 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Population-Based Architectures for Neural Combinatorial Optimization
Jan 13, 2026Neural Combinatorial Optimization (NCO) has mostly focused on learning policies, typically neural networks, that operate on a single candidate solution at a time, either by constructing one from scratch or iteratively improving it. In contrast, decades of work in metaheuristics have shown that maintaining and evolving populations of solutions improves robustness and exploration, and often leads to stronger performance. To close this gap, we study how to make NCO explicitly population-based by learning policies that act on sets of candidate solutions. We first propose a simple taxonomy of population awareness levels and use it to highlight two key design challenges: (i) how to represent a whole population inside a neural network, and (ii) how to learn population dynamics that balance intensification (generating good solutions) and diversification (maintaining variety). We make these ideas concrete with two complementary tools: one that improves existing solutions using information shared across the whole population, and the other generates new candidate solutions that explicitly balance being high-quality with diversity. Experimental results on Maximum Cut and Maximum Independent Set indicate that incorporating population structure is advantageous for learned optimization methods and opens new connections between NCO and classical population-based search.
MARCO: A Memory-Augmented Reinforcement Framework for Combinatorial Optimization
Aug 05, 2024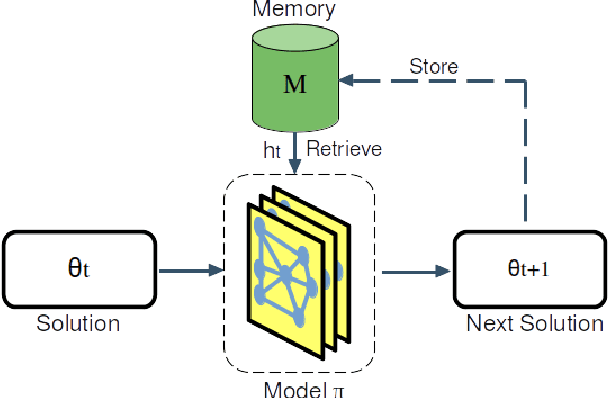

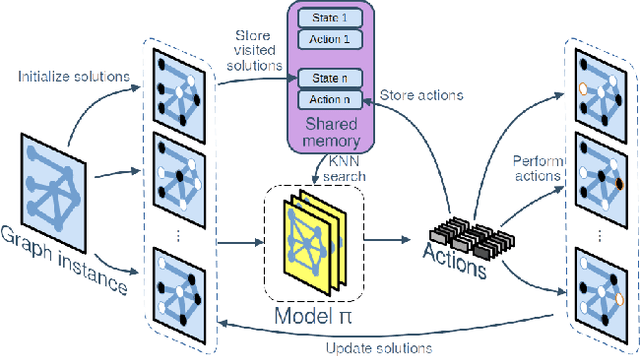
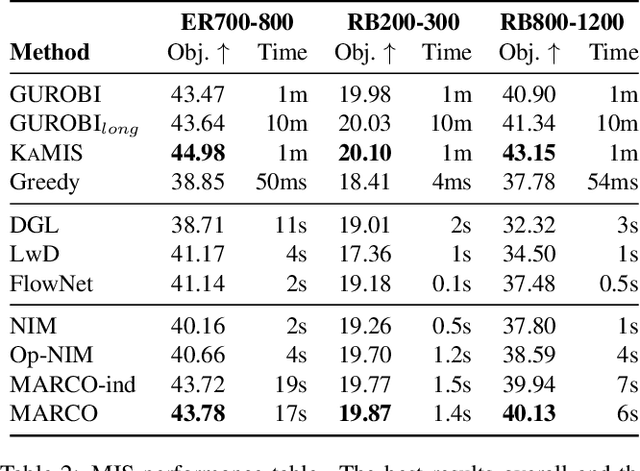
Neural Combinatorial Optimization (NCO) is an emerging domain where deep learning techniques are employed to address combinatorial optimization problems as a standalone solver. Despite their potential, existing NCO methods often suffer from inefficient search space exploration, frequently leading to local optima entrapment or redundant exploration of previously visited states. This paper introduces a versatile framework, referred to as Memory-Augmented Reinforcement for Combinatorial Optimization (MARCO), that can be used to enhance both constructive and improvement methods in NCO through an innovative memory module. MARCO stores data collected throughout the optimization trajectory and retrieves contextually relevant information at each state. This way, the search is guided by two competing criteria: making the best decision in terms of the quality of the solution and avoiding revisiting already explored solutions. This approach promotes a more efficient use of the available optimization budget. Moreover, thanks to the parallel nature of NCO models, several search threads can run simultaneously, all sharing the same memory module, enabling an efficient collaborative exploration. Empirical evaluations, carried out on the maximum cut, maximum independent set and travelling salesman problems, reveal that the memory module effectively increases the exploration, enabling the model to discover diverse, higher-quality solutions. MARCO achieves good performance in a low computational cost, establishing a promising new direction in the field of NCO.
