 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed Point Explainability
May 18, 2025



This paper introduces a formal notion of fixed point explanations, inspired by the "why regress" principle, to assess, through recursive applications, the stability of the interplay between a model and its explainer. Fixed point explanations satisfy properties like minimality, stability, and faithfulness, revealing hidden model behaviours and explanatory weaknesses. We define convergence conditions for several classes of explainers, from feature-based to mechanistic tools like Sparse AutoEncoders, and we report quantitative and qualitative results.
Uncertainty-Aware Explanations Through Probabilistic Self-Explainable Neural Networks
Mar 20, 2024The lack of transparency of Deep Neural Networks continues to be a limitation that severely undermines their reliability and usage in high-stakes applications. Promising approaches to overcome such limitations are Prototype-Based Self-Explainable Neural Networks (PSENNs), whose predictions rely on the similarity between the input at hand and a set of prototypical representations of the output classes, offering therefore a deep, yet transparent-by-design, architecture. So far, such models have been designed by considering pointwise estimates for the prototypes, which remain fixed after the learning phase of the model. In this paper, we introduce a probabilistic reformulation of PSENNs, called Prob-PSENN, which replaces point estimates for the prototypes with probability distributions over their values. This provides not only a more flexible framework for an end-to-end learning of prototypes, but can also capture the explanatory uncertainty of the model, which is a missing feature in previous approaches. In addition, since the prototypes determine both the explanation and the prediction, Prob-PSENNs allow us to detect when the model is making uninformed or uncertain predictions, and to obtain valid explanations for them. Our experiments demonstrate that Prob-PSENNs provide more meaningful and robust explanations than their non-probabilistic counterparts, thus enhancing the explainability and reliability of the models.
When and How to Fool Explainable Models with Adversarial Examples
Jul 05, 2021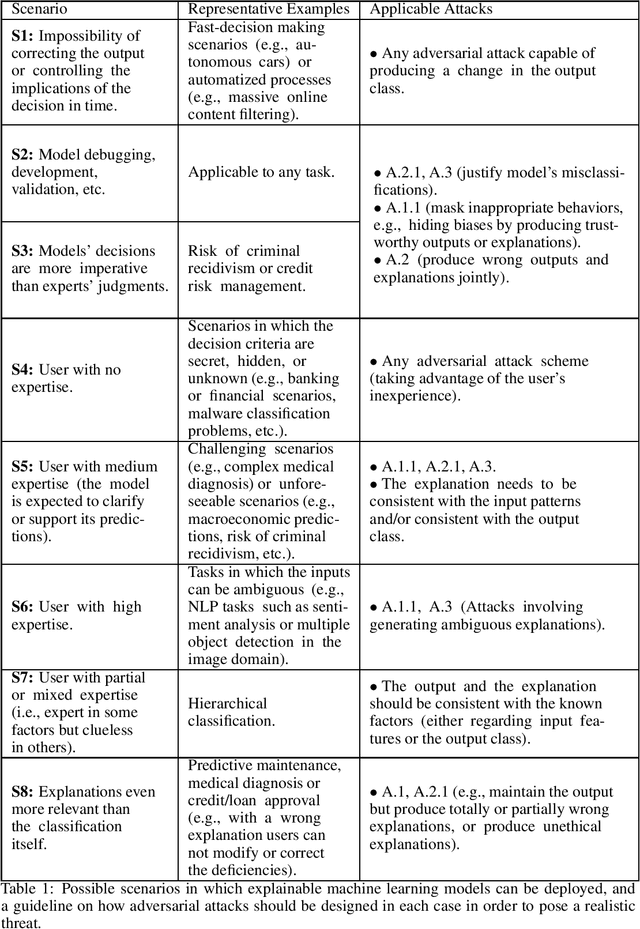
Reliable deployment of machine learning models such as neural networks continues to be challenging due to several limitations. Some of the main shortcomings are the lack of interpretability and the lack of robustness against adversarial examples or out-of-distribution inputs. In this paper, we explore the possibilities and limits of adversarial attacks for explainable machine learning models. First, we extend the notion of adversarial examples to fit in explainable machine learning scenarios, in which the inputs, the output classifications and the explanations of the model's decisions are assessed by humans. Next, we propose a comprehensive framework to study whether (and how) adversarial examples can be generated for explainable models under human assessment, introducing novel attack paradigms. In particular, our framework considers a wide range of relevant (yet often ignored) factors such as the type of problem, the user expertise or the objective of the explanations in order to identify the attack strategies that should be adopted in each scenario to successfully deceive the model (and the human). These contributions intend to serve as a basis for a more rigorous and realistic study of adversarial examples in the field of explainable machine learning.
