 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight up that Droid! On the Effectiveness of Static Analysis Features against App Obfuscation for Android Malware Detection
Oct 24, 2023



Malware authors have seen obfuscation as the mean to bypass malware detectors based on static analysis features. For Android, several studies have confirmed that many anti-malware products are easily evaded with simple program transformations. As opposed to these works, ML detection proposals for Android leveraging static analysis features have also been proposed as obfuscation-resilient. Therefore, it needs to be determined to what extent the use of a specific obfuscation strategy or tool poses a risk for the validity of ML malware detectors for Android based on static analysis features. To shed some light in this regard, in this article we assess the impact of specific obfuscation techniques on common features extracted using static analysis and determine whether the changes are significant enough to undermine the effectiveness of ML malware detectors that rely on these features. The experimental results suggest that obfuscation techniques affect all static analysis features to varying degrees across different tools. However, certain features retain their validity for ML malware detection even in the presence of obfuscation. Based on these findings, we propose a ML malware detector for Android that is robust against obfuscation and outperforms current state-of-the-art detectors.
Towards a Fair Comparison and Realistic Design and Evaluation Framework of Android Malware Detectors
May 25, 2022

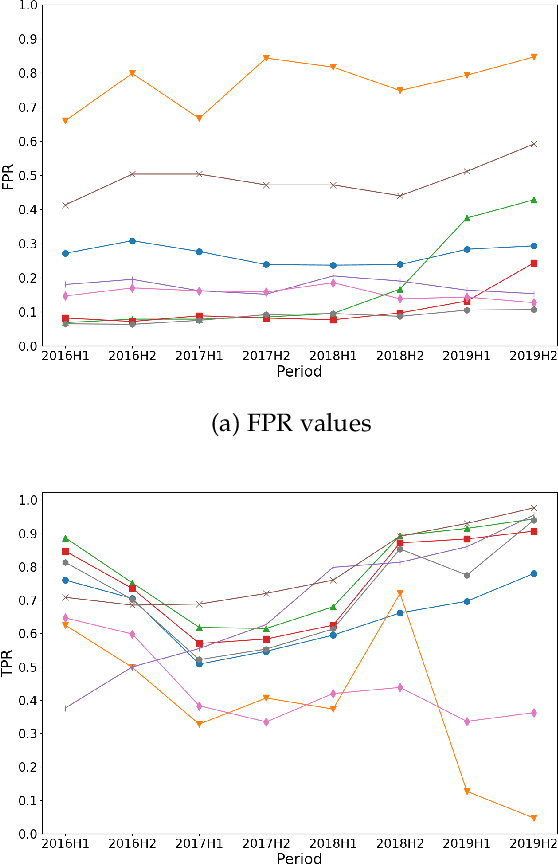
As in other cybersecurity areas, machine learning (ML) techniques have emerged as a promising solution to detect Android malware. In this sense, many proposals employing a variety of algorithms and feature sets have been presented to date, often reporting impresive detection performances. However, the lack of reproducibility and the absence of a standard evaluation framework make these proposals difficult to compare. In this paper, we perform an analysis of 10 influential research works on Android malware detection using a common evaluation framework. We have identified five factors that, if not taken into account when creating datasets and designing detectors, significantly affect the trained ML models and their performances. In particular, we analyze the effect of (1) the presence of duplicated samples, (2) label (goodware/greyware/malware) attribution, (3) class imbalance, (4) the presence of apps that use evasion techniques and, (5) the evolution of apps. Based on this extensive experimentation, we conclude that the studied ML-based detectors have been evaluated optimistically, which justifies the good published results. Our findings also highlight that it is imperative to generate realistic datasets, taking into account the factors mentioned above, to enable the design and evaluation of better solutions for Android malware detection.
A review on outlier/anomaly detection in time series data
Feb 11, 2020