Craftium: An Extensible Framework for Creating Reinforcement Learning Environments
Jul 04, 2024Most Reinforcement Learning (RL) environments are created by adapting existing physics simulators or video games. However, they usually lack the flexibility required for analyzing specific characteristics of RL methods often relevant to research. This paper presents Craftium, a novel framework for exploring and creating rich 3D visual RL environments that builds upon the Minetest game engine and the popular Gymnasium API. Minetest is built to be extended and can be used to easily create voxel-based 3D environments (often similar to Minecraft), while Gymnasium offers a simple and common interface for RL research. Craftium provides a platform that allows practitioners to create fully customized environments to suit their specific research requirements, ranging from simple visual tasks to infinite and procedurally generated worlds. We also provide five ready-to-use environments for benchmarking and as examples of how to develop new ones. The code and documentation are available at https://github.com/mikelma/craftium/.
Time to Stop and Think: What kind of research do we want to do?
Feb 13, 2024Experimentation is an intrinsic part of research in artificial intelligence since it allows for collecting quantitative observations, validating hypotheses, and providing evidence for their reformulation. For that reason, experimentation must be coherent with the purposes of the research, properly addressing the relevant questions in each case. Unfortunately, the literature is full of works whose experimentation is neither rigorous nor convincing, oftentimes designed to support prior beliefs rather than answering the relevant research questions. In this paper, we focus on the field of metaheuristic optimization, since it is our main field of work, and it is where we have observed the misconduct that has motivated this letter. Even if we limit the focus of this manuscript to the experimental part of the research, our main goal is to sew the seed of sincere critical assessment of our work, sparking a reflection process both at the individual and the community level. Such a reflection process is too complex and extensive to be tackled as a whole. Therefore, to bring our feet to the ground, we will include in this document our reflections about the role of experimentation in our work, discussing topics such as the use of benchmark instances vs instance generators, or the statistical assessment of empirical results. That is, all the statements included in this document are personal views and opinions, which can be shared by others or not. Certainly, having different points of view is the basis to establish a good discussion process.
Doubly Stochastic Matrix Models for Estimation of Distribution Algorithms
Apr 05, 2023


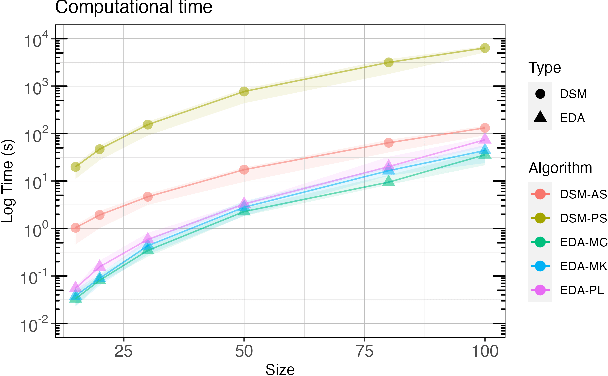
Problems with solutions represented by permutations are very prominent in combinatorial optimization. Thus, in recent decades, a number of evolutionary algorithms have been proposed to solve them, and among them, those based on probability models have received much attention. In that sense, most efforts have focused on introducing algorithms that are suited for solving ordering/ranking nature problems. However, when it comes to proposing probability-based evolutionary algorithms for assignment problems, the works have not gone beyond proposing simple and in most cases univariate models. In this paper, we explore the use of Doubly Stochastic Matrices (DSM) for optimizing matching and assignment nature permutation problems. To that end, we explore some learning and sampling methods to efficiently incorporate DSMs within the picture of evolutionary algorithms. Specifically, we adopt the framework of estimation of distribution algorithms and compare DSMs to some existing proposals for permutation problems. Conducted preliminary experiments on instances of the quadratic assignment problem validate this line of research and show that DSMs may obtain very competitive results, while computational cost issues still need to be further investigated.
