 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrazilian Portuguese Image Captioning with Transformers: A Study on Cross-Native-Translated Dataset
Jan 30, 2026Image captioning (IC) refers to the automatic generation of natural language descriptions for images, with applications ranging from social media content generation to assisting individuals with visual impairments. While most research has been focused on English-based models, low-resource languages such as Brazilian Portuguese face significant challenges due to the lack of specialized datasets and models. Several studies create datasets by automatically translating existing ones to mitigate resource scarcity. This work addresses this gap by proposing a cross-native-translated evaluation of Transformer-based vision and language models for Brazilian Portuguese IC. We use a version of Flickr30K comprised of captions manually created by native Brazilian Portuguese speakers and compare it to a version with captions automatically translated from English to Portuguese. The experiments include a cross-context approach, where models trained on one dataset are tested on the other to assess the translation impact. Additionally, we incorporate attention maps for model inference interpretation and use the CLIP-Score metric to evaluate the image-description alignment. Our findings show that Swin-DistilBERTimbau consistently outperforms other models, demonstrating strong generalization across datasets. ViTucano, a Brazilian Portuguese pre-trained VLM, surpasses larger multilingual models (GPT-4o, LLaMa 3.2 Vision) in traditional text-based evaluation metrics, while GPT-4 models achieve the highest CLIP-Score, highlighting improved image-text alignment. Attention analysis reveals systematic biases, including gender misclassification, object enumeration errors, and spatial inconsistencies. The datasets and the models generated and analyzed during the current study are available in: https://github.com/laicsiifes/transformer-caption-ptbr.
AI-Driven Early Mental Health Screening with Limited Data: Analyzing Selfies of Pregnant Women
Oct 07, 2024
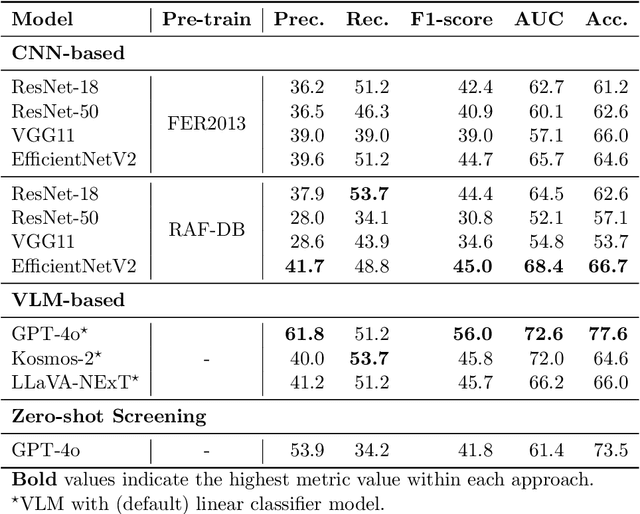
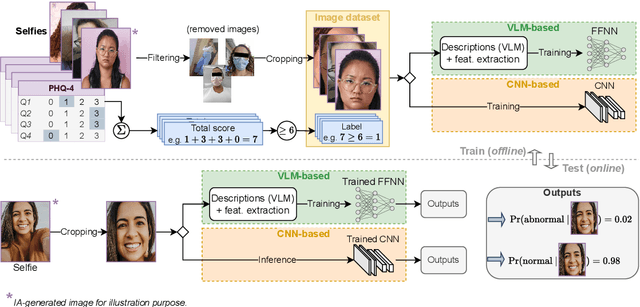
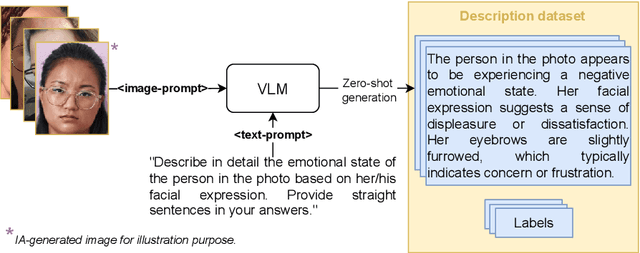
Major Depressive Disorder and anxiety disorders affect millions globally, contributing significantly to the burden of mental health issues. Early screening is crucial for effective intervention, as timely identification of mental health issues can significantly improve treatment outcomes. Artificial intelligence (AI) can be valuable for improving the screening of mental disorders, enabling early intervention and better treatment outcomes. AI-driven screening can leverage the analysis of multiple data sources, including facial features in digital images. However, existing methods often rely on controlled environments or specialized equipment, limiting their broad applicability. This study explores the potential of AI models for ubiquitous depression-anxiety screening given face-centric selfies. The investigation focuses on high-risk pregnant patients, a population that is particularly vulnerable to mental health issues. To cope with limited training data resulting from our clinical setup, pre-trained models were utilized in two different approaches: fine-tuning convolutional neural networks (CNNs) originally designed for facial expression recognition and employing vision-language models (VLMs) for zero-shot analysis of facial expressions. Experimental results indicate that the proposed VLM-based method significantly outperforms CNNs, achieving an accuracy of 77.6% and an F1-score of 56.0%. Although there is significant room for improvement, the results suggest that VLMs can be a promising approach for mental health screening, especially in scenarios with limited data.
