 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Fair Comparison and Realistic Design and Evaluation Framework of Android Malware Detectors
Paper and Code


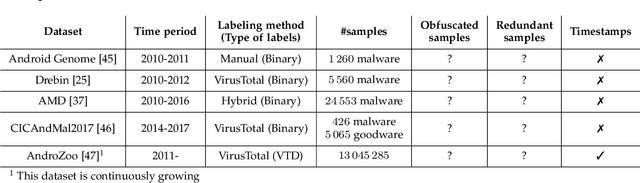
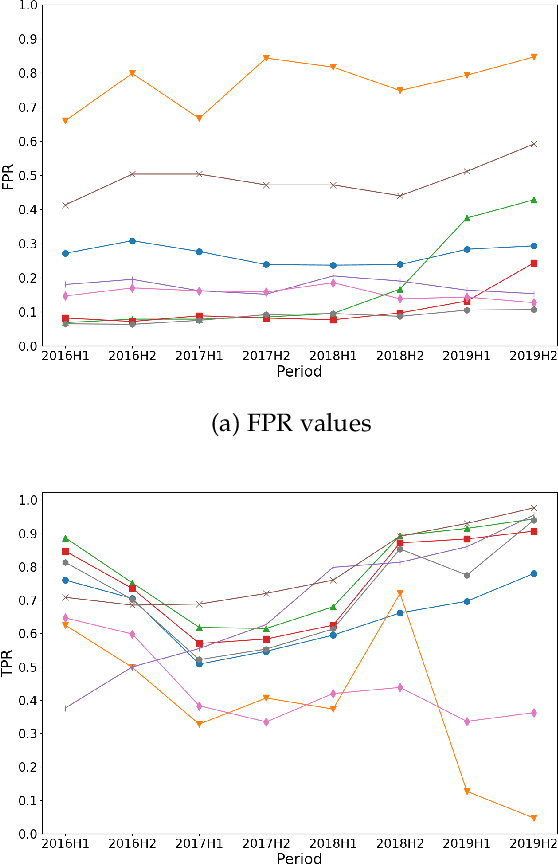
As in other cybersecurity areas, machine learning (ML) techniques have emerged as a promising solution to detect Android malware. In this sense, many proposals employing a variety of algorithms and feature sets have been presented to date, often reporting impresive detection performances. However, the lack of reproducibility and the absence of a standard evaluation framework make these proposals difficult to compare. In this paper, we perform an analysis of 10 influential research works on Android malware detection using a common evaluation framework. We have identified five factors that, if not taken into account when creating datasets and designing detectors, significantly affect the trained ML models and their performances. In particular, we analyze the effect of (1) the presence of duplicated samples, (2) label (goodware/greyware/malware) attribution, (3) class imbalance, (4) the presence of apps that use evasion techniques and, (5) the evolution of apps. Based on this extensive experimentation, we conclude that the studied ML-based detectors have been evaluated optimistically, which justifies the good published results. Our findings also highlight that it is imperative to generate realistic datasets, taking into account the factors mentioned above, to enable the design and evaluation of better solutions for Android malware detection.