 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Source-Free Personalization for Facial Expression Recognition with Neutral Target Data
Mar 26, 2025



Facial Expression Recognition (FER) from videos is a crucial task in various application areas, such as human-computer interaction and health monitoring (e.g., pain, depression, fatigue, and stress). Beyond the challenges of recognizing subtle emotional or health states, the effectiveness of deep FER models is often hindered by the considerable variability of expressions among subjects. Source-free domain adaptation (SFDA) methods are employed to adapt a pre-trained source model using only unlabeled target domain data, thereby avoiding data privacy and storage issues. Typically, SFDA methods adapt to a target domain dataset corresponding to an entire population and assume it includes data from all recognition classes. However, collecting such comprehensive target data can be difficult or even impossible for FER in healthcare applications. In many real-world scenarios, it may be feasible to collect a short neutral control video (displaying only neutral expressions) for target subjects before deployment. These videos can be used to adapt a model to better handle the variability of expressions among subjects. This paper introduces the Disentangled Source-Free Domain Adaptation (DSFDA) method to address the SFDA challenge posed by missing target expression data. DSFDA leverages data from a neutral target control video for end-to-end generation and adaptation of target data with missing non-neutral data. Our method learns to disentangle features related to expressions and identity while generating the missing non-neutral target data, thereby enhancing model accuracy. Additionally, our self-supervision strategy improves model adaptation by reconstructing target images that maintain the same identity and source expression.
Text- and Feature-based Models for Compound Multimodal Emotion Recognition in the Wild
Jul 17, 2024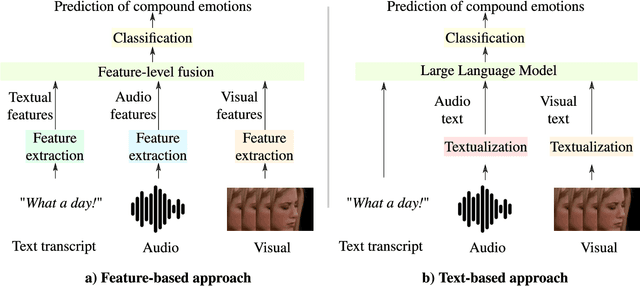
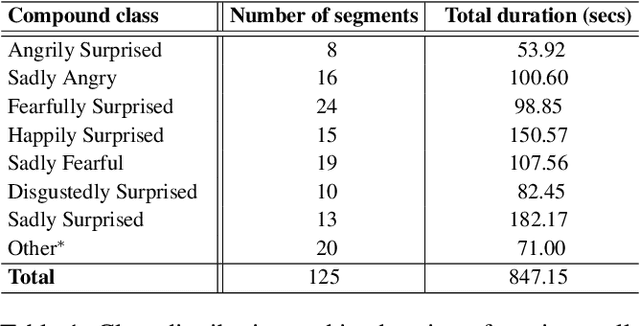


Systems for multimodal Emotion Recognition (ER) commonly rely on features extracted from different modalities (e.g., visual, audio, and textual) to predict the seven basic emotions. However, compound emotions often occur in real-world scenarios and are more difficult to predict. Compound multimodal ER becomes more challenging in videos due to the added uncertainty of diverse modalities. In addition, standard features-based models may not fully capture the complex and subtle cues needed to understand compound emotions. %%%% Since relevant cues can be extracted in the form of text, we advocate for textualizing all modalities, such as visual and audio, to harness the capacity of large language models (LLMs). These models may understand the complex interaction between modalities and the subtleties of complex emotions. Although training an LLM requires large-scale datasets, a recent surge of pre-trained LLMs, such as BERT and LLaMA, can be easily fine-tuned for downstream tasks like compound ER. This paper compares two multimodal modeling approaches for compound ER in videos -- standard feature-based vs. text-based. Experiments were conducted on the challenging C-EXPR-DB dataset for compound ER, and contrasted with results on the MELD dataset for basic ER. Our code is available
Joint Multimodal Transformer for Dimensional Emotional Recognition in the Wild
Mar 15, 2024Audiovisual emotion recognition (ER) in videos has immense potential over unimodal performance. It effectively leverages the inter- and intra-modal dependencies between visual and auditory modalities. This work proposes a novel audio-visual emotion recognition system utilizing a joint multimodal transformer architecture with key-based cross-attention. This framework aims to exploit the complementary nature of audio and visual cues (facial expressions and vocal patterns) in videos, leading to superior performance compared to solely relying on a single modality. The proposed model leverages separate backbones for capturing intra-modal temporal dependencies within each modality (audio and visual). Subsequently, a joint multimodal transformer architecture integrates the individual modality embeddings, enabling the model to effectively capture inter-modal (between audio and visual) and intra-modal (within each modality) relationships. Extensive evaluations on the challenging Affwild2 dataset demonstrate that the proposed model significantly outperforms baseline and state-of-the-art methods in ER tasks.
