 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMAF-Net: Motion-Aware and Multi-Attention Fusion Network for Stroke Diagnosis
Apr 19, 2023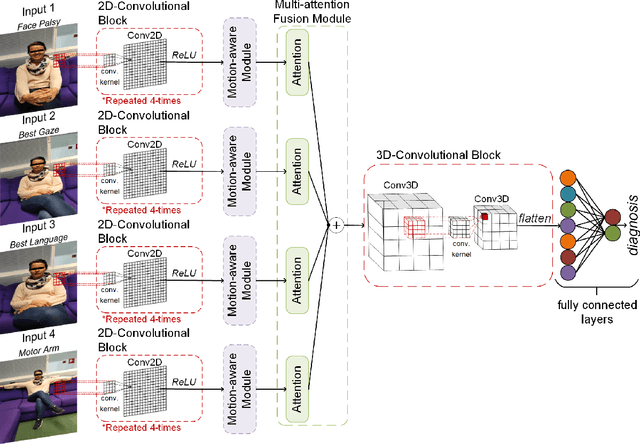
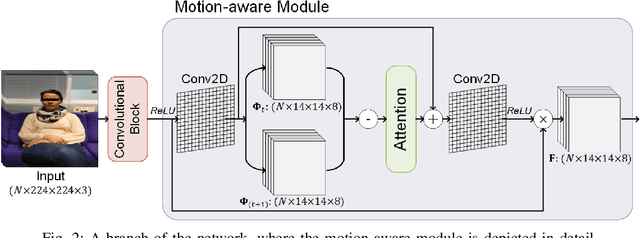
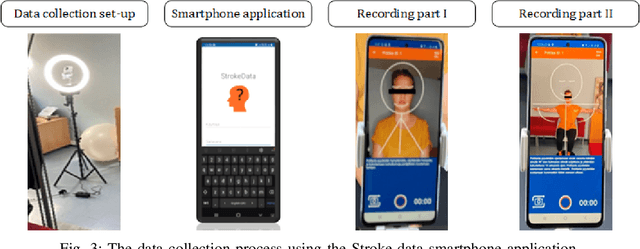
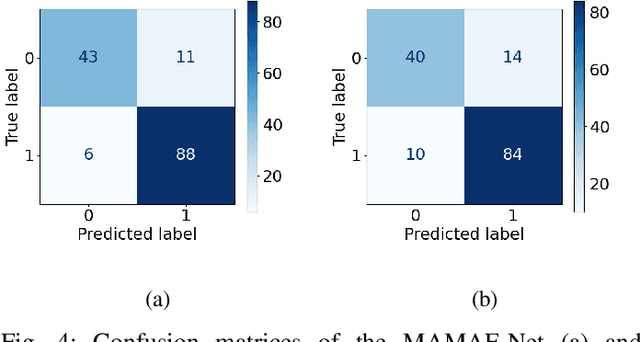
Stroke is a major cause of mortality and disability worldwide from which one in four people are in danger of incurring in their lifetime. The pre-hospital stroke assessment plays a vital role in identifying stroke patients accurately to accelerate further examination and treatment in hospitals. Accordingly, the National Institutes of Health Stroke Scale (NIHSS), Cincinnati Pre-hospital Stroke Scale (CPSS) and Face Arm Speed Time (F.A.S.T.) are globally known tests for stroke assessment. However, the validity of these tests is skeptical in the absence of neurologists. Therefore, in this study, we propose a motion-aware and multi-attention fusion network (MAMAF-Net) that can detect stroke from multimodal examination videos. Contrary to other studies on stroke detection from video analysis, our study for the first time proposes an end-to-end solution from multiple video recordings of each subject with a dataset encapsulating stroke, transient ischemic attack (TIA), and healthy controls. The proposed MAMAF-Net consists of motion-aware modules to sense the mobility of patients, attention modules to fuse the multi-input video data, and 3D convolutional layers to perform diagnosis from the attention-based extracted features. Experimental results over the collected StrokeDATA dataset show that the proposed MAMAF-Net achieves a successful detection of stroke with 93.62% sensitivity and 95.33% AUC score.