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023



Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.
Pattern Spotting and Image Retrieval in Historical Documents using Deep Hashing
Aug 04, 2022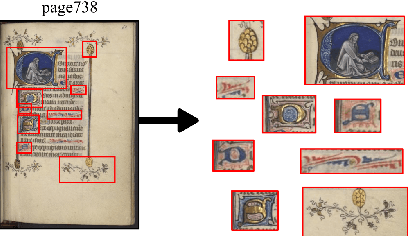
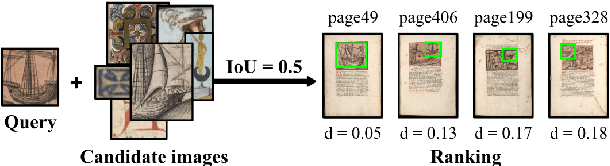


This paper presents a deep learning approach for image retrieval and pattern spotting in digital collections of historical documents. First, a region proposal algorithm detects object candidates in the document page images. Next, deep learning models are used for feature extraction, considering two distinct variants, which provide either real-valued or binary code representations. Finally, candidate images are ranked by computing the feature similarity with a given input query. A robust experimental protocol evaluates the proposed approach considering each representation scheme (real-valued and binary code) on the DocExplore image database. The experimental results show that the proposed deep models compare favorably to the state-of-the-art image retrieval approaches for images of historical documents, outperforming other deep models by 2.56 percentage points using the same techniques for pattern spotting. Besides, the proposed approach also reduces the search time by up to 200x and the storage cost up to 6,000x when compared to related works based on real-valued representations.
Evaluation of Self-taught Learning-based Representations for Facial Emotion Recognition
Apr 26, 2022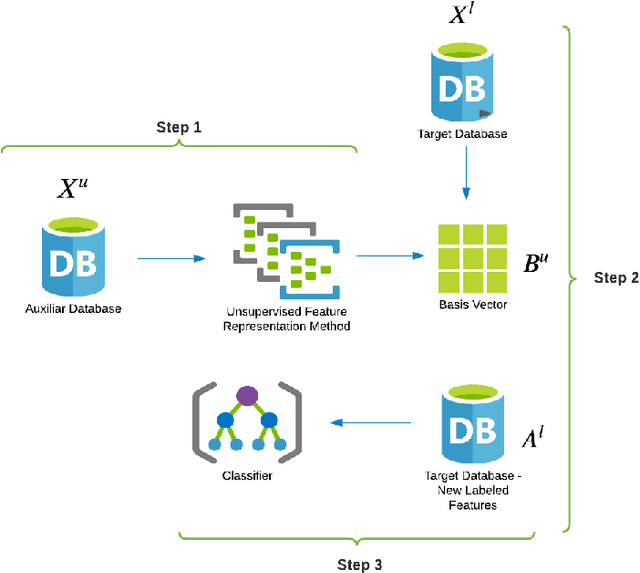
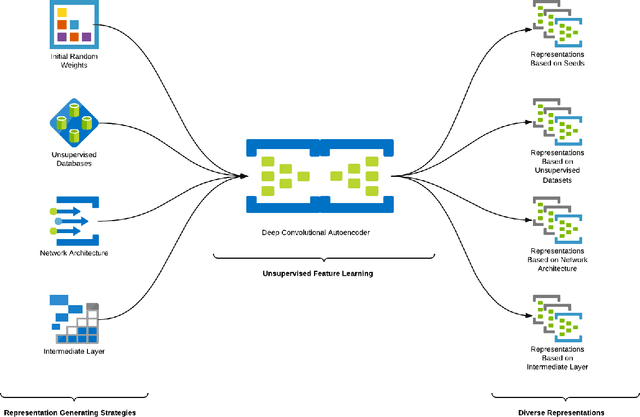


