 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and How to Fool Explainable Models with Adversarial Examples
Paper and Code
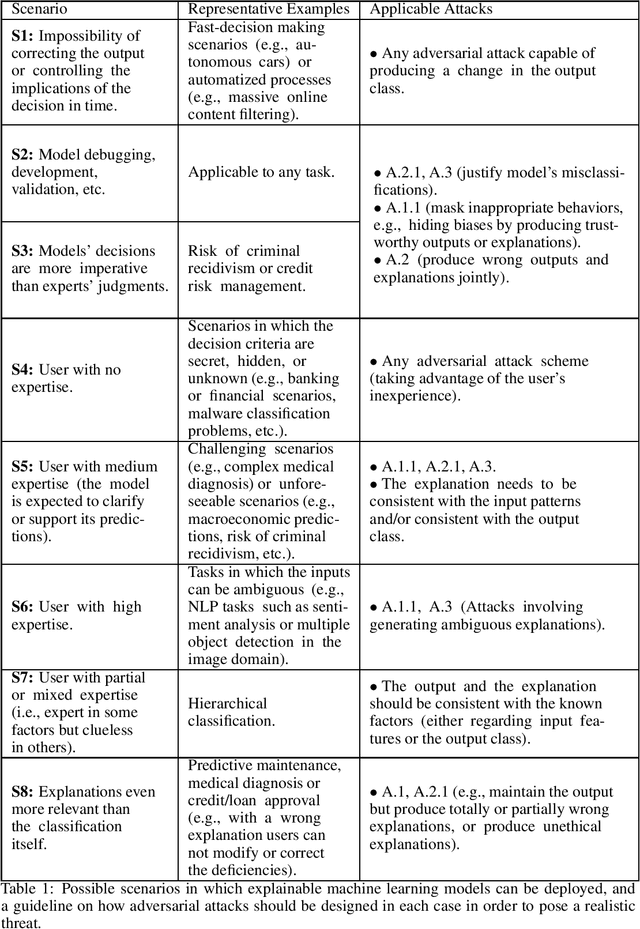
Reliable deployment of machine learning models such as neural networks continues to be challenging due to several limitations. Some of the main shortcomings are the lack of interpretability and the lack of robustness against adversarial examples or out-of-distribution inputs. In this paper, we explore the possibilities and limits of adversarial attacks for explainable machine learning models. First, we extend the notion of adversarial examples to fit in explainable machine learning scenarios, in which the inputs, the output classifications and the explanations of the model's decisions are assessed by humans. Next, we propose a comprehensive framework to study whether (and how) adversarial examples can be generated for explainable models under human assessment, introducing novel attack paradigms. In particular, our framework considers a wide range of relevant (yet often ignored) factors such as the type of problem, the user expertise or the objective of the explanations in order to identify the attack strategies that should be adopted in each scenario to successfully deceive the model (and the human). These contributions intend to serve as a basis for a more rigorous and realistic study of adversarial examples in the field of explainable machine learning.