Neural Improvement Heuristics for Preference Ranking
Jun 01, 2022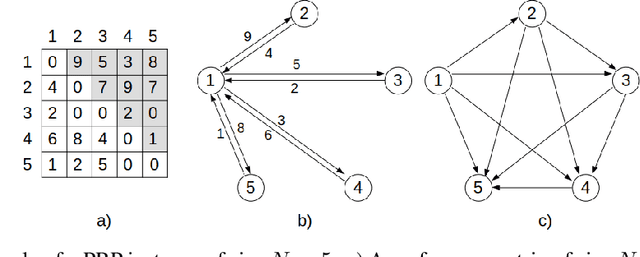
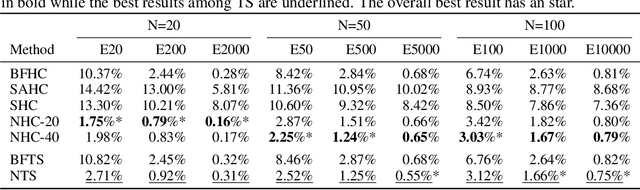
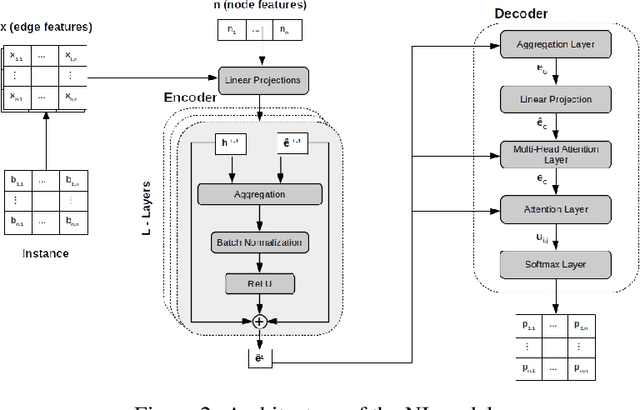
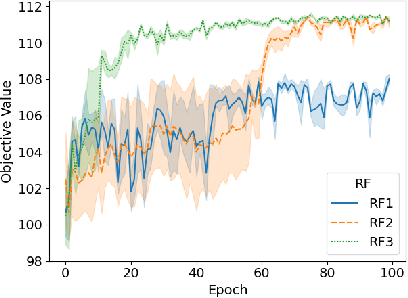
In recent years, Deep Learning based methods have been a revolution in the field of combinatorial optimization. They learn to approximate solutions and constitute an interesting choice when dealing with repetitive problems drawn from similar distributions. Most effort has been devoted to investigating neural constructive methods, while the works that propose neural models to iteratively improve a candidate solution are less frequent. In this paper, we present a Neural Improvement (NI) model for graph-based combinatorial problems that, given an instance and a candidate solution, encodes the problem information by means of edge features. Our model proposes a modification on the pairwise precedence of items to increase the quality of the solution. We demonstrate the practicality of the model by applying it as the building block of a Neural Hill Climber and other trajectory-based methods. The algorithms are used to solve the Preference Ranking Problem and results show that they outperform conventional alternatives in simulated and real-world data. Conducted experiments also reveal that the proposed model can be a milestone in the development of efficiently guided trajectory-based optimization algorithms.
Neural Combinatorial Optimization: a New Player in the Field
May 03, 2022
Neural Combinatorial Optimization attempts to learn good heuristics for solving a set of problems using Neural Network models and Reinforcement Learning. Recently, its good performance has encouraged many practitioners to develop neural architectures for a wide variety of combinatorial problems. However, the incorporation of such algorithms in the conventional optimization framework has raised many questions related to their performance and the experimental comparison with other methods such as exact algorithms, heuristics and metaheuristics. This paper presents a critical analysis on the incorporation of algorithms based on neural networks into the classical combinatorial optimization framework. Subsequently, a comprehensive study is carried out to analyse the fundamental aspects of such algorithms, including performance, transferability, computational cost and generalization to larger-sized instances. To that end, we select the Linear Ordering Problem as a case of study, an NP-hard problem, and develop a Neural Combinatorial Optimization model to optimize it. Finally, we discuss how the analysed aspects apply to a general learning framework, and suggest new directions for future work in the area of Neural Combinatorial Optimization algorithms.