This work describes different strategies to generate unsupervised representations obtained through the concept of self-taught learning for facial emotion recognition (FER). The idea is to create complementary representations promoting diversity by varying the autoencoders' initialization, architecture, and training data. SVM, Bagging, Random Forest, and a dynamic ensemble selection method are evaluated as final classification methods. Experimental results on Jaffe and Cohn-Kanade datasets using a leave-one-subject-out protocol show that FER methods based on the proposed diverse representations compare favorably against state-of-the-art approaches that also explore unsupervised feature learning.
Multiscale Analysis for Improving Texture Classification
Apr 21, 2022

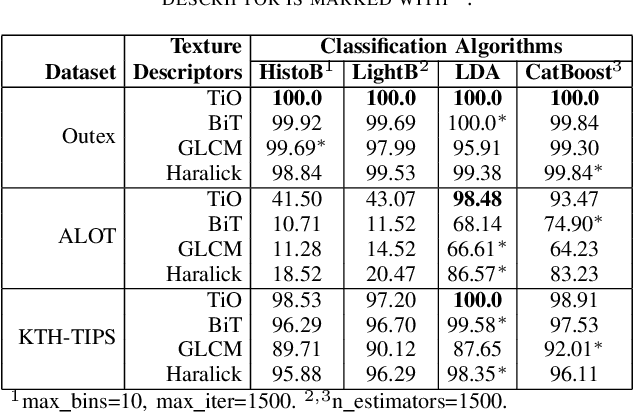

Information from an image occurs over multiple and distinct spatial scales. Image pyramid multiresolution representations are a useful data structure for image analysis and manipulation over a spectrum of spatial scales. This paper employs the Gaussian-Laplacian pyramid to treat different spatial frequency bands of a texture separately. First, we generate three images corresponding to three levels of the Gaussian-Laplacian pyramid for an input image to capture intrinsic details. Then we aggregate features extracted from gray and color texture images using bio-inspired texture descriptors, information-theoretic measures, gray-level co-occurrence matrix features, and Haralick statistical features into a single feature vector. Such an aggregation aims at producing features that characterize textures to their maximum extent, unlike employing each descriptor separately, which may lose some relevant textural information and reduce the classification performance. The experimental results on texture and histopathologic image datasets have shown the advantages of the proposed method compared to state-of-the-art approaches. Such findings emphasize the importance of multiscale image analysis and corroborate that the descriptors mentioned above are complementary.