Analysis of Dominant Classes in Universal Adversarial Perturbations
Jan 11, 2021
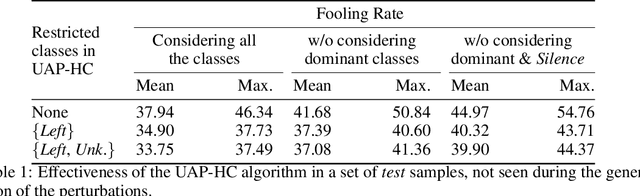
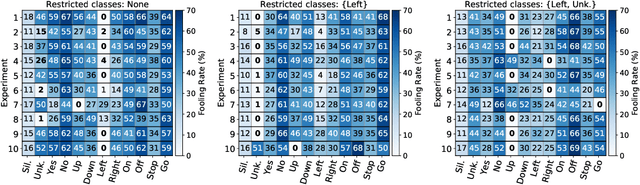
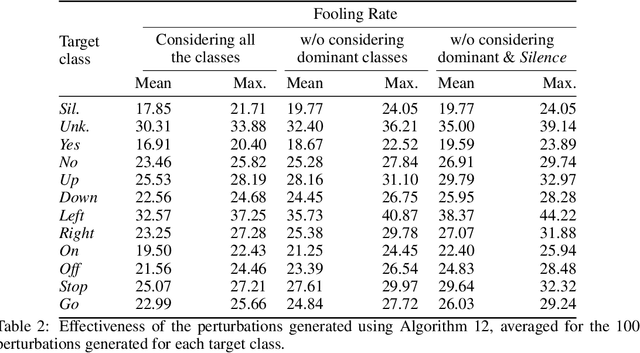
The reasons why Deep Neural Networks are susceptible to being fooled by adversarial examples remains an open discussion. Indeed, many different strategies can be employed to efficiently generate adversarial attacks, some of them relying on different theoretical justifications. Among these strategies, universal (input-agnostic) perturbations are of particular interest, due to their capability to fool a network independently of the input in which the perturbation is applied. In this work, we investigate an intriguing phenomenon of universal perturbations, which has been reported previously in the literature, yet without a proven justification: universal perturbations change the predicted classes for most inputs into one particular (dominant) class, even if this behavior is not specified during the creation of the perturbation. In order to justify the cause of this phenomenon, we propose a number of hypotheses and experimentally test them using a speech command classification problem in the audio domain as a testbed. Our analyses reveal interesting properties of universal perturbations, suggest new methods to generate such attacks and provide an explanation of dominant classes, under both a geometric and a data-feature perspective.