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Feb 02, 2024While state-of-the-art facial expression recognition (FER) classifiers achieve a high level of accuracy, they lack interpretability, an important aspect for end-users. To recognize basic facial expressions, experts resort to a codebook associating a set of spatial action units to a facial expression. In this paper, we follow the same expert footsteps, and propose a learning strategy that allows us to explicitly incorporate spatial action units (aus) cues into the classifier's training to build a deep interpretable model. In particular, using this aus codebook, input image expression label, and facial landmarks, a single action units heatmap is built to indicate the most discriminative regions of interest in the image w.r.t the facial expression. We leverage this valuable spatial cue to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with \aus map. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with aus maps, simulating the experts' decision process. This is achieved using only the image class expression as supervision and without any extra manual annotations. Moreover, our method is generic. It can be applied to any CNN- or transformer-based deep classifier without the need for architectural change or adding significant training time. Our extensive evaluation on two public benchmarks RAFDB, and AFFECTNET datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on Class-Activation Mapping methods (CAMs), and we show that our training technique improves the CAM interpretability.
Distilling Privileged Multimodal Information for Expression Recognition using Optimal Transport
Jan 27, 2024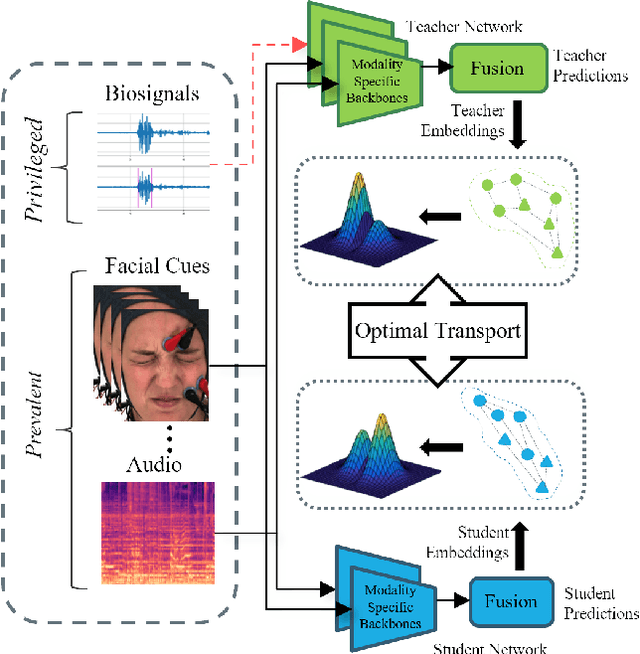
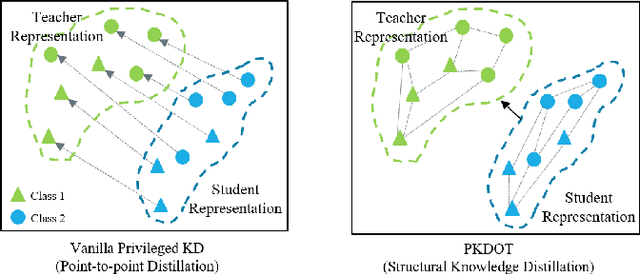
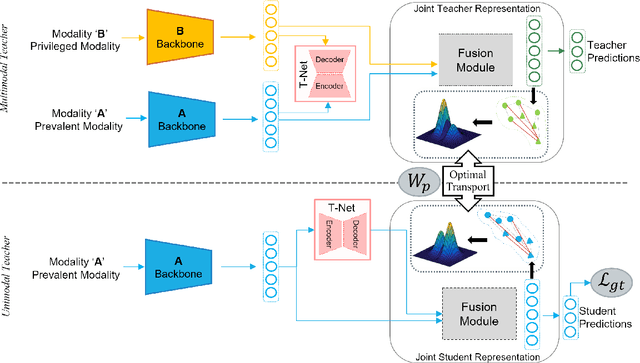
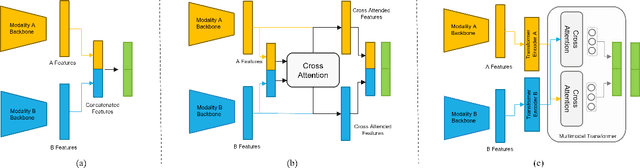
Multimodal affect recognition models have reached remarkable performance in the lab environment due to their ability to model complementary and redundant semantic information. However, these models struggle in the wild, mainly because of the unavailability or quality of modalities used for training. In practice, only a subset of the training-time modalities may be available at test time. Learning with privileged information (PI) enables deep learning models (DL) to exploit data from additional modalities only available during training. State-of-the-art knowledge distillation (KD) methods have been proposed to distill multiple teacher models (each trained on a modality) to a common student model. These privileged KD methods typically utilize point-to-point matching and