Discriminative Singular Spectrum Classifier with Applications on Bioacoustic Signal Recognition
Mar 18, 2021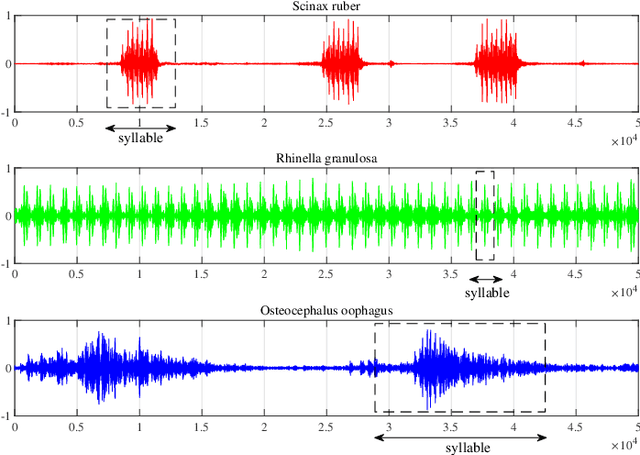
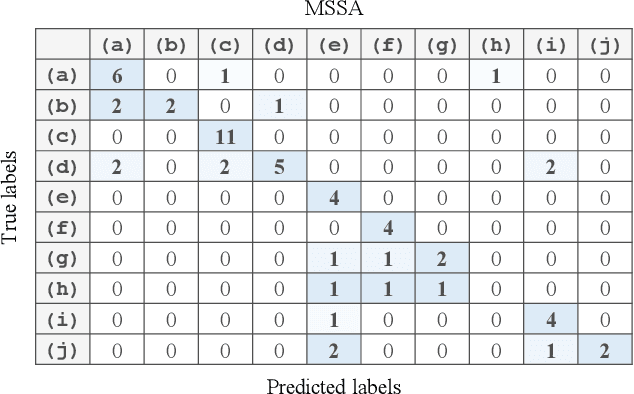
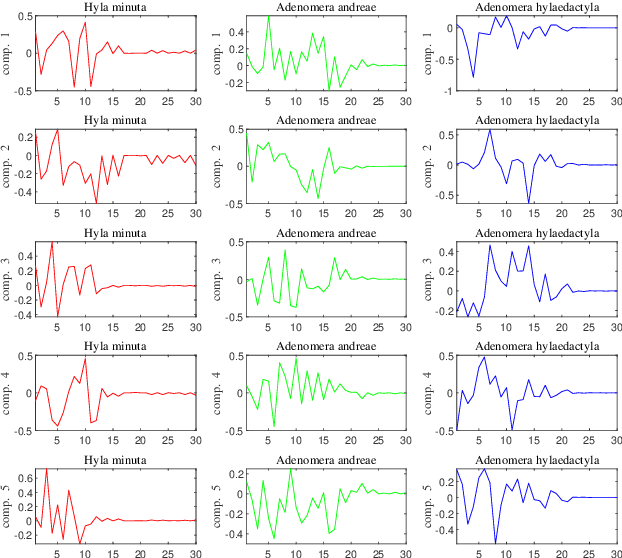
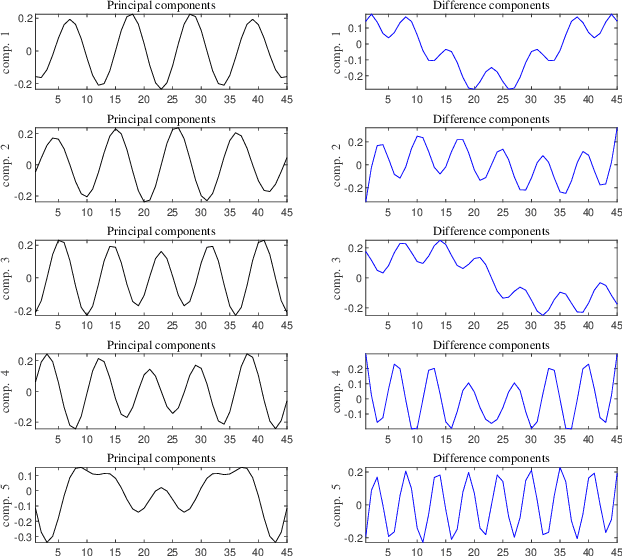
Automatic analysis of bioacoustic signals is a fundamental tool to evaluate the vitality of our planet. Frogs and bees, for instance, may act like biological sensors providing information about environmental changes. This task is fundamental for ecological monitoring still includes many challenges such as nonuniform signal length processing, degraded target signal due to environmental noise, and the scarcity of the labeled samples for training machine learning. To tackle these challenges, we present a bioacoustic signal classifier equipped with a discriminative mechanism to extract useful features for analysis and classification efficiently. The proposed classifier does not require a large amount of training data and handles nonuniform signal length natively. Unlike current bioacoustic recognition methods, which are task-oriented, the proposed model relies on transforming the input signals into vector subspaces generated by applying Singular Spectrum Analysis (SSA). Then, a subspace is designed to expose discriminative features. The proposed model shares end-to-end capabilities, which is desirable in modern machine learning systems. This formulation provides a segmentation-free and noise-tolerant approach to represent and classify bioacoustic signals and a highly compact signal descriptor inherited from SSA. The validity of the proposed method is verified using three challenging bioacoustic datasets containing anuran, bee, and mosquito species. Experimental results on three bioacoustic datasets have shown the competitive performance of the proposed method compared to commonly employed methods for bioacoustics signal classification in terms of accuracy.
