 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-Based Early-Stage Chronic Kidney Disease Screening using Explainable Machine Learning for Low-Resource Settings
Jan 03, 2026Early detection of chronic kidney disease (CKD) is essential for preventing progression to end-stage renal disease. However, existing screening tools - primarily developed using populations from high-income countries - often underperform in Bangladesh and South Asia, where risk profiles differ. Most of these tools rely on simple additive scoring functions and are based on data from patients with advanced-stage CKD. Consequently, they fail to capture complex interactions among risk factors and are limited in predicting early-stage CKD. Our objective was to develop and evaluate an explainable machine learning (ML) framework for community-based early-stage CKD screening for low-resource settings, tailored to the Bangladeshi and South Asian population context. We used a community-based dataset from Bangladesh, the first such CKD dataset in South and South Asia, and evaluated twelve ML classifiers across multiple feature domains. Ten complementary feature selection techniques were applied to identify robust, generalizable predictors. The final models were assessed using 10-fold cross-validation. External validation was conducted on three independent datasets from India, the UAE, and Bangladesh. SHAP (SHapley Additive exPlanations) was used to provide model explainability. An ML model trained on an RFECV-selected feature subset achieved a balanced accuracy of 90.40%, whereas minimal non-pathology-test features demonstrated excellent predictive capability with a balanced accuracy of 89.23%, often outperforming larger or full feature sets. Compared with existing screening tools, the proposed models achieved substantially higher accuracy and sensitivity while requiring fewer and more accessible inputs. External validation confirmed strong generalizability with 78% to 98% sensitivity. SHAP interpretation identified clinically meaningful predictors consistent with established CKD risk factors.
BenSParX: A Robust Explainable Machine Learning Framework for Parkinson's Disease Detection from Bengali Conversational Speech
May 18, 2025Parkinson's disease (PD) poses a growing global health challenge, with Bangladesh experiencing a notable rise in PD-related mortality. Early detection of PD remains particularly challenging in resource-constrained settings, where voice-based analysis has emerged as a promising non-invasive and cost-effective alternative. However, existing studies predominantly focus on English or other major languages; notably, no voice dataset for PD exists for Bengali - posing a significant barrier to culturally inclusive and accessible healthcare solutions. Moreover, most prior studies employed only a narrow set of acoustic features, with limited or no hyperparameter tuning and feature selection strategies, and little attention to model explainability. This restricts the development of a robust and generalizable machine learning model. To address this gap, we present BenSparX, the first Bengali conversational speech dataset for PD detection, along with a robust and explainable machine learning framework tailored for early diagnosis. The proposed framework incorporates diverse acoustic feature categories, systematic feature selection methods, and state-of-the-art machine learning algorithms with extensive hyperparameter optimization. Furthermore, to enhance interpretability and trust in model predictions, the framework incorporates SHAP (SHapley Additive exPlanations) analysis to quantify the contribution of individual acoustic features toward PD detection. Our framework achieves state-of-the-art performance, yielding an accuracy of 95.77%, F1 score of 95.57%, and AUC-ROC of 0.982. We further externally validated our approach by applying the framework to existing PD datasets in other languages, where it consistently outperforms state-of-the-art approaches. To facilitate further research and reproducibility, the dataset has been made publicly available at https://github.com/Riad071/BenSParX.