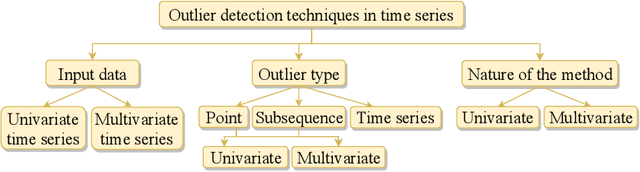
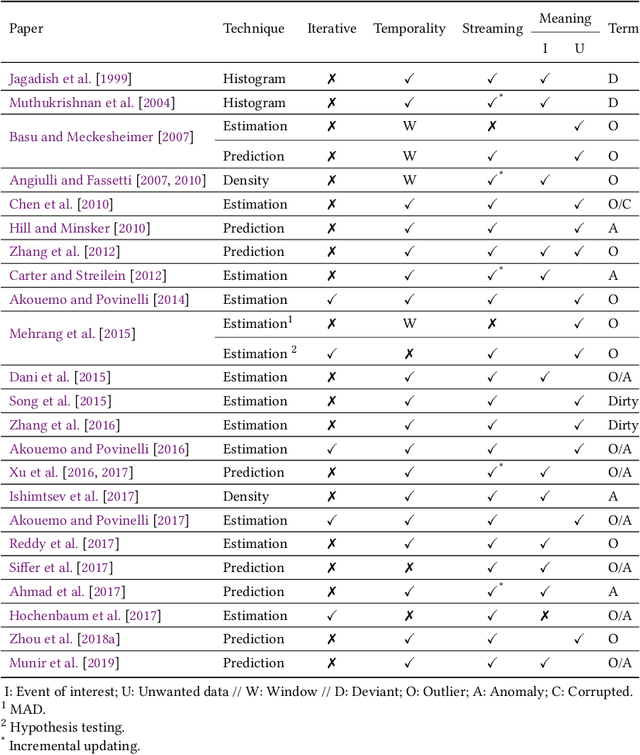
Recent advances in technology have brought major breakthroughs in data collection, enabling a large amount of data to be gathered over time and thus generating time series. Mining this data has become an important task for researchers and practitioners in the past few years, including the detection of outliers or anomalies that may represent errors or events of interest. This review aims to provide a structured and comprehensive state-of-the-art on outlier detection techniques in the context of time series. To this end, a taxonomy is presented based on the main aspects that characterize an outlier detection technique.
Survey of Network Intrusion Detection Methods from the Perspective of the Knowledge Discovery in Databases Process
Jan 27, 2020



The identification of cyberattacks which target information and communication systems has been a focus of the research community for years. Network intrusion detection is a complex problem which presents a diverse number of challenges. Many attacks currently remain undetected, while newer ones emerge due to the proliferation of connected devices and the evolution of communication technology. In this survey, we review the methods that have been applied to network data with the purpose of developing an intrusion detector, but contrary to previous reviews in the area, we analyze them from the perspective of the Knowledge Discovery in Databases (KDD) process. As such, we discuss the techniques used for the capture, preparation and transformation of the data, as well as, the data mining and evaluation methods. In addition, we also present the characteristics and motivations behind the use of each of these techniques and propose more adequate and up-to-date taxonomies and definitions for intrusion detectors based on the terminology used in the area of data mining and KDD. Special importance is given to the evaluation procedures followed to assess the different detectors, discussing their applicability in current real networks. Finally, as a result of this literature review, we investigate some open issues which will need to be considered for further research in the area of network security.
A review on distance based time series classification
Jun 12, 2018

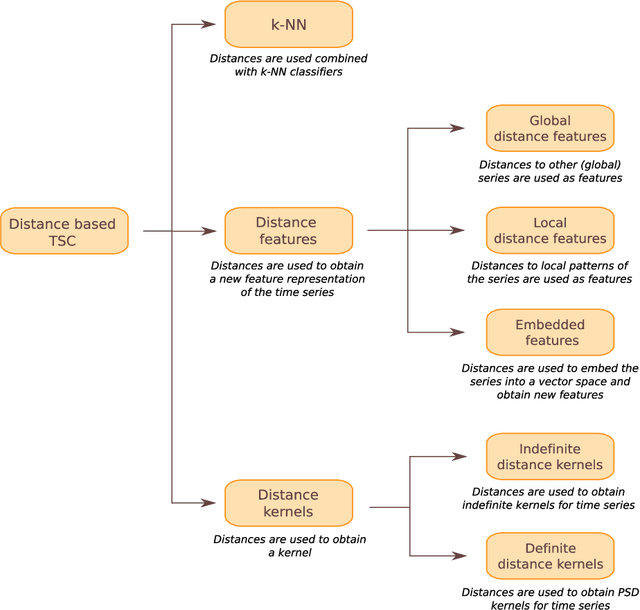

Time series classification is an increasing research topic due to the vast amount of time series data that are being created over a wide variety of fields. The particularity of the data makes it a challenging task and different approaches have been taken, including the distance based approach. 1-NN has been a widely used method within distance based time series classification due to it simplicity but still good performance. However, its supremacy may be attributed to being able to use specific distances for time series within the classification process and not to the classifier itself. With the aim of exploiting these distances within more complex classifiers, new approaches have arisen in the past few years that are competitive or which outperform the 1-NN based approaches. In some cases, these new methods use the distance measure to transform the series into feature vectors, bridging the gap between time series and traditional classifiers. In other cases, the distances are employed to obtain a time series kernel and enable the use of kernel methods for time series classification. One of the main challenges is that a kernel function must be positive semi-definite, a matter that is also addressed within this review. The presented review includes a taxonomy of all those methods that aim to classify time series using a distance based approach, as well as a discussion of the strengths and weaknesses of each method.