 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020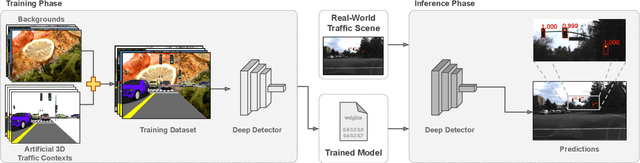
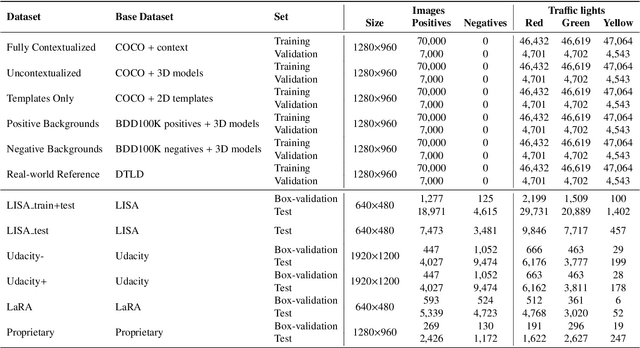

Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.
Self-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents
Jul 01, 2020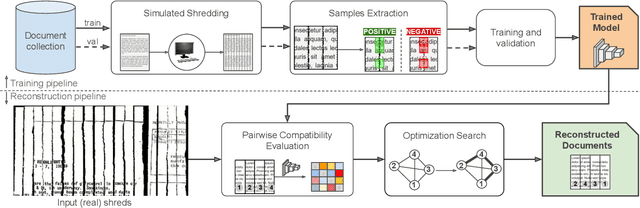

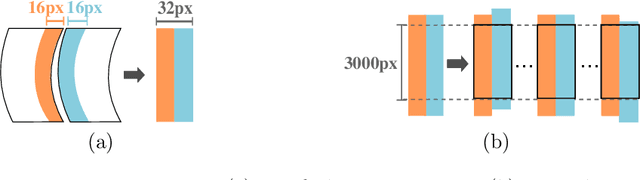
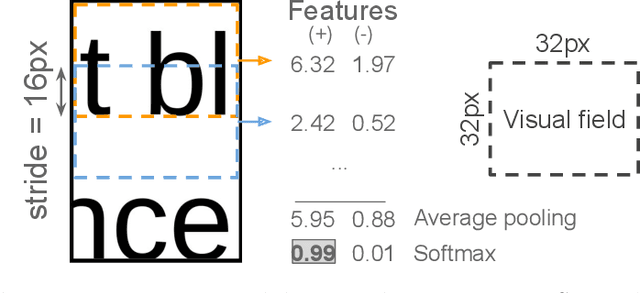
The reconstruction of shredded documents consists of coherently arranging fragments of paper (shreds) to recover the original document(s). A great challenge in computational reconstruction is to properly evaluate the compatibility between the shreds. While traditional pixel-based approaches are not robust to real shredding, more sophisticated solutions compromise significantly time performance. The solution presented in this work extends our previous deep learning method for single-page reconstruction to a more realistic/complex scenario: the reconstruction of several mixed shredded documents at once. In our approach, the compatibility evaluation is modeled as a two-class (valid or invalid) pattern recognition problem. The model is trained in a self-supervised manner on samples extracted from simulated-shredded documents, which obviates manual annotation. Experimental results on three datasets -- including a new collection of 100 strip-shredded documents produced for this work -- have shown that the proposed method outperforms the competing ones on complex scenarios, achieving accuracy superior to 90%.
Ego-Lane Analysis System (ELAS): Dataset and Algorithms
Jun 15, 2018
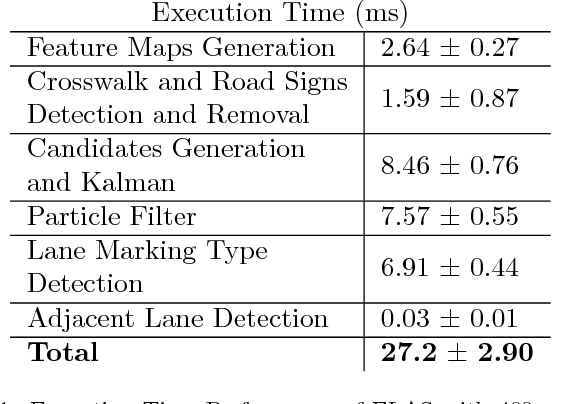
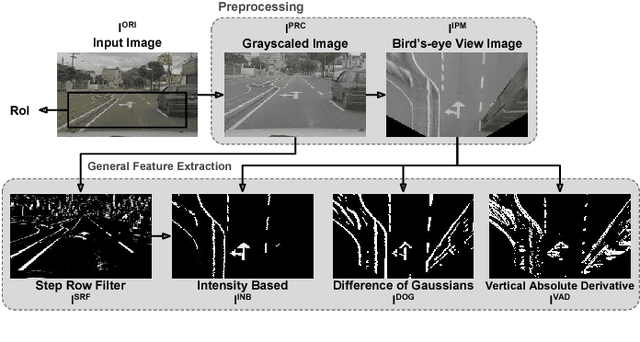
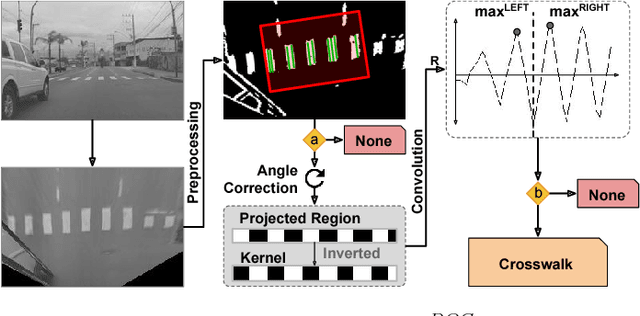
Decreasing costs of vision sensors and advances in embedded hardware boosted lane related research detection, estimation, and tracking in the past two decades. The interest in this topic has increased even more with the demand for advanced driver assistance systems (ADAS) and self-driving cars. Although extensively studied independently, there is still need for studies that propose a combined solution for the multiple problems related to the ego-lane, such as lane departure warning (LDW), lane change detection, lane marking type (LMT) classification, road markings detection and classification, and detection of adjacent lanes (i.e., immediate left and right lanes) presence. In this paper, we propose a real-time Ego-Lane Analysis System (ELAS) capable of estimating ego-lane position, classifying LMTs and road markings, performing LDW and detecting lane change events. The proposed vision-based system works on a temporal