Extending Adversarial Attacks to Produce Adversarial Class Probability Distributions
Apr 14, 2020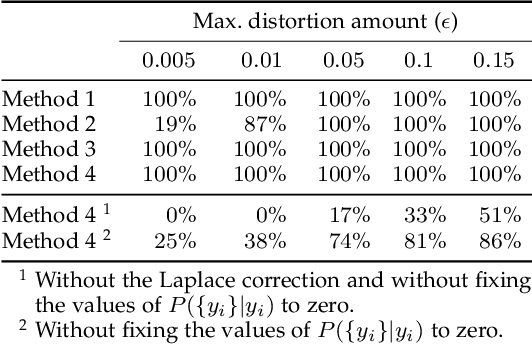
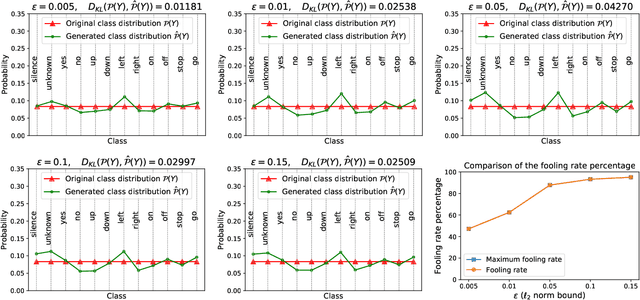
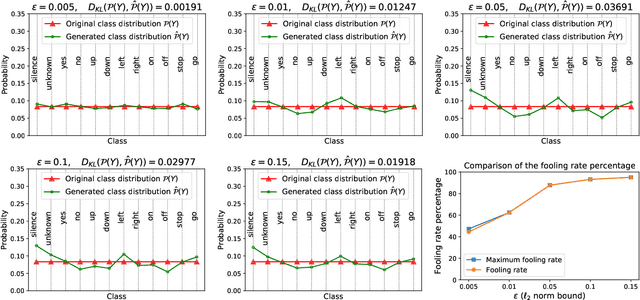
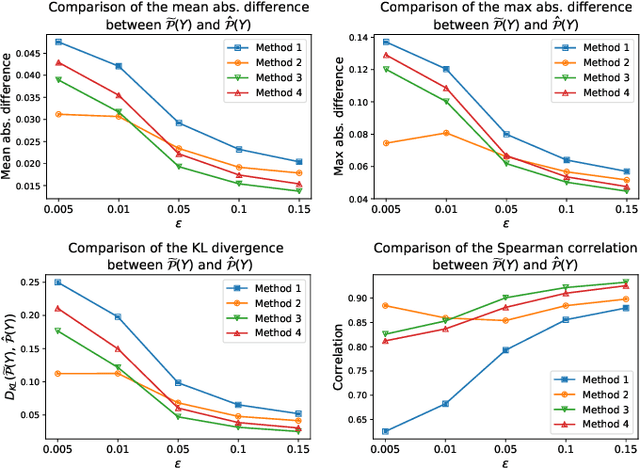
Despite the remarkable performance and generalization levels of deep learning models in a wide range of artificial intelligence tasks, it has been demonstrated that these models can be easily fooled by the addition of imperceptible but malicious perturbations to natural inputs. These altered inputs are known in the literature as adversarial examples. In this paper we propose a novel probabilistic framework to generalize and extend adversarial attacks in order to produce a desired probability distribution for the classes when we apply the attack method to a large number of inputs. This novel attack strategy provides the attacker with greater control over the target model, and increases the complexity of detecting that the model is being attacked. We introduce three different strategies to efficiently generate such attacks, and illustrate our approach extending DeepFool, a state-of-the-art attack algorithm to generate adversarial examples. We also experimentally validate our approach for the spoken command classification task, an exemplary machine learning problem in the audio domain. Our results demonstrate that we can closely approximate any probability distribution for the classes while maintaining a high fooling rate and by injecting imperceptible perturbations to the inputs.