Virtual Reality and Artificial Intelligence as Psychological Countermeasures in Space and Other Isolated and Confined Environments: A Scoping Review
Apr 02, 2025
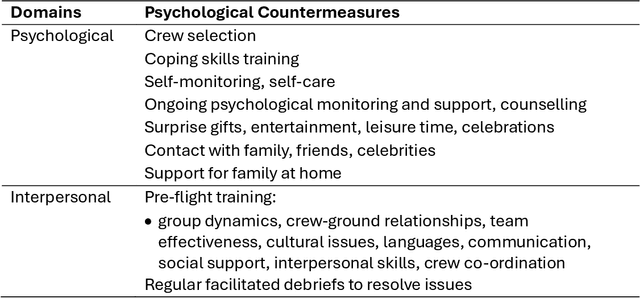


Spaceflight is an isolated and confined environment (ICE) that exposes astronauts to psychological hazards, such as stress, danger, and monotony. Virtual reality (VR) and artificial intelligence (AI) technologies can serve as psychological countermeasures as they can digitally simulate immersive environments, interactive companions, and therapeutic experiences. Our study employs a scoping literature review approach to identify what is currently known about the use and effectiveness of VR and AI-based interventions as psychological countermeasures to improve mood or emotional states in adults in space or other ICEs. Additionally, this review aimed to identify gaps in the knowledge base and whether a systematic review with meta-analysis was warranted. The review included studies where the intervention was used or intended for use in space or other extraterrestrial environments (ICE). Our search strategy yielded 19 studies from 3390 records across seven major databases. All studies focused on VR-based interventions, with no eligible AI-based intervention studies found. VR interventions were found to be effective for relaxation and improving mood, emergency training, as an interactive communication platform, for comparing interior designs, and for enhancing exercise. There were improvements for measures of mood and emotion\n (e.g., anxiety and stress); however, user preferences varied, and some instances of cybersickness were reported. A systematic review with meta-analysis is not recommended due to the heterogeneity of results. There is significant scope for further research into the use of VR for a wider range of mood and emotion variables using standardised assessment instruments. Additionally, the potential application of AI as a psychological countermeasure warrants further investigation.
An Attention-Guided Deep Learning Approach for Classifying 39 Skin Lesion Types
Jan 10, 2025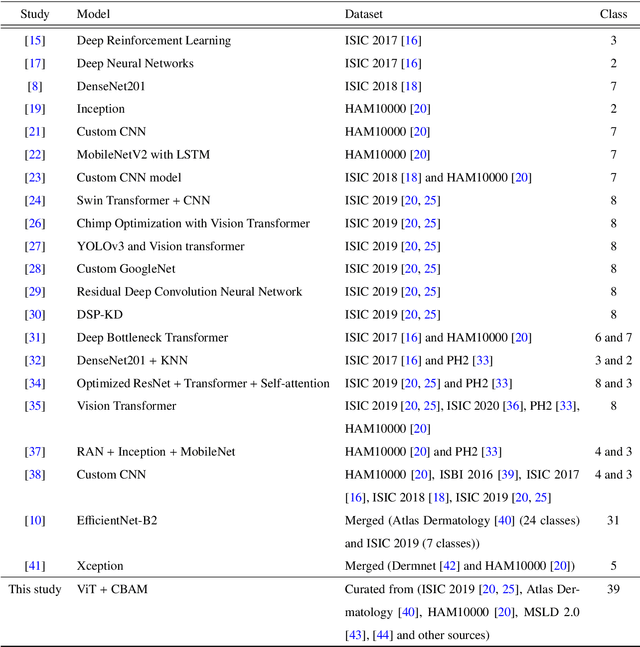



The skin, as the largest organ of the human body, is vulnerable to a diverse array of conditions collectively known as skin lesions, which encompass various dermatoses. Diagnosing these lesions presents significant challenges for medical practitioners due to the subtle visual differences that are often imperceptible to the naked eye. While not all skin lesions are life-threatening, certain types can act as early indicators of severe diseases, including skin cancers, underscoring the critical need for timely and accurate diagnostic methods. Deep learning algorithms have demonstrated remarkable potential in facilitating the early detection and prognosis of skin lesions. This study advances the field by curating a comprehensive and diverse dataset comprising 39 categories of skin lesions, synthesized from five publicly available datasets. Using this dataset, the performance of five state-of-the-art deep learning models -- MobileNetV2, Xception, InceptionV3, EfficientNetB1, and Vision Transformer - is rigorously evaluated. To enhance the accuracy and robustness of these models, attention mechanisms such as the Efficient Channel Attention (ECA) and the Convolutional Block Attention Module (CBAM) are incorporated into their architectures. Comprehensive evaluation across multiple performance metrics reveals that the Vision Transformer model integrated with CBAM outperforms others, achieving an accuracy of 93.46%, precision of 94%, recall of 93%, F1-score of 93%, and specificity of 93.67%. These results underscore the significant potential of the proposed system in supporting medical professionals with accurate and efficient prognostic tools for diagnosing a broad spectrum of skin lesions. The dataset and code used in this study can be found at https://github.com/akabircs/Skin-Lesions-Classification.
