 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evaluation for Job-Shop Scheduling
Feb 12, 2025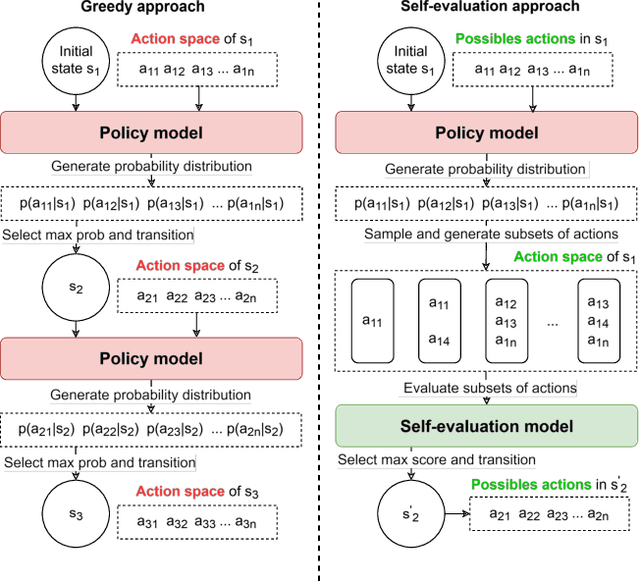
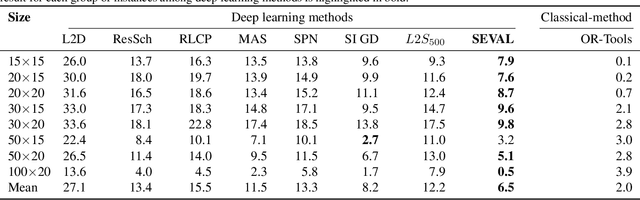
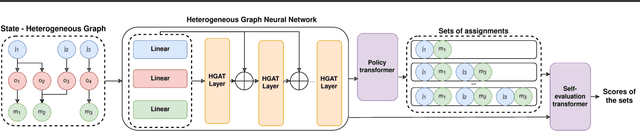
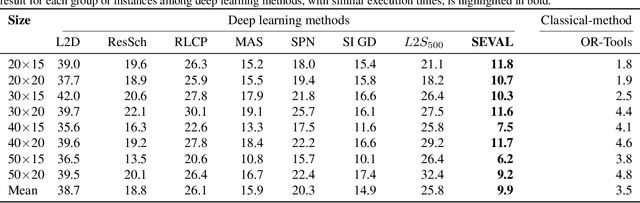
Combinatorial optimization problems, such as scheduling and route planning, are crucial in various industries but are computationally intractable due to their NP-hard nature. Neural Combinatorial Optimization methods leverage machine learning to address these challenges but often depend on sequential decision-making, which is prone to error accumulation as small mistakes propagate throughout the process. Inspired by self-evaluation techniques in Large Language Models, we propose a novel framework that generates and evaluates subsets of assignments, moving beyond traditional stepwise approaches. Applied to the Job-Shop Scheduling Problem, our method integrates a heterogeneous graph neural network with a Transformer to build a policy model and a self-evaluation function. Experimental validation on challenging, well-known benchmarks demonstrates the effectiveness of our approach, surpassing state-of-the-art methods.
Offline reinforcement learning for job-shop scheduling problems
Oct 21, 2024



Recent advances in deep learning have shown significant potential for solving combinatorial optimization problems in real-time. Unlike traditional methods, deep learning can generate high-quality solutions efficiently, which is crucial for applications like routing and scheduling. However, existing approaches like deep reinforcement learning (RL) and behavioral cloning have notable limitations, with deep RL suffering from slow learning and behavioral cloning relying solely on expert actions, which can lead to generalization issues and neglect of the optimization objective. This paper introduces a novel offline RL method designed for combinatorial optimization problems with complex constraints, where the state is represented as a heterogeneous graph and the action space is variable. Our approach encodes actions in edge attributes and balances expected rewards with the imitation of expert solutions. We demonstrate the effectiveness of this method on job-shop scheduling and flexible job-shop scheduling benchmarks, achieving superior performance compared to state-of-the-art techniques.
