 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Adversarial Attacks to Produce Adversarial Class Probability Distributions
Paper and Code
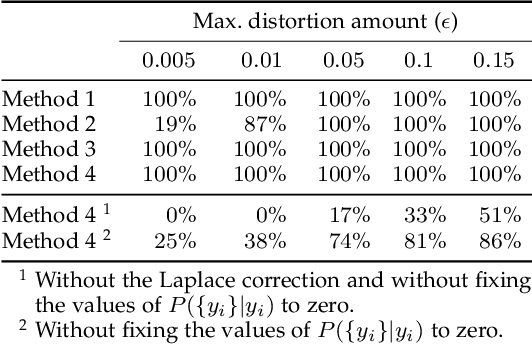
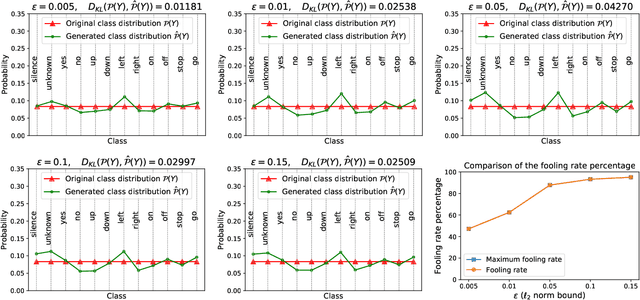
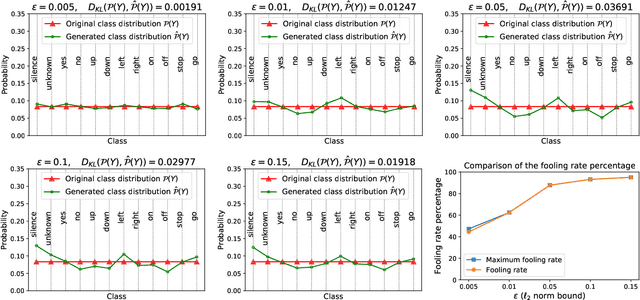
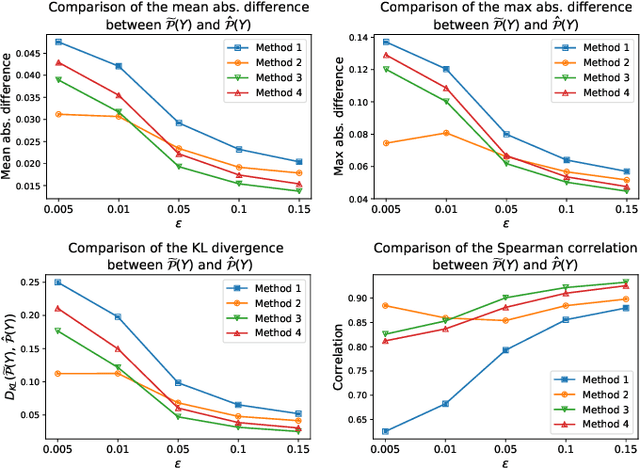
Despite the remarkable performance and generalization levels of deep learning models in a wide range of artificial intelligence tasks, it has been demonstrated that these models can be easily fooled by the addition of imperceptible but malicious perturbations to natural inputs. These altered inputs are known in the literature as adversarial examples. In this paper we propose a novel probabilistic framework to generalize and extend adversarial attacks in order to produce a desired probability distribution for the classes when we apply the attack method to a large number of inputs. This novel attack strategy provides the attacker with greater control over the target model, and increases the complexity of detecting that the model is being attacked. We introduce three different strategies to efficiently generate such attacks, and illustrate our approach extending DeepFool, a state-of-the-art attack algorithm to generate adversarial examples. We also experimentally validate our approach for the spoken command classification task, an exemplary machine learning problem in the audio domain. Our results demonstrate that we can closely approximate any probability distribution for the classes while maintaining a high fooling rate and by injecting imperceptible perturbations to the inputs.