 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal adversarial examples in speech command classification
Paper and Code
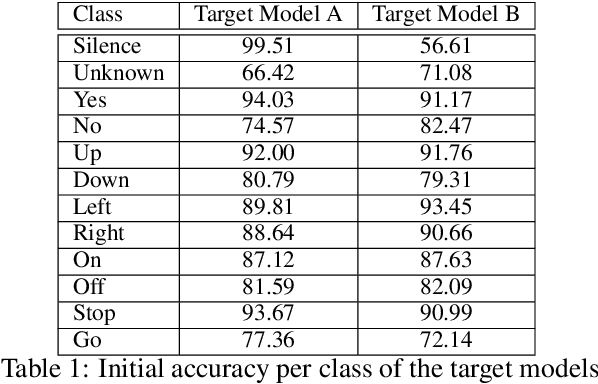
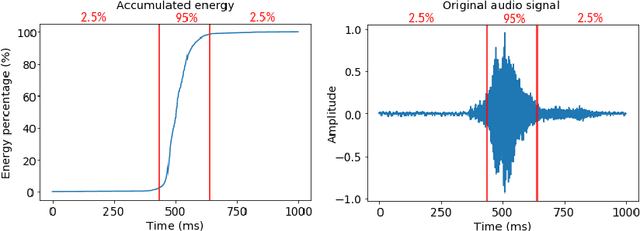
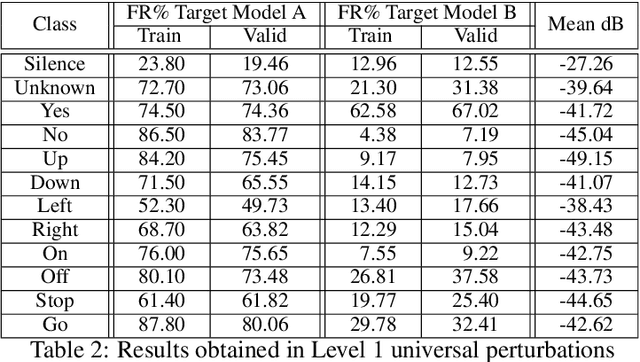
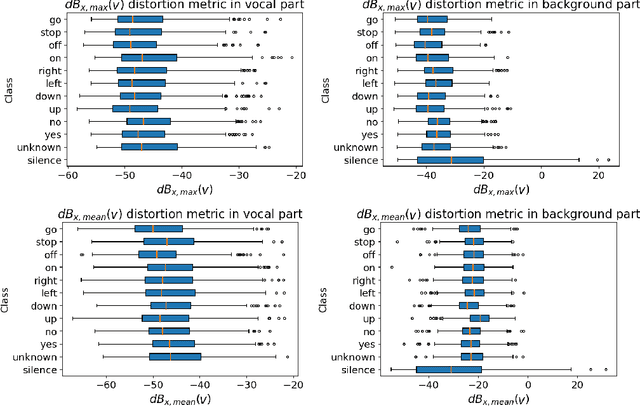
Adversarial examples are inputs intentionally perturbed with the aim of forcing a machine learning model to produce a wrong prediction, while the changes are not easily detectable by a human. Although this topic has been intensively studied in the image domain, classification tasks in the audio domain have received less attention. In this paper we address the existence of universal perturbations for speech command classification. We provide evidence that universal attacks can be generated for speech command classification tasks, which are able to generalize across different models to a significant extent. Additionally, a novel analytical framework is proposed for the evaluation of universal perturbations under different levels of universality, demonstrating that the feasibility of generating effective perturbations decreases as the universality level increases. Finally, we propose a more detailed and rigorous framework to measure the amount of distortion introduced by the perturbations, demonstrating that the methods employed by convention are not realistic in audio-based problems.