have no explicit mechanism to capture the structural information in the teacher representation space formed by introducing the privileged modality. We argue that encoding this same structure in the student space may lead to enhanced student performance. This paper introduces a new structural KD mechanism based on optimal transport (OT), where entropy-regularized OT distills the structural dark knowledge. Privileged KD with OT (PKDOT) method captures the local structures in the multimodal teacher representation by calculating a cosine similarity matrix and selects the top-k anchors to allow for sparse OT solutions, resulting in a more stable distillation process. Experiments were performed on two different problems: pain estimation on the Biovid dataset (ordinal classification) and arousal-valance prediction on the Affwild2 dataset (regression). Results show that the proposed method can outperform state-of-the-art privileged KD methods on these problems. The diversity of different modalities and fusion architectures indicates that the proposed PKDOT method is modality and model-agnostic.
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023



Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.
Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition
Nov 10, 2020
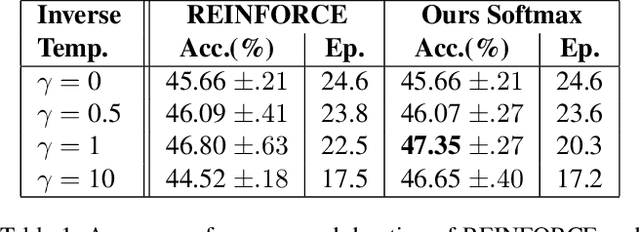

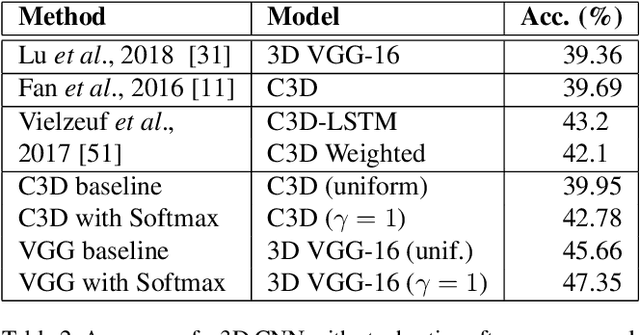
Training deep learning models for accurate spatiotemporal recognition of facial expressions in videos requires significant computational resources. For practical reasons, 3D Convolutional Neural Networks (3D CNNs) are usually trained with relatively short clips randomly extracted from videos. However, such uniform sampling is generally sub-optimal because equal importance is assigned to each temporal clip. In this paper, we present a strategy for efficient video-based training of 3D CNNs. It relies on softmax temporal pooling and a weighted sampling mechanism to select the most relevant training clips. The proposed softmax strategy provides several advantages: a reduced computational complexity due to efficient clip sampling, and an improved accuracy since temporal weighting focuses on more relevant clips during both training and inference. Experimental results obtained with the proposed method on several facial expression recognition benchmarks show the benefits of focusing on more informative clips in training videos. In particular, our approach improves performance and computational cost by reducing the impact of inaccurate trimming and coarse annotation of videos, and heterogeneous distribution of visual information across time.