Facial Expression Analysis Using Decomposed Multiscale Spatiotemporal Networks
Mar 21, 2022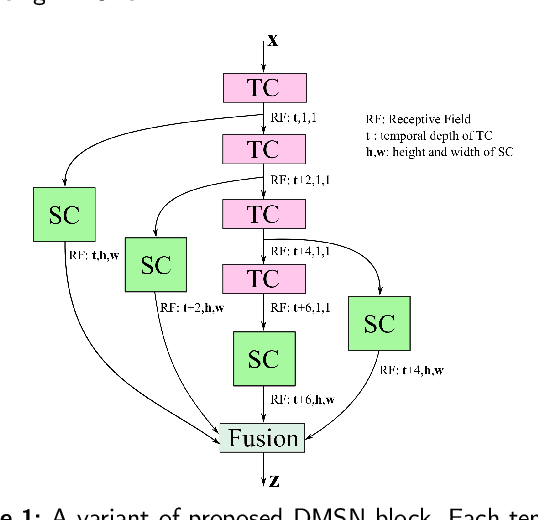
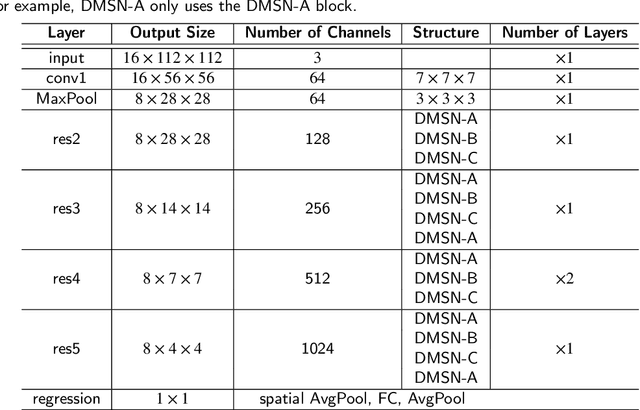
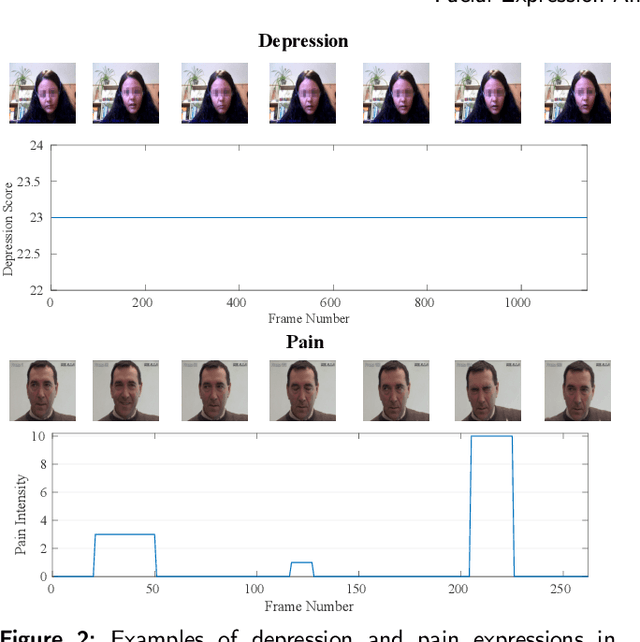
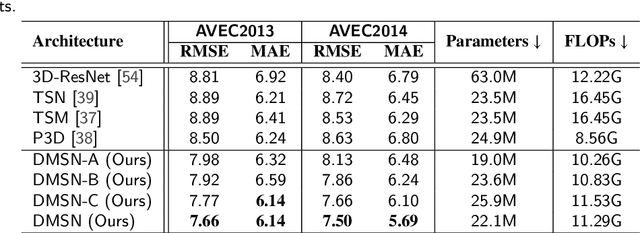
Video-based analysis of facial expressions has been increasingly applied to infer health states of individuals, such as depression and pain. Among the existing approaches, deep learning models composed of structures for multiscale spatiotemporal processing have shown strong potential for encoding facial dynamics. However, such models have high computational complexity, making for a difficult deployment of these solutions. To address this issue, we introduce a new technique to decompose the extraction of multiscale spatiotemporal features. Particularly, a building block structure called Decomposed Multiscale Spatiotemporal Network (DMSN) is presented along with three variants: DMSN-A, DMSN-B, and DMSN-C blocks. The DMSN-A block generates multiscale representations by analyzing spatiotemporal features at multiple temporal ranges, while the DMSN-B block analyzes spatiotemporal features at multiple ranges, and the DMSN-C block analyzes spatiotemporal features at multiple spatial sizes. Using these variants, we design our DMSN architecture which has the ability to explore a variety of multiscale spatiotemporal features, favoring the adaptation to different facial behaviors. Our extensive experiments on challenging datasets show that the DMSN-C block is effective for depression detection, whereas the DMSN-A block is efficient for pain estimation. Results also indicate that our DMSN architecture provides a cost-effective solution for expressions that range from fewer facial variations over time, as in depression detection, to greater variations, as in pain estimation.
