 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving imputation strategies for missing data in classification problems with TPOT
Paper and Code
Aug 14, 2017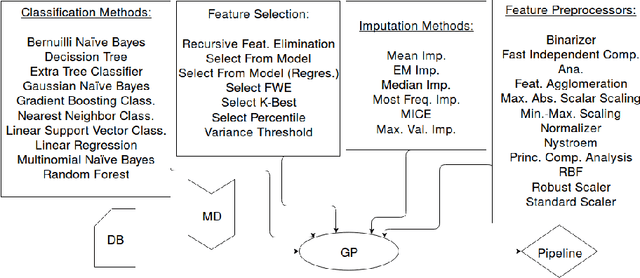

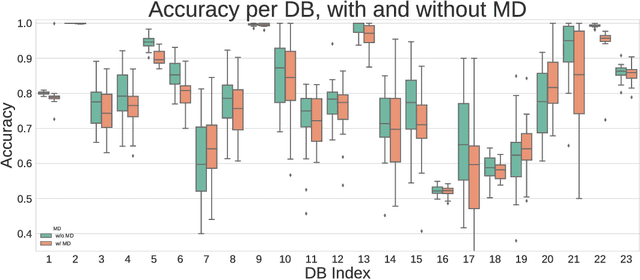
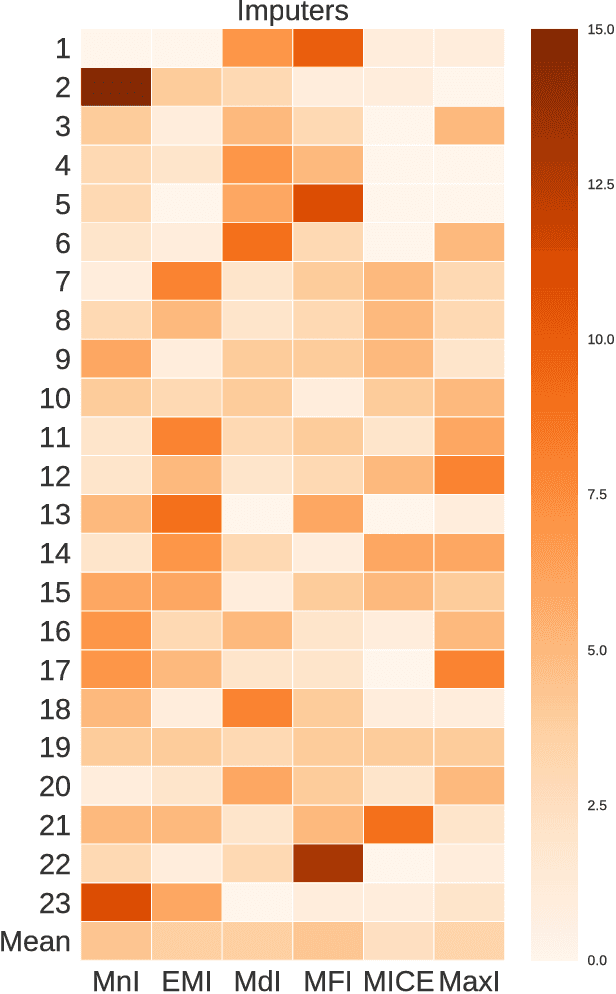
Missing data has a ubiquitous presence in real-life applications of machine learning techniques. Imputation methods are algorithms conceived for restoring missing values in the data, based on other entries in the database. The choice of the imputation method has an influence on the performance of the machine learning technique, e.g., it influences the accuracy of the classification algorithm applied to the data. Therefore, selecting and applying the right imputation method is important and usually requires a substantial amount of human intervention. In this paper we propose the use of genetic programming techniques to search for the right combination of imputation and classification algorithms. We build our work on the recently introduced Python-based TPOT library, and incorporate a heterogeneous set of imputation algorithms as part of the machine learning pipeline search. We show that genetic programming can automatically find increasingly better pipelines that include the most effective combinations of imputation methods, feature pre-processing, and classifiers for a variety of classification problems with missing data.