 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the human evaluation of audio adversarial examples
Paper and Code
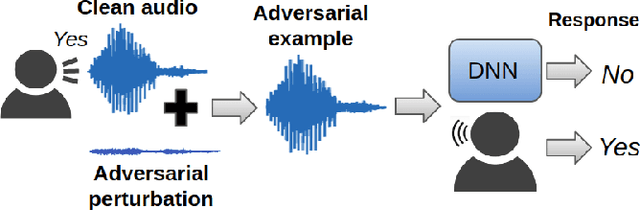
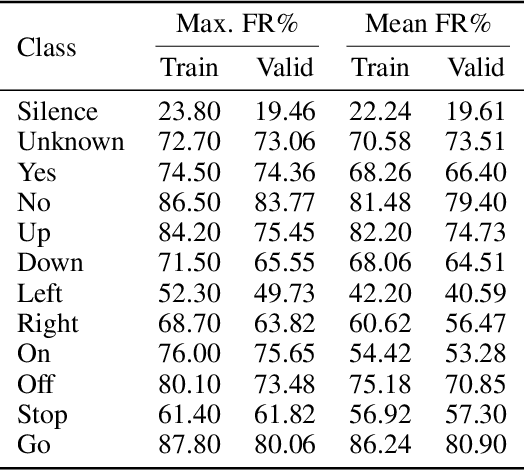
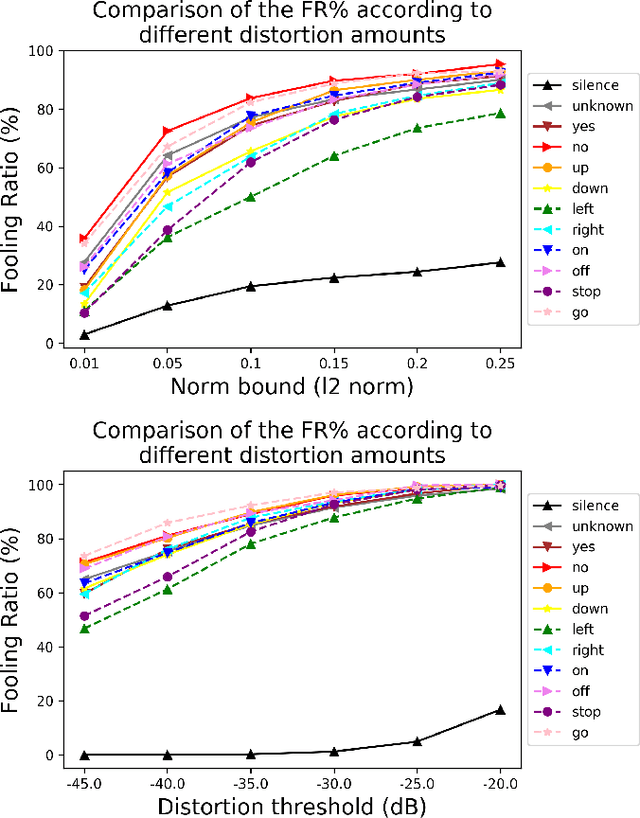
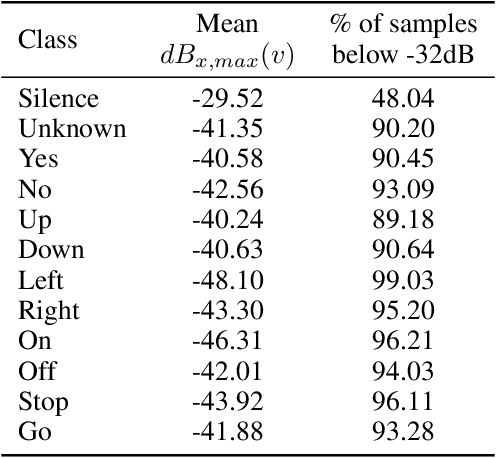
Human-machine interaction is increasingly dependent on speech communication. Machine Learning models are usually applied to interpret human speech commands. However, these models can be fooled by adversarial examples, which are inputs intentionally perturbed to produce a wrong prediction without being noticed. While much research has been focused on developing new techniques to generate adversarial perturbations, less attention has been given to aspects that determine whether and how the perturbations are noticed by humans. This question is relevant since high fooling rates of proposed adversarial perturbation strategies are only valuable if the perturbations are not detectable. In this paper we investigate to which extent the distortion metrics proposed in the literature for audio adversarial examples, and which are commonly applied to evaluate the effectiveness of methods for generating these attacks, are a reliable measure of the human perception of the perturbations. Using an analytical framework, and an experiment in which 18 subjects evaluate audio adversarial examples, we demonstrate that the metrics employed by convention are not a reliable measure of the perceptual similarity of adversarial examples in the audio domain.