Iterative Learning for Instance Segmentation
Feb 18, 2022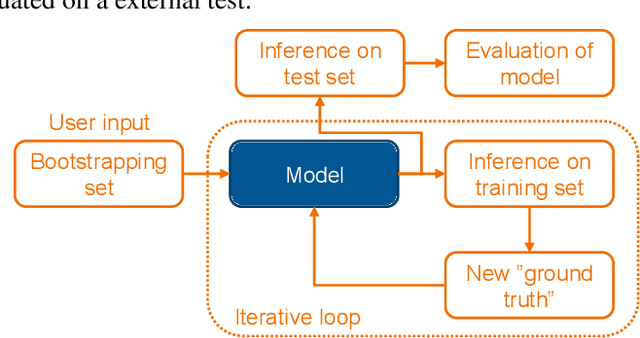
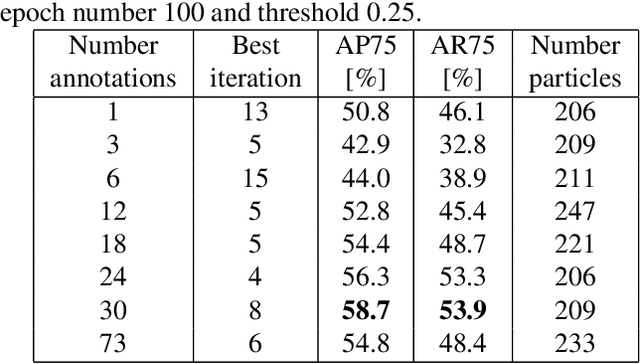

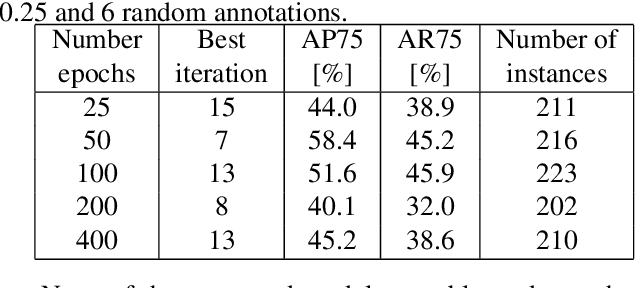
Instance segmentation is a computer vision task where separate objects in an image are detected and segmented. State-of-the-art deep neural network models require large amounts of labeled data in order to perform well in this task. Making these annotations is time-consuming. We propose for the first time, an iterative learning and annotation method that is able to detect, segment and annotate instances in datasets composed of multiple similar objects. The approach requires minimal human intervention and needs only a bootstrapping set containing very few annotations. Experiments on two different datasets show the validity of the approach in different applications related to visual inspection.
Transport Triggered Array Processor for Vision Applications
Jun 10, 2019


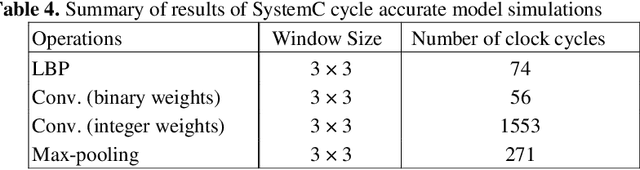
Low-level sensory data processing in many Internet-of-Things (IoT) devices pursue energy efficiency by utilizing sleep modes or slowing the clocking to the minimum. To curb the share of stand-by power dissipation in those designs, near-threshold/sub-threshold operational points or ultra-low-leakage processes in fabrication are employed. Those limit the clocking rates significantly, reducing the computing throughputs of individual processing cores. In this contribution we explore compensating for the performance loss of operating in near-threshold region (Vdd =0.6V) through massive parallelization. Benefits of near-threshold operation and massive parallelism are optimum energy consumption per instruction operation and minimized memory roundtrips, respectively. The Processing Elements (PE) of the design are based on Transport Triggered Architecture. The fine grained programmable parallel solution allows for fast and efficient computation of learnable low-level features (e.g. local binary descriptors and convolutions). Other operations, including Max-pooling have also been implemented. The programmable design achieves excellent energy efficiency for Local Binary Patterns computations.