Self-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents
Jul 01, 2020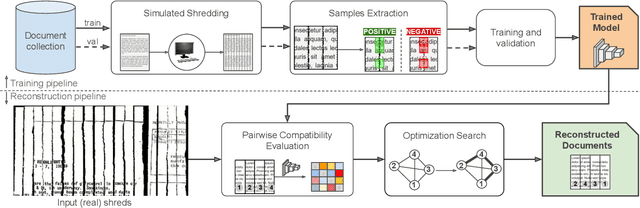

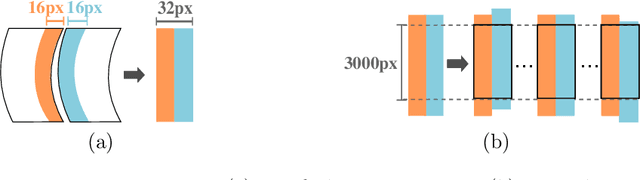
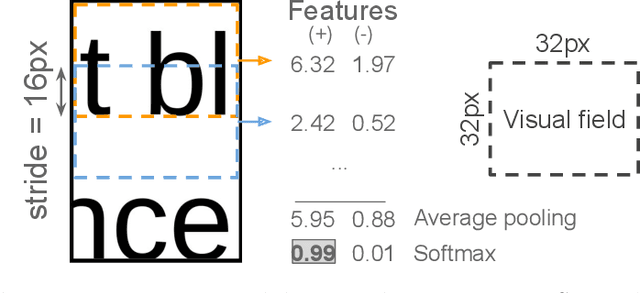
The reconstruction of shredded documents consists of coherently arranging fragments of paper (shreds) to recover the original document(s). A great challenge in computational reconstruction is to properly evaluate the compatibility between the shreds. While traditional pixel-based approaches are not robust to real shredding, more sophisticated solutions compromise significantly time performance. The solution presented in this work extends our previous deep learning method for single-page reconstruction to a more realistic/complex scenario: the reconstruction of several mixed shredded documents at once. In our approach, the compatibility evaluation is modeled as a two-class (valid or invalid) pattern recognition problem. The model is trained in a self-supervised manner on samples extracted from simulated-shredded documents, which obviates manual annotation. Experimental results on three datasets -- including a new collection of 100 strip-shredded documents produced for this work -- have shown that the proposed method outperforms the competing ones on complex scenarios, achieving accuracy superior to 90%.