On the human evaluation of audio adversarial examples
Jan 23, 2020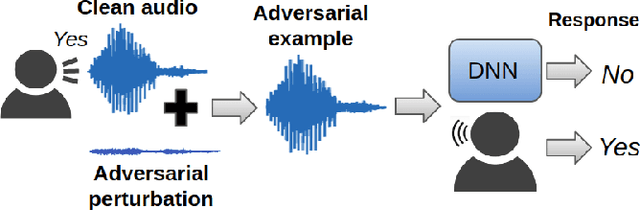
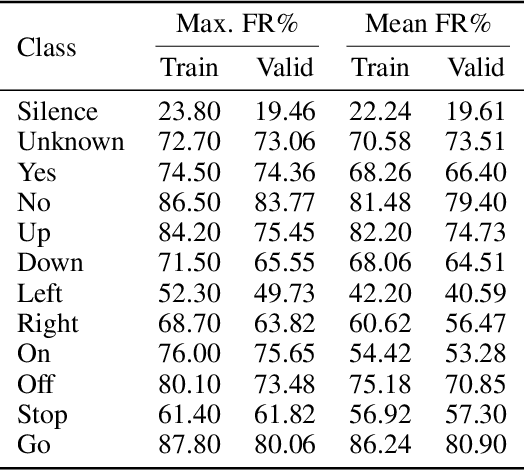
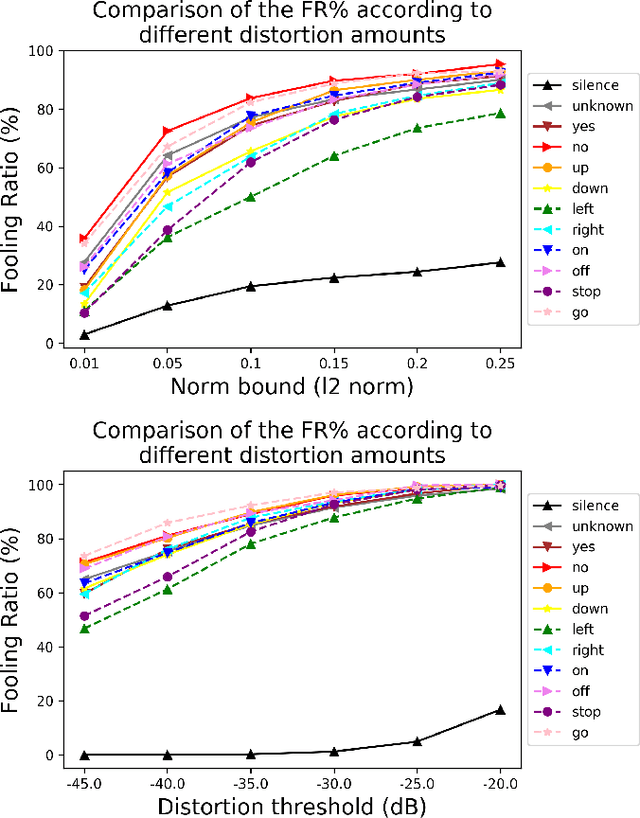
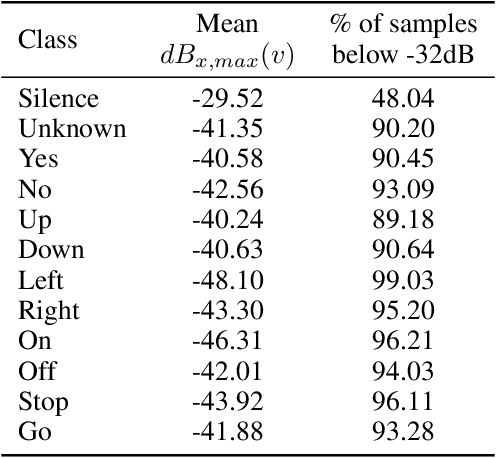
Human-machine interaction is increasingly dependent on speech communication. Machine Learning models are usually applied to interpret human speech commands. However, these models can be fooled by adversarial examples, which are inputs intentionally perturbed to produce a wrong prediction without being noticed. While much research has been focused on developing new techniques to generate adversarial perturbations, less attention has been given to aspects that determine whether and how the perturbations are noticed by humans. This question is relevant since high fooling rates of proposed adversarial perturbation strategies are only valuable if the perturbations are not detectable. In this paper we investigate to which extent the distortion metrics proposed in the literature for audio adversarial examples, and which are commonly applied to evaluate the effectiveness of methods for generating these attacks, are a reliable measure of the human perception of the perturbations. Using an analytical framework, and an experiment in which 18 subjects evaluate audio adversarial examples, we demonstrate that the metrics employed by convention are not a reliable measure of the perceptual similarity of adversarial examples in the audio domain.
