 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
Apr 04, 2022
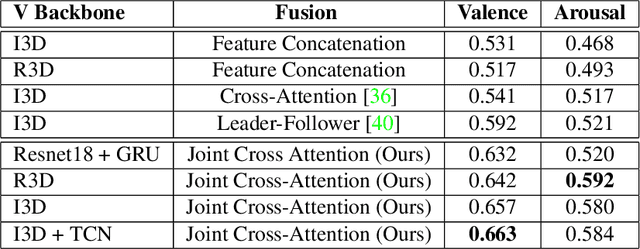
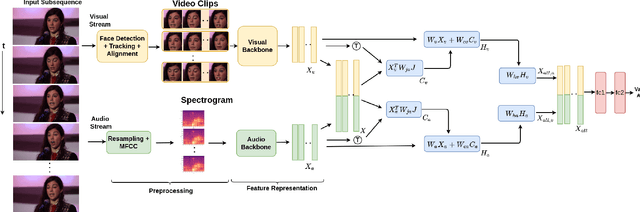
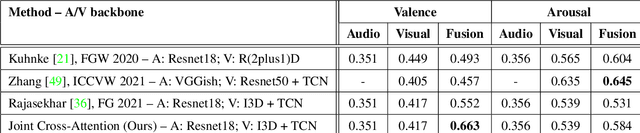
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.
Facial Expression Analysis Using Decomposed Multiscale Spatiotemporal Networks
Mar 21, 2022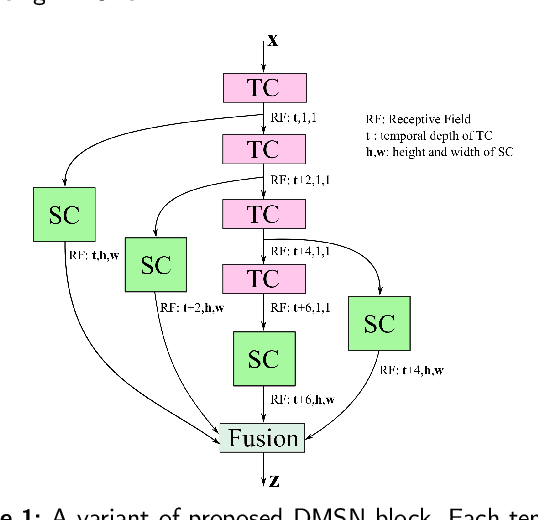
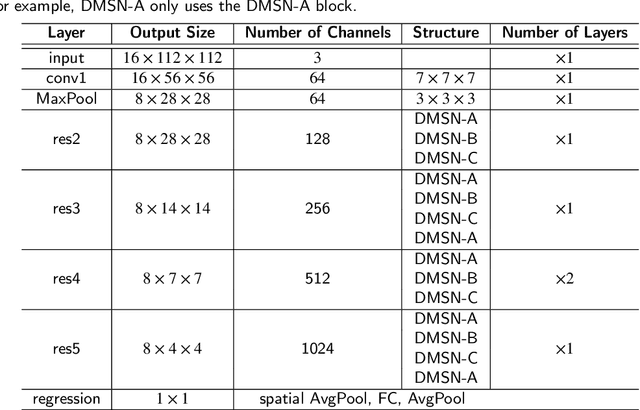
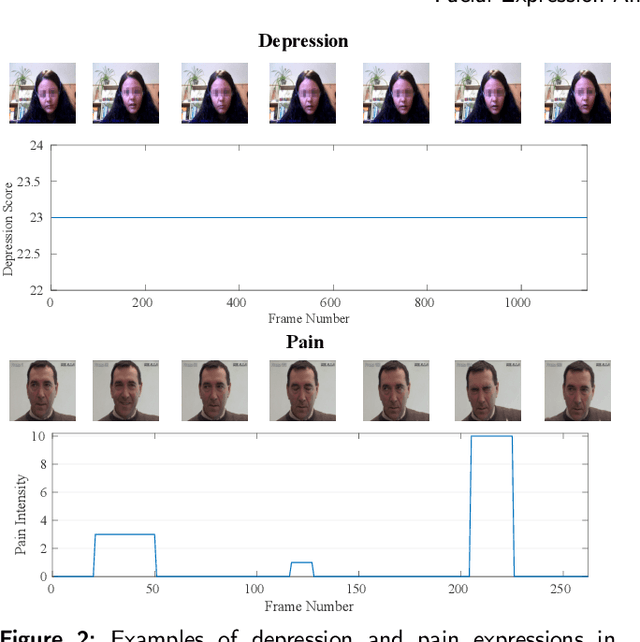
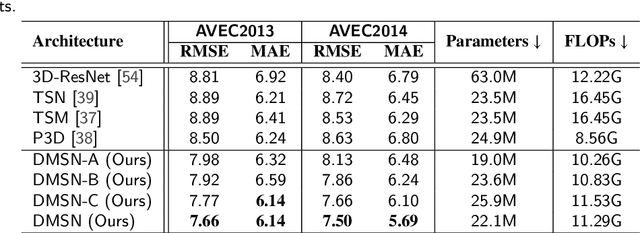
Video-based analysis of facial expressions has been increasingly applied to infer health states of individuals, such as depression and pain. Among the existing approaches, deep learning models composed of structures for multiscale spatiotemporal processing have shown strong potential for encoding facial dynamics. However, such models have high computational complexity, making for a difficult deployment of these solutions. To address this issue, we introduce a new technique to decompose the extraction of multiscale spatiotemporal features. Particularly, a building block structure called Decomposed Multiscale Spatiotemporal Network (DMSN) is presented along with three variants: DMSN-A, DMSN-B, and DMSN-C blocks. The DMSN-A block generates multiscale representations by analyzing spatiotemporal features at multiple temporal ranges, while the DMSN-B block analyzes spatiotemporal features at multiple ranges, and the DMSN-C block analyzes spatiotemporal features at multiple spatial sizes. Using these variants, we design our DMSN architecture which has the ability to explore a variety of multiscale spatiotemporal features, favoring the adaptation to different facial behaviors. Our extensive experiments on challenging datasets show that the DMSN-C block is effective for depression detection, whereas the DMSN-A block is efficient for pain estimation. Results also indicate that our DMSN architecture provides a cost-effective solution for expressions that range from fewer facial variations over time, as in depression detection, to greater variations, as in pain estimation.