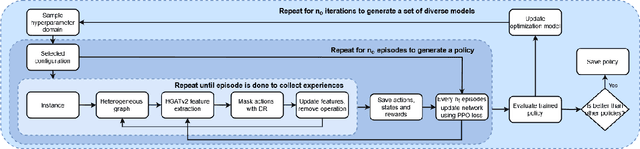
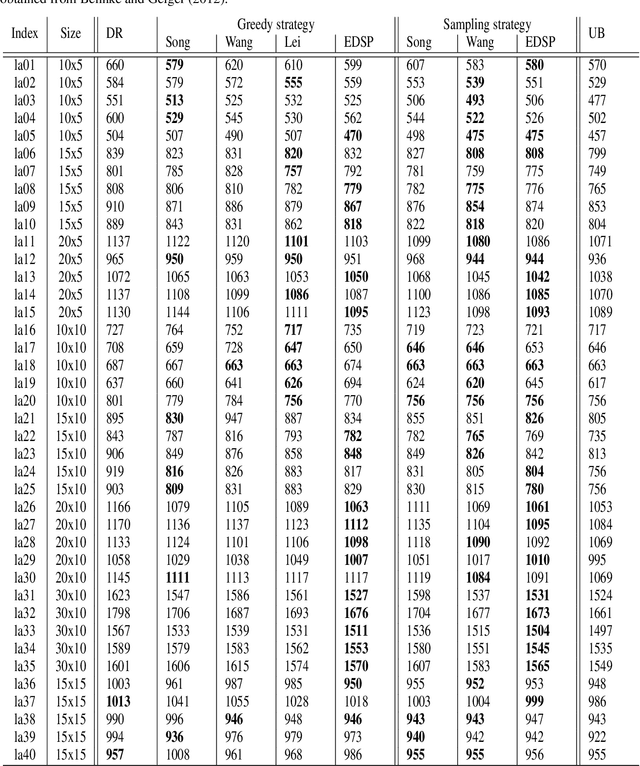
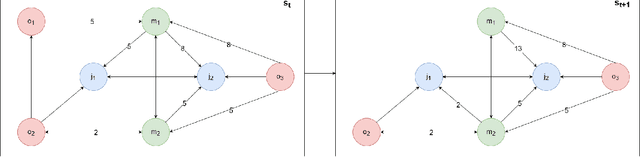
The Flexible Job Shop Scheduling Problem (FJSSP) has been extensively studied in the literature, and multiple approaches have been proposed within the heuristic, exact, and metaheuristic methods. However, the industry's demand to be able to respond in real-time to disruptive events has generated the necessity to be able to generate new schedules within a few seconds. Among these methods, under this constraint, only dispatching rules (DRs) are capable of generating schedules, even though their quality can be improved. To improve the results, recent methods have been proposed for modeling the FJSSP as a Markov Decision Process (MDP) and employing reinforcement learning to create a policy that generates an optimal solution assigning operations to machines. Nonetheless, there is still room for improvement, particularly in the larger FJSSP instances which are common in real-world scenarios. Therefore, the objective of this paper is to propose a method capable of robustly solving large instances of the FJSSP. To achieve this, we propose a novel way of modeling the FJSSP as an MDP using graph neural networks. We also present two methods to make inference more robust: generating a diverse set of scheduling policies that can be parallelized and limiting them using DRs. We have tested our approach on synthetically generated instances and various public benchmarks and found that our approach outperforms dispatching rules and achieves better results than three other recent deep reinforcement learning methods on larger FJSSP instances.