MHAFF: Multi-Head Attention Feature Fusion of CNN and Transformer for Cattle Identification
Jan 09, 2025



Convolutional Neural Networks (CNNs) have drawn researchers' attention to identifying cattle using muzzle images. However, CNNs often fail to capture long-range dependencies within the complex patterns of the muzzle. The transformers handle these challenges. This inspired us to fuse the strengths of CNNs and transformers in muzzle-based cattle identification. Addition and concatenation have been the most commonly used techniques for feature fusion. However, addition fails to preserve discriminative information, while concatenation results in an increase in dimensionality. Both methods are simple operations and cannot discover the relationships or interactions between fusing features. This research aims to overcome the issues faced by addition and concatenation. This research introduces a novel approach called Multi-Head Attention Feature Fusion (MHAFF) for the first time in cattle identification. MHAFF captures relations between the different types of fusing features while preserving their originality. The experiments show that MHAFF outperformed addition and concatenation techniques and the existing cattle identification methods in accuracy on two publicly available cattle datasets. MHAFF demonstrates excellent performance and quickly converges to achieve optimum accuracy of 99.88% and 99.52% in two cattle datasets simultaneously.
BeliN: A Novel Corpus for Bengali Religious News Headline Generation using Contextual Feature Fusion
Jan 02, 2025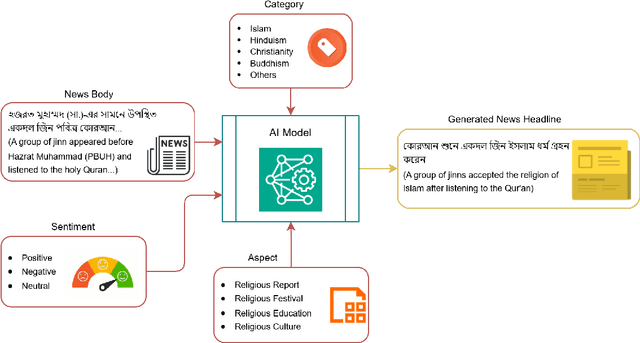
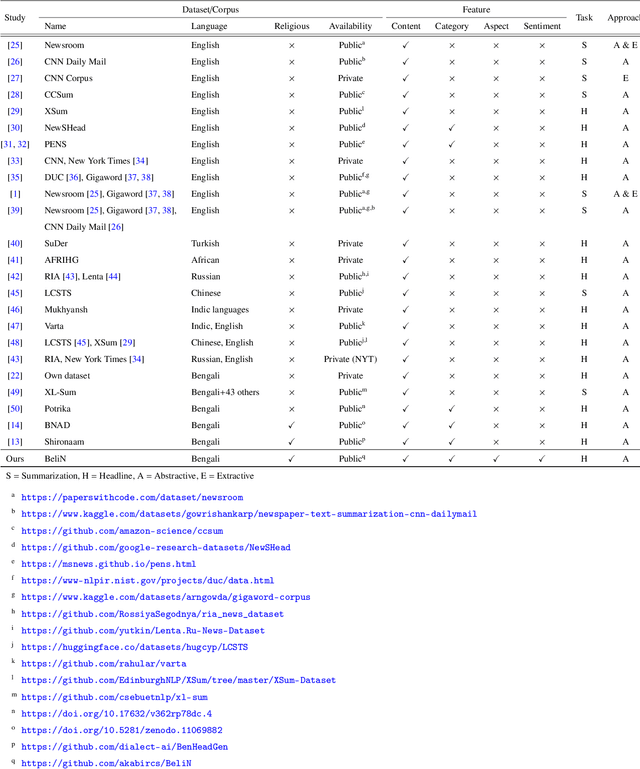

Automatic text summarization, particularly headline generation, remains a critical yet underexplored area for Bengali religious news. Existing approaches to headline generation typically rely solely on the article content, overlooking crucial contextual features such as sentiment, category, and aspect. This limitation significantly hinders their effectiveness and overall performance. This study addresses this limitation by introducing a novel corpus, BeliN (Bengali Religious News) - comprising religious news articles from prominent Bangladeshi online newspapers, and MultiGen - a contextual multi-input feature fusion headline generation approach. Leveraging transformer-based pre-trained language models such as BanglaT5, mBART, mT5, and mT0, MultiGen integrates additional contextual features - including category, aspect, and sentiment - with the news content. This fusion enables the model to capture critical contextual information often