 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Guided Deep Learning Approach for Classifying 39 Skin Lesion Types
Jan 10, 2025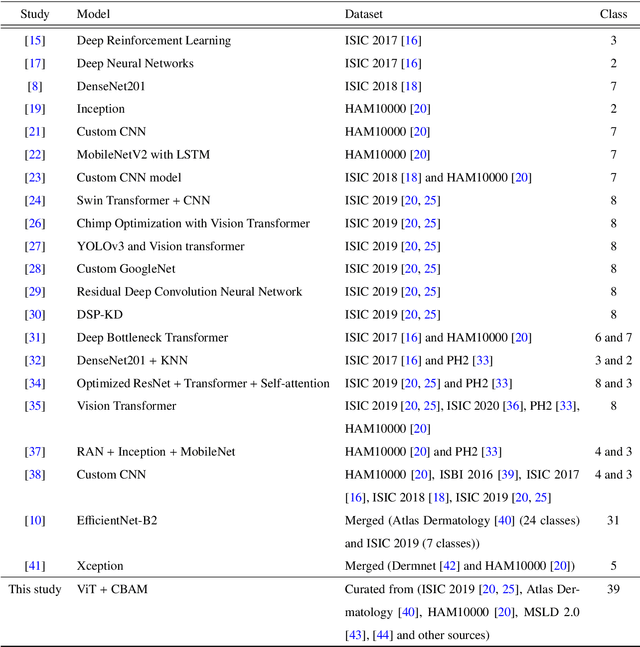



The skin, as the largest organ of the human body, is vulnerable to a diverse array of conditions collectively known as skin lesions, which encompass various dermatoses. Diagnosing these lesions presents significant challenges for medical practitioners due to the subtle visual differences that are often imperceptible to the naked eye. While not all skin lesions are life-threatening, certain types can act as early indicators of severe diseases, including skin cancers, underscoring the critical need for timely and accurate diagnostic methods. Deep learning algorithms have demonstrated remarkable potential in facilitating the early detection and prognosis of skin lesions. This study advances the field by curating a comprehensive and diverse dataset comprising 39 categories of skin lesions, synthesized from five publicly available datasets. Using this dataset, the performance of five state-of-the-art deep learning models -- MobileNetV2, Xception, InceptionV3, EfficientNetB1, and Vision Transformer - is rigorously evaluated. To enhance the accuracy and robustness of these models, attention mechanisms such as the Efficient Channel Attention (ECA) and the Convolutional Block Attention Module (CBAM) are incorporated into their architectures. Comprehensive evaluation across multiple performance metrics reveals that the Vision Transformer model integrated with CBAM outperforms others, achieving an accuracy of 93.46%, precision of 94%, recall of 93%, F1-score of 93%, and specificity of 93.67%. These results underscore the significant potential of the proposed system in supporting medical professionals with accurate and efficient prognostic tools for diagnosing a broad spectrum of skin lesions. The dataset and code used in this study can be found at https://github.com/akabircs/Skin-Lesions-Classification.
BeliN: A Novel Corpus for Bengali Religious News Headline Generation using Contextual Feature Fusion
Jan 02, 2025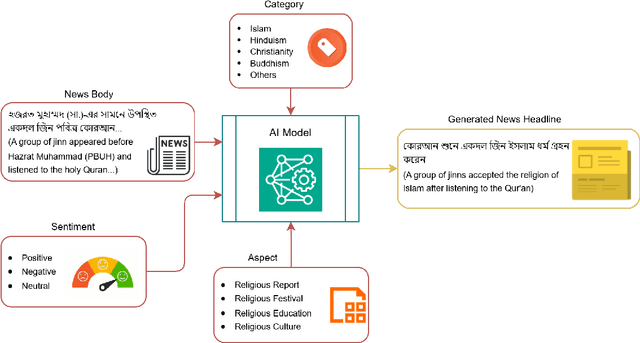
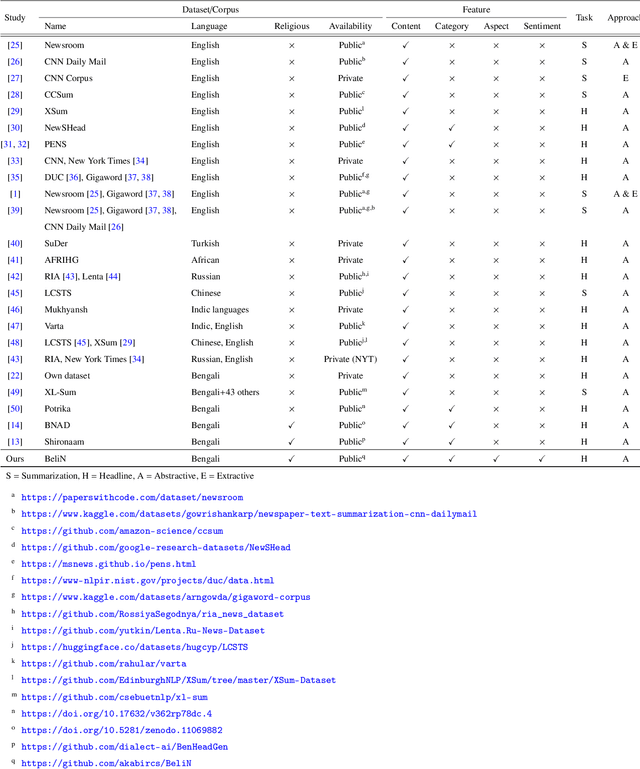
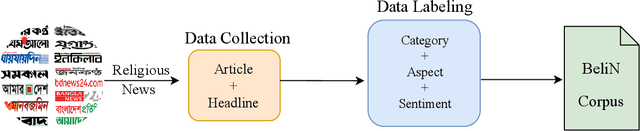

Automatic text summarization, particularly headline generation, remains a critical yet underexplored area for Bengali religious news. Existing approaches to headline generation typically rely solely on the article content, overlooking crucial contextual features such as sentiment, category, and aspect. This limitation significantly hinders their effectiveness and overall performance. This study addresses this limitation by introducing a novel corpus, BeliN (Bengali Religious News) - comprising religious news articles from prominent Bangladeshi online newspapers, and MultiGen - a contextual multi-input feature fusion headline generation approach. Leveraging transformer-based pre-trained language models such as BanglaT5, mBART, mT5, and mT0, MultiGen integrates additional contextual features - including category, aspect, and sentiment - with the news content. This fusion enables the model to capture critical contextual information often overlooked by traditional methods. Experimental results demonstrate the superiority of MultiGen over the baseline approach that uses only news content, achieving a BLEU score of 18.61 and ROUGE-L score of 24.19, compared to baseline approach scores of 16.08 and 23.08, respectively. These findings underscore the importance of incorporating contextual features in headline generation for low-resource languages. By bridging linguistic and cultural gaps, this research advances natural language processing for Bengali and other underrepresented languages. To promote reproducibility and further exploration, the dataset and implementation code are publicly accessible at https://github.com/akabircs/BeliN.