Two-View Fine-grained Classification of Plant Species
May 18, 2020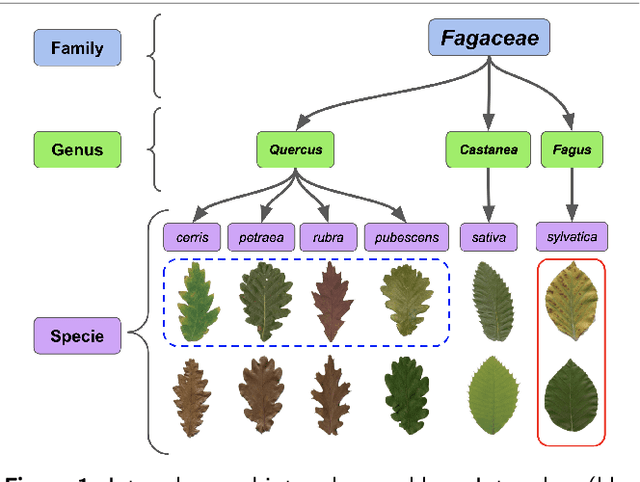
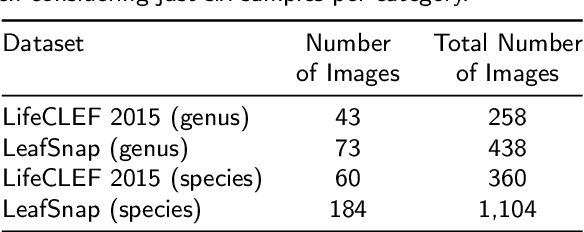
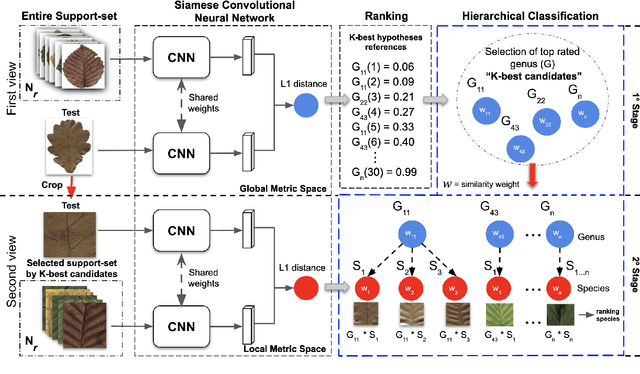
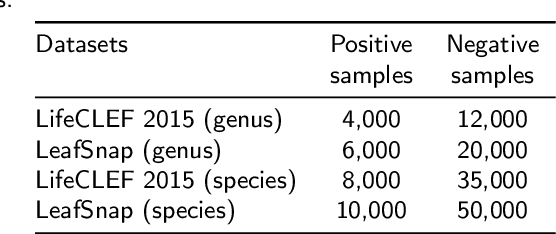
Automatic plant classification is a challenging problem due to the wide biodiversity of the existing plant species in a fine-grained scenario. Powerful deep learning architectures have been used to improve the classification performance in such a fine-grained problem, but usually building models that are highly dependent on a large training dataset and which are not scalable. In this paper, we propose a novel method based on a two-view leaf image representation and a hierarchical classification strategy for fine-grained recognition of plant species. It uses the botanical taxonomy as a basis for a coarse-to-fine strategy applied to identify the plant genus and species. The two-view representation provides complementary global and local features of leaf images. A deep metric based on Siamese convolutional neural networks is used to reduce the dependence on a large number of training samples and make the method scalable to new plant species. The experimental results on two challenging fine-grained datasets of leaf images (i.e. LifeCLEF 2015 and LeafSnap) have shown the effectiveness of the proposed method, which achieved recognition accuracy of 0.87 and 0.96 respectively.
Data Augmentation for Histopathological Images Based on Gaussian-Laplacian Pyramid Blending
Jan 31, 2020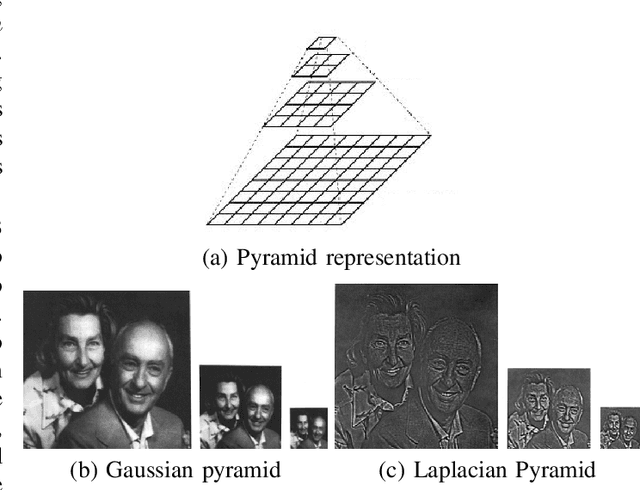
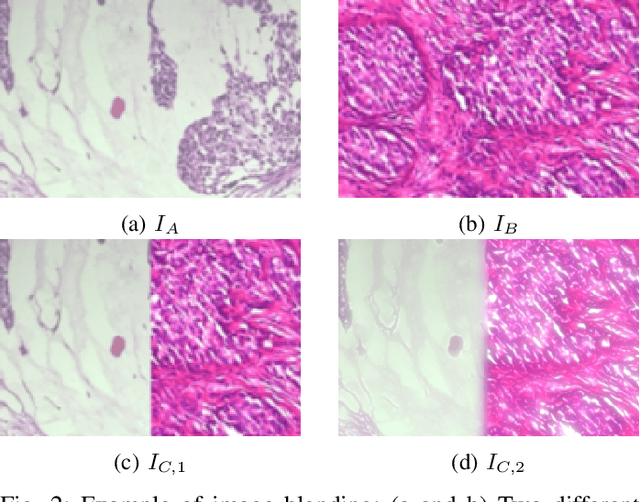
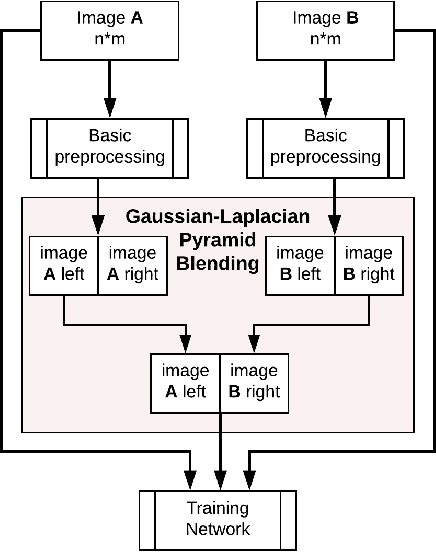