overlooked by traditional methods. Experimental results demonstrate the superiority of MultiGen over the baseline approach that uses only news content, achieving a BLEU score of 18.61 and ROUGE-L score of 24.19, compared to baseline approach scores of 16.08 and 23.08, respectively. These findings underscore the importance of incorporating contextual features in headline generation for low-resource languages. By bridging linguistic and cultural gaps, this research advances natural language processing for Bengali and other underrepresented languages. To promote reproducibility and further exploration, the dataset and implementation code are publicly accessible at https://github.com/akabircs/BeliN.
Robust COVID-19 Detection from Cough Sounds using Deep Neural Decision Tree and Forest: A Comprehensive Cross-Datasets Evaluation
Jan 02, 2025



This research presents a robust approach to classifying COVID-19 cough sounds using cutting-edge machine-learning techniques. Leveraging deep neural decision trees and deep neural decision forests, our methodology demonstrates consistent performance across diverse cough sound datasets. We begin with a comprehensive extraction of features to capture a wide range of audio features from individuals, whether COVID-19 positive or negative. To determine the most important features, we use recursive feature elimination along with cross-validation. Bayesian optimization fine-tunes hyper-parameters of deep neural decision tree and deep neural decision forest models. Additionally, we integrate the SMOTE during training to ensure a balanced representation of positive and negative data. Model performance refinement is achieved through threshold optimization, maximizing the ROC-AUC score. Our approach undergoes a comprehensive evaluation in five datasets: Cambridge, Coswara, COUGHVID, Virufy, and the combined Virufy with the NoCoCoDa dataset. Consistently outperforming state-of-the-art methods, our proposed approach yields notable AUC scores of 0.97, 0.98, 0.92, 0.93, 0.99, and 0.99 across the respective datasets. Merging all datasets into a combined dataset, our method, using a deep neural decision forest classifier, achieves an AUC of 0.97. Also, our study includes a comprehensive cross-datasets analysis, revealing demographic and geographic differences in the cough sounds associated with COVID-19. These differences highlight the challenges in transferring learned features across diverse datasets and underscore the potential benefits of dataset integration, improving generalizability and enhancing COVID-19 detection from audio signals.