Leveraging Constraint Programming in a Deep Learning Approach for Dynamically Solving the Flexible Job-Shop Scheduling Problem
Mar 14, 2024



Recent advancements in the flexible job-shop scheduling problem (FJSSP) are primarily based on deep reinforcement learning (DRL) due to its ability to generate high-quality, real-time solutions. However, DRL approaches often fail to fully harness the strengths of existing techniques such as exact methods or constraint programming (CP), which can excel at finding optimal or near-optimal solutions for smaller instances. This paper aims to integrate CP within a deep learning (DL) based methodology, leveraging the benefits of both. In this paper, we introduce a method that involves training a DL model using optimal solutions generated by CP, ensuring the model learns from high-quality data, thereby eliminating the need for the extensive exploration typical in DRL and enhancing overall performance. Further, we integrate CP into our DL framework to jointly construct solutions, utilizing DL for the initial complex stages and transitioning to CP for optimal resolution as the problem is simplified. Our hybrid approach has been extensively tested on three public FJSSP benchmarks, demonstrating superior performance over five state-of-the-art DRL approaches and a widely-used CP solver. Additionally, with the objective of exploring the application to other combinatorial optimization problems, promising preliminary results are presented on applying our hybrid approach to the traveling salesman problem, combining an exact method with a well-known DRL method.
Solving large flexible job shop scheduling instances by generating a diverse set of scheduling policies with deep reinforcement learning
Oct 24, 2023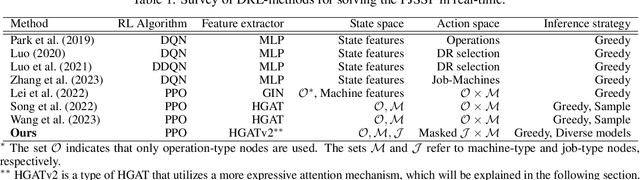
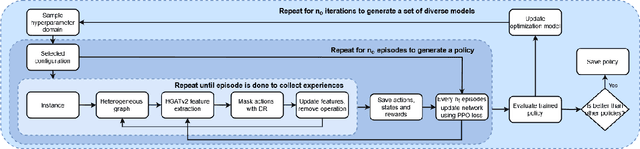
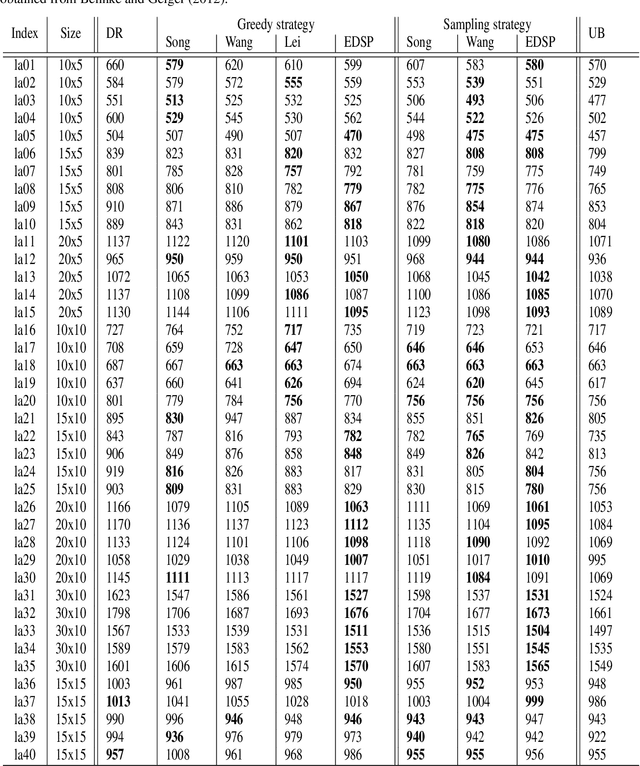
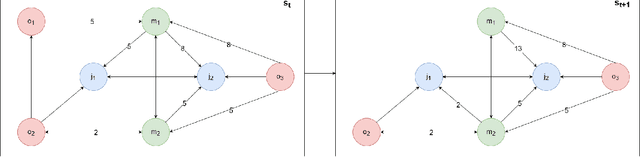
The Flexible Job Shop Scheduling Problem (FJSSP) has been extensively studied in the literature, and multiple approaches have been proposed within the heuristic, exact, and metaheuristic methods. However, the industry's demand to be able to respond in real-time to disruptive events has generated the necessity to be able to generate new schedules within a few seconds. Among these methods, under this constraint, only dispatching rules (DRs) are capable of generating schedules, even though their quality can be improved. To improve the results, recent methods have been proposed for modeling the FJSSP as a Markov Decision Process (MDP) and employing reinforcement learning to create a policy that generates an optimal solution assigning operations to machines. Nonetheless, there is still room for improvement, particularly in the larger FJSSP instances which are common in real-world scenarios. Therefore, the objective of this paper is to propose a method capable of robustly solving large instances of the FJSSP. To achieve this, we propose a novel way of modeling the FJSSP as an MDP using graph neural networks. We also present two methods to make inference more robust: generating a diverse set of scheduling policies that can be parallelized and limiting them using DRs. We have tested our approach on synthetically generated instances and various public benchmarks and found that our approach outperforms dispatching rules and achieves better results than three other recent deep reinforcement learning methods on larger FJSSP instances.