 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Stochastic Teacher Representations Using Student-Guided Knowledge Distillation
Apr 19, 2025Advances in self-distillation have shown that when knowledge is distilled from a teacher to a student using the same deep learning (DL) architecture, the student performance can surpass the teacher particularly when the network is overparameterized and the teacher is trained with early stopping. Alternatively, ensemble learning also improves performance, although training, storing, and deploying multiple models becomes impractical as the number of models grows. Even distilling an ensemble to a single student model or weight averaging methods first requires training of multiple teacher models and does not fully leverage the inherent stochasticity for generating and distilling diversity in DL models. These constraints are particularly prohibitive in resource-constrained or latency-sensitive applications such as wearable devices. This paper proposes to train only one model and generate multiple diverse teacher representations using distillation-time dropout. However, generating these representations stochastically leads to noisy representations that are misaligned with the learned task. To overcome this problem, a novel stochastic self-distillation (SSD) training strategy is introduced for filtering and weighting teacher representation to distill from task-relevant representations only, using student-guided knowledge distillation (SGKD). The student representation at each distillation step is used as authority to guide the distillation process. Experimental results on real-world affective computing, wearable/biosignal datasets from the UCR Archive, the HAR dataset, and image classification datasets show that the proposed SSD method can outperform state-of-the-art methods without increasing the model size at both training and testing time, and incurs negligible computational complexity compared to state-of-the-art ensemble learning and weight averaging methods.
Distilling Privileged Multimodal Information for Expression Recognition using Optimal Transport
Jan 27, 2024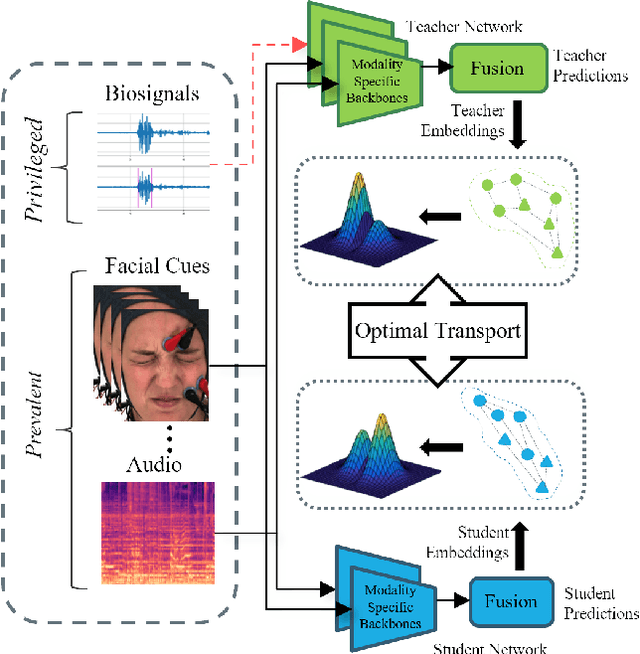
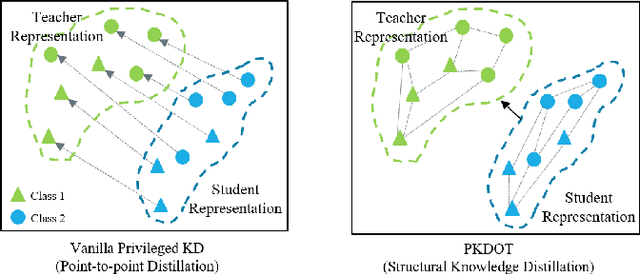
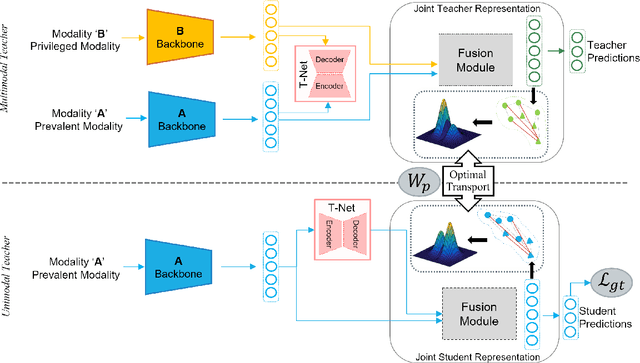
Multimodal affect recognition models have reached remarkable performance in the lab environment due to their ability to model complementary and redundant semantic information. However, these models struggle in the wild, mainly because of the unavailability or quality of modalities used for training. In practice, only a subset of the training-time modalities may be available at test time. Learning with privileged information (PI) enables deep learning models (DL) to exploit data from additional modalities only available during training. State-of-the-art knowledge distillation (KD) methods have been proposed to distill multiple teacher models (each trained on a modality) to a common student model. These privileged KD methods typically utilize point-to-point matching and have no explicit mechanism to capture the structural information in the teacher representation space formed by introducing the privileged modality. We argue that encoding this same structure in the student space may lead to enhanced student performance. This paper introduces a new structural KD mechanism based on optimal transport (OT), where entropy-regularized OT distills the structural dark knowledge. Privileged KD with OT (PKDOT) method captures the local structures in the multimodal teacher representation by calculating a cosine similarity matrix and selects the top-k anchors to allow for sparse OT solutions, resulting in a more stable distillation process. Experiments were performed on two different problems: pain estimation on the Biovid dataset (ordinal classification) and arousal-valance prediction on the Affwild2 dataset (regression). Results show that the proposed method can outperform state-of-the-art privileged KD methods on these problems. The diversity of different modalities and fusion architectures indicates that the proposed PKDOT method is modality and model-agnostic.
A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
Apr 04, 2022
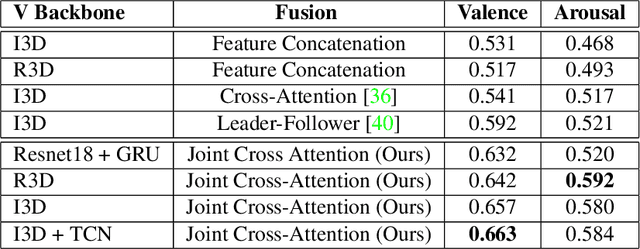
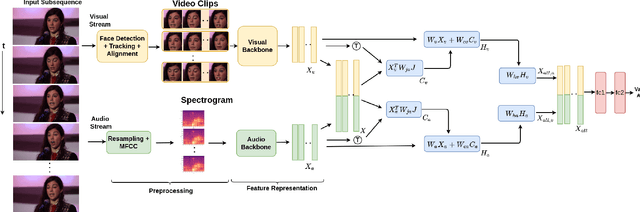
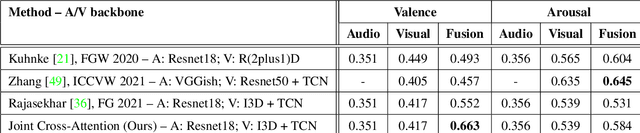
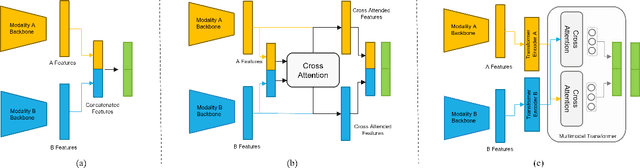
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.