Comparing two samples through stochastic dominance: a graphical approach
Mar 15, 2022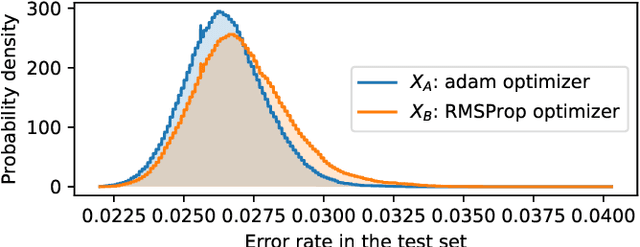
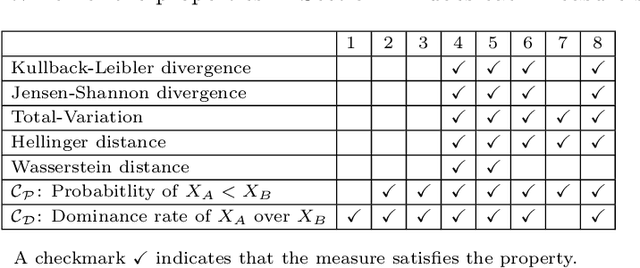
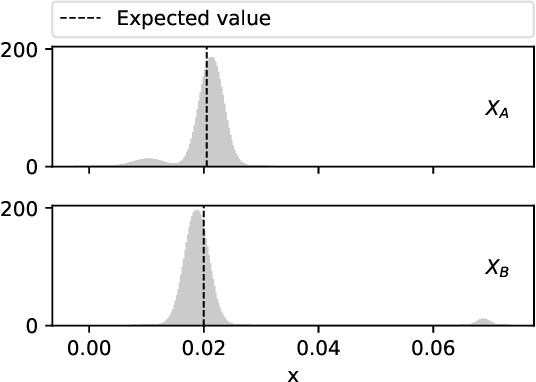
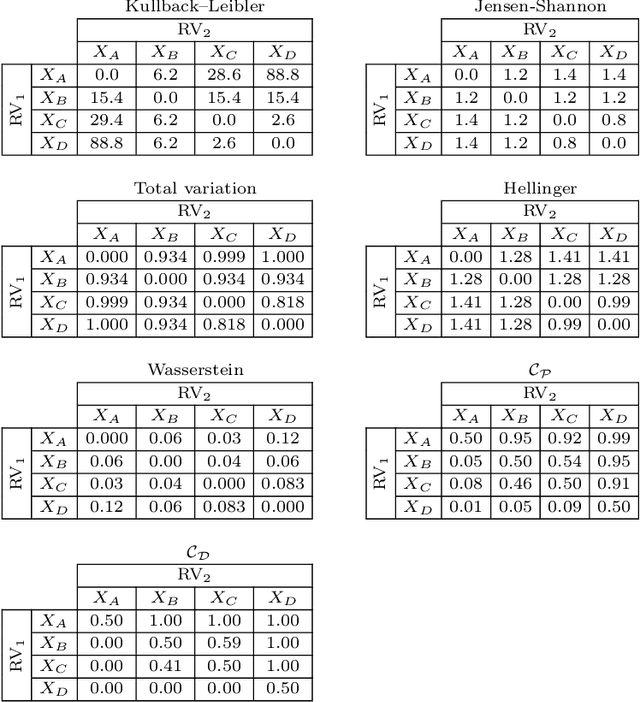
Non-deterministic measurements are common in real-world scenarios: the performance of a stochastic optimization algorithm or the total reward of a reinforcement learning agent in a chaotic environment are just two examples in which unpredictable outcomes are common. These measures can be modeled as random variables and compared among each other via their expected values or more sophisticated tools such as null hypothesis statistical tests. In this paper, we propose an alternative framework to visually compare two samples according to their estimated cumulative distribution functions. First, we introduce a dominance measure for two random variables that quantifies the proportion in which the cumulative distribution function of one of the random variables scholastically dominates the other one. Then, we present a graphical method that decomposes in quantiles i) the proposed dominance measure and ii) the probability that one of the random variables takes lower values than the other. With illustrative purposes, we re-evaluate the experimentation of an already published work with the proposed methodology and we show that additional conclusions (missed by the rest of the methods) can be inferred. Additionally, the software package RVCompare was created as a convenient way of applying and experimenting with the proposed framework.