From Lab to Pocket: A Novel Continual Learning-based Mobile Application for Screening COVID-19
Oct 16, 2024

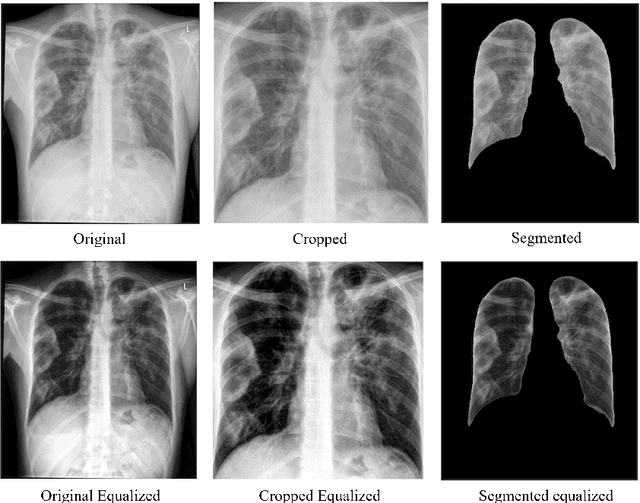

Artificial intelligence (AI) has emerged as a promising tool for predicting COVID-19 from medical images. In this paper, we propose a novel continual learning-based approach and present the design and implementation of a mobile application for screening COVID-19. Our approach demonstrates the ability to adapt to evolving datasets, including data collected from different locations or hospitals, varying virus strains, and diverse clinical presentations, without retraining from scratch. We have evaluated state-of-the-art continual learning methods for detecting COVID-19 from chest X-rays and selected the best-performing model for our mobile app. We evaluated various deep learning architectures to select the best-performing one as a foundation model for continual learning. Both regularization and memory-based methods for continual learning were tested, using different memory sizes to develop the optimal continual learning model for our app. DenseNet161 emerged as the best foundation model with 96.87\% accuracy, and Learning without Forgetting (LwF) was the top continual learning method with an overall performance of 71.99\%. The mobile app design considers both patient and doctor perspectives. It incorporates the continual learning DenseNet161 LwF model on a cloud server, enabling the model to learn from new instances of chest X-rays and their classifications as they are submitted. The app is designed, implemented, and evaluated to ensure it provides an efficient tool for COVID-19 screening. The app is available to download from https://github.com/DannyFGitHub/COVID-19PneumoCheckApp.
Self-DenseMobileNet: A Robust Framework for Lung Nodule Classification using Self-ONN and Stacking-based Meta-Classifier
Oct 16, 2024In this study, we propose a novel and robust framework, Self-DenseMobileNet, designed to enhance the classification of nodules and non-nodules in chest radiographs (CXRs). Our approach integrates advanced image standardization and enhancement techniques to optimize the input quality, thereby improving classification accuracy. To enhance predictive accuracy and leverage the strengths of multiple models, the prediction probabilities from Self-DenseMobileNet were transformed into tabular data and used to train eight classical machine learning (ML) models; the top three performers were then combined via a stacking algorithm, creating a robust meta-classifier that integrates their collective insights for superior classification performance. To enhance the interpretability of our results, we employed class activation mapping (CAM) to visualize the decision-making process of the best-performing model. Our proposed framework demonstrated remarkable performance on internal validation data, achieving an accuracy of 99.28\% using a Meta-Random Forest Classifier. When tested on an external dataset, the framework maintained strong generalizability with an accuracy of 89.40\%. These results highlight a significant improvement in the classification of CXRs with lung nodules.
Analysis of child development facts and myths using text mining techniques and classification models
Aug 23, 2024



The rapid dissemination of misinformation on the internet complicates the decision-making process for individuals seeking reliable information, particularly parents researching child development topics. This misinformation can lead to adverse consequences, such as inappropriate treatment of children based on myths. While previous research has utilized text-mining techniques to predict child abuse cases, there has been a gap in the analysis of child development myths and facts. This study addresses this gap by applying text mining techniques and classification models to distinguish between myths and facts about child development, leveraging newly gathered data from publicly available websites. The research methodology involved several stages. First, text mining techniques were employed to pre-process the data, ensuring enhanced accuracy. Subsequently, the structured data was analysed using six robust Machine Learning (ML) classifiers and one Deep Learning (DL) model, with two feature extraction techniques applied to assess their performance across three different training-testing splits. To ensure the reliability of the results, cross-validation was performed using both k-fold and leave-one-out methods. Among the classification models tested, Logistic Regression (LR) demonstrated the highest accuracy, achieving a 90% accuracy with the Bag-of-Words (BoW) feature extraction technique. LR stands out for its exceptional speed and efficiency, maintaining low testing time per statement (0.97 microseconds). These findings suggest that LR, when combined with BoW, is effective in accurately classifying child development information, thus providing a valuable tool for combating misinformation and assisting parents in making informed decisions.