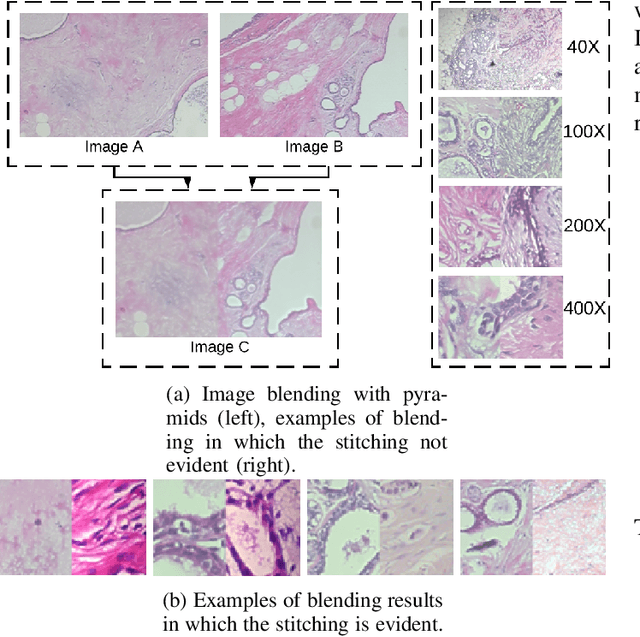
Data imbalance is a major problem that affects several machine learning algorithms. Such problems are troublesome because most of the learning algorithms attempts to optimize a loss function based on error measures that do not take into account the data imbalance. Accordingly, the learning algorithm simply generates a trivial model that is biased toward predicting the most frequent class in the training data. Data augmentation techniques have been used to mitigate the data imbalance problem. However, in the case of histopathologic images (HIs), low-level as well as high-level data augmentation techniques still present performance issues when applied in the presence of inter-patient variability; whence the model tends to learn color representations, which are in fact related to the stain process. In this paper, we propose an approach capable of not only augmenting HIs database but also distributing the inter-patient variability by means of image blending using Gaussian-Laplacian pyramid. The proposed approach consists in finding the Gaussian pyramids of two images of different patients and finding the Laplacian pyramids thereof. Afterwards, the left half of one image and the right half of another are joined in each level of Laplacian pyramid, and from the joint pyramids, the original image is reconstructed. This composition, resulting from the blending process, combines stain variation of two patients, avoiding that color misleads the learning process. Experimental results on the BreakHis dataset have shown promising gains vis-\`a-vis the majority of traditional techniques presented in the literature.