 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed Point Explainability
May 18, 2025



This paper introduces a formal notion of fixed point explanations, inspired by the "why regress" principle, to assess, through recursive applications, the stability of the interplay between a model and its explainer. Fixed point explanations satisfy properties like minimality, stability, and faithfulness, revealing hidden model behaviours and explanatory weaknesses. We define convergence conditions for several classes of explainers, from feature-based to mechanistic tools like Sparse AutoEncoders, and we report quantitative and qualitative results.
Interpretable Company Similarity with Sparse Autoencoders
Dec 03, 2024



Determining company similarity is a vital task in finance, underpinning hedging, risk management, portfolio diversification, and more. Practitioners often rely on sector and industry classifications to gauge similarity, such as SIC-codes and GICS-codes, the former being used by the U.S. Securities and Exchange Commission (SEC), and the latter widely used by the investment community. Clustering embeddings of company descriptions has been proposed as a potential technique for determining company similarity, but the lack of interpretability in token embeddings poses a significant barrier to adoption in high-stakes contexts. Sparse Autoencoders have shown promise in enhancing the interpretability of Large Language Models by decomposing LLM activations into interpretable features. In this paper, we explore the use of SAE features in measuring company similarity and benchmark them against (1) SIC codes and (2) Major Group codes. We conclude that SAE features can reproduce and even surpass sector classifications in quantifying fundamental characteristics of companies, evaluated by the correlation of monthly returns, a proxy for similarity, and PnL from cointegration.
Efficient Training of Sparse Autoencoders for Large Language Models via Layer Groups
Oct 28, 2024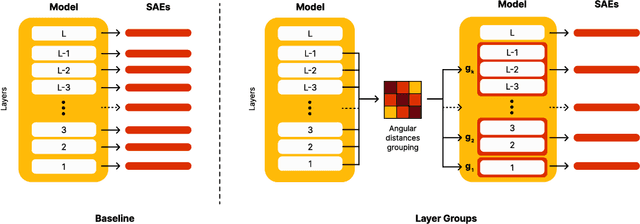

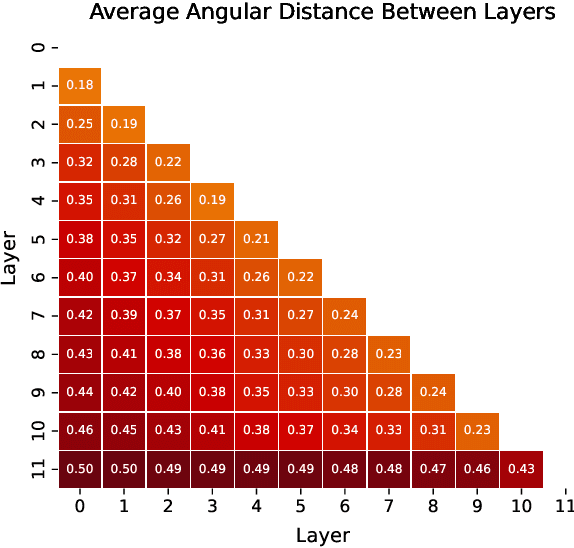
Sparse AutoEnocders (SAEs) have recently been employed as an unsupervised approach for understanding the inner workings of Large Language Models (LLMs). They reconstruct the model's activations with a sparse linear combination of interpretable features. However, training SAEs is computationally intensive, especially as models grow in size and complexity. To address this challenge, we propose a novel training strategy that reduces the number of trained SAEs from one per layer to one for a given group of contiguous layers. Our experimental results on Pythia 160M highlight a speedup of up to 6x without compromising the reconstruction quality and performance on downstream tasks. Therefore, layer clustering presents an efficient approach to train SAEs in modern LLMs.