Universal adversarial examples in speech command classification
Nov 26, 2019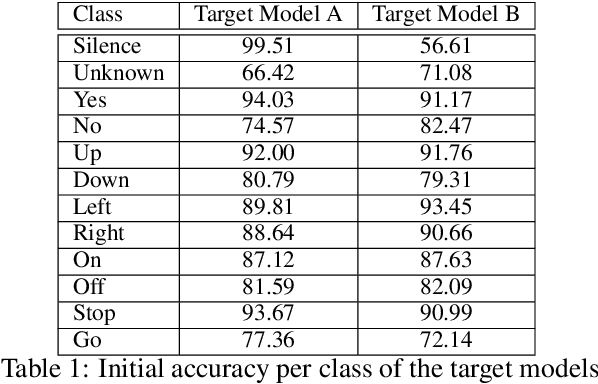
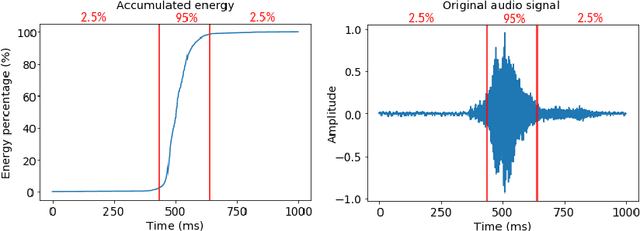
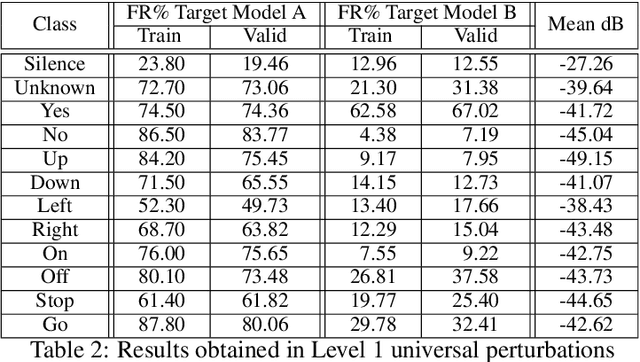
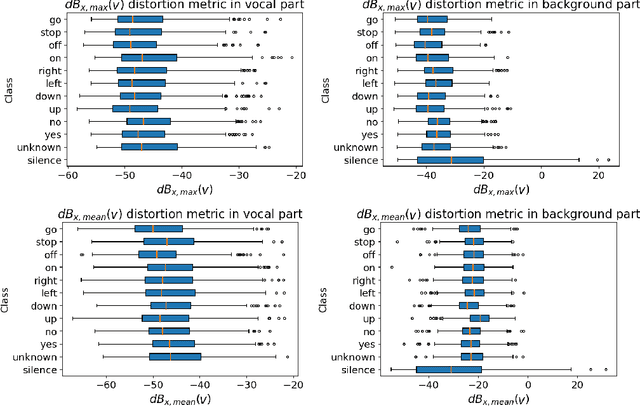
Adversarial examples are inputs intentionally perturbed with the aim of forcing a machine learning model to produce a wrong prediction, while the changes are not easily detectable by a human. Although this topic has been intensively studied in the image domain, classification tasks in the audio domain have received less attention. In this paper we address the existence of universal perturbations for speech command classification. We provide evidence that universal attacks can be generated for speech command classification tasks, which are able to generalize across different models to a significant extent. Additionally, a novel analytical framework is proposed for the evaluation of universal perturbations under different levels of universality, demonstrating that the feasibility of generating effective perturbations decreases as the universality level increases. Finally, we propose a more detailed and rigorous framework to measure the amount of distortion introduced by the perturbations, demonstrating that the methods employed by convention are not realistic in audio-based problems.