Constrained Combinatorial Optimization with Reinforcement Learning
Jun 22, 2020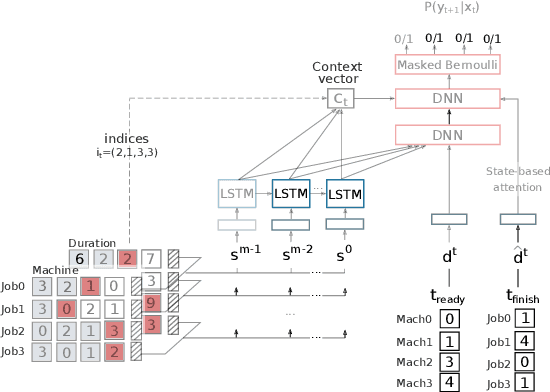
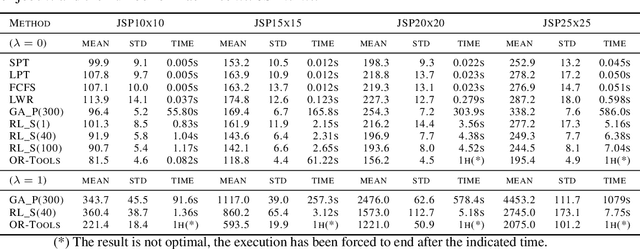

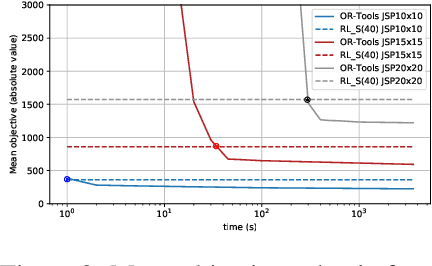
This paper presents a framework to tackle constrained combinatorial optimization problems using deep Reinforcement Learning (RL). To this end, we extend the Neural Combinatorial Optimization (NCO) theory in order to deal with constraints in its formulation. Notably, we propose defining constrained combinatorial problems as fully observable Constrained Markov Decision Processes (CMDP). In that context, the solution is iteratively constructed based on interactions with the environment. The model, in addition to the reward signal, relies on penalty signals generated from constraint dissatisfaction to infer a policy that acts as a heuristic algorithm. Moreover, having access to the complete state representation during the optimization process allows us to rely on memory-less architectures, enhancing the results obtained in previous sequence-to-sequence approaches. Conducted experiments on the constrained Job Shop and Resource Allocation problems prove the superiority of the proposal for computing rapid solutions when compared to classical heuristic, metaheuristic, and Constraint Programming (CP) solvers.
Kernels of Mallows Models under the Hamming Distance for solving the Quadratic Assignment Problem
Oct 19, 2019
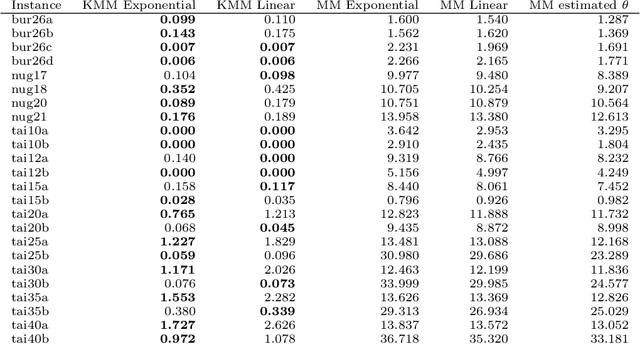
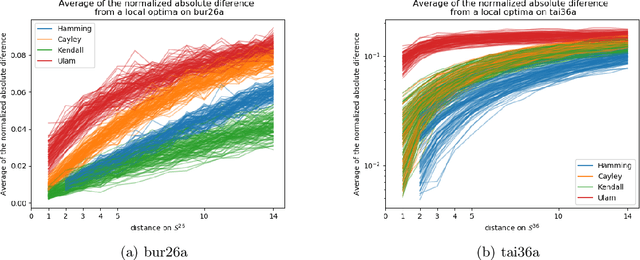
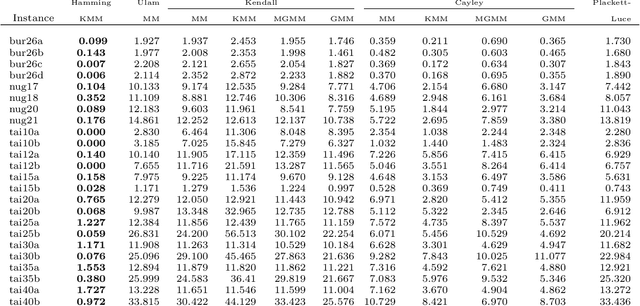
The Quadratic Assignment Problem (QAP) is a well-known permutation-based combinatorial optimization problem with real applications in industrial and logistics environments. Motivated by the challenge that this NP-hard problem represents, it has captured the attention of the evolutionary computation community for decades. As a result, a large number of algorithms have been proposed to optimize this algorithm. Among these, exact methods are only able to solve instances of size $n<40$, and thus, many heuristic and metaheuristic methods have been applied to the QAP. In this work, we follow this direction by approaching the QAP through Estimation of Distribution Algorithms (EDAs). Particularly, a non-parametric distance-based exponential probabilistic model is used. Based on the analysis of the characteristics of the QAP, and previous work in the area, we introduce Kernels of Mallows Model under the Hamming distance to the context of EDAs. Conducted experiments point out that the performance of the proposed algorithm in the QAP is superior to (i) the classical EDAs adapted to deal with the QAP, and also (ii) to the specific EDAs proposed in the literature to deal with permutation problems.