sequence of images. Lane marking features are extracted in perspective and Inverse Perspective Mapping (IPM) images that are combined to increase robustness. The final estimated lane is modeled as a spline using a combination of methods (Hough lines with Kalman filter and spline with particle filter). Based on the estimated lane, all other events are detected. To validate ELAS and cover the lack of lane datasets in the literature, a new dataset with more than 20 different scenes (in more than 15,000 frames) and considering a variety of scenarios (urban road, highways, traffic, shadows, etc.) was created. The dataset was manually annotated and made publicly available to enable evaluation of several events that are of interest for the research community (i.e., lane estimation, change, and centering; road markings; intersections; LMTs; crosswalks and adjacent lanes). ELAS achieved high detection rates in all real-world events and proved to be ready for real-time applications.
* 13 pages, 17 figures, github.com/rodrigoberriel/ego-lane-analysis-system, and published by Image and Vision Computing (IMAVIS)
Copycat CNN: Stealing Knowledge by Persuading Confession with Random Non-Labeled Data
Jun 14, 2018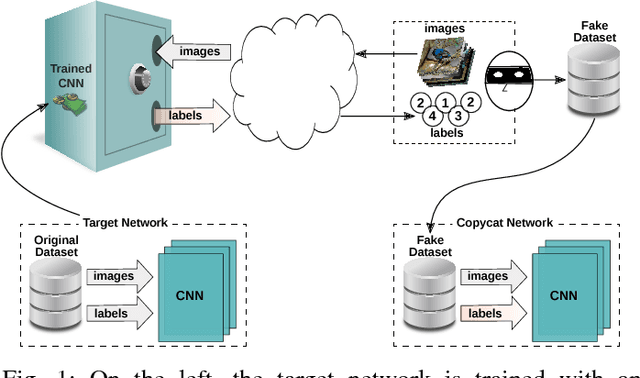
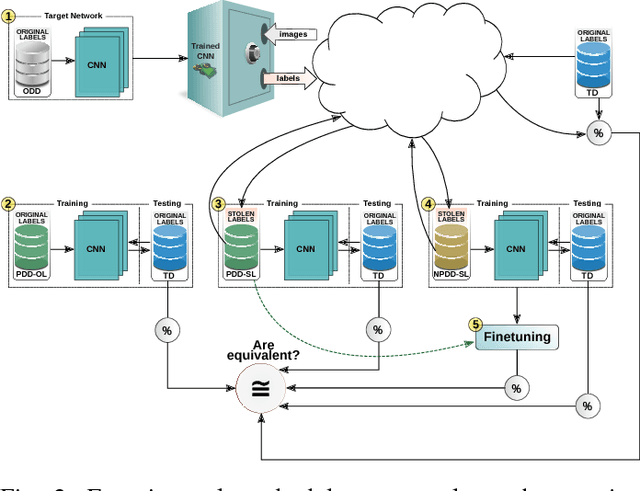
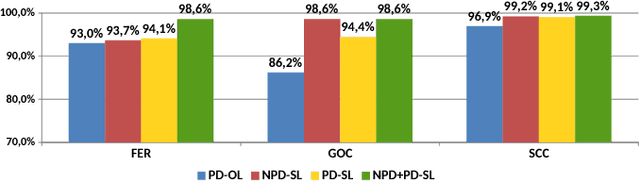
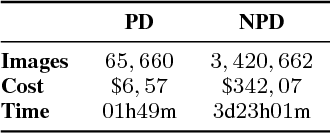
In the past few years, Convolutional Neural Networks (CNNs) have been achieving state-of-the-art performance on a variety of problems. Many companies employ resources and money to generate these models and provide them as an API, therefore it is in their best interest to protect them, i.e., to avoid that someone else copies them. Recent studies revealed that state-of-the-art CNNs are vulnerable to adversarial examples attacks, and this weakness indicates that CNNs do not need to operate in the problem domain (PD). Therefore, we hypothesize that they also do not need to be trained with examples of the PD in order to operate in it. Given these facts, in this paper, we investigate if a target black-box CNN can be copied by persuading it to confess its knowledge through random non-labeled data. The copy is two-fold: i) the target network is queried with random data and its predictions are used to create a fake dataset with the knowledge of the network; and ii) a copycat network is trained with the fake dataset and should be able to achieve similar performance as the target network. This hypothesis was evaluated locally in three problems (facial expression, object, and crosswalk classification) and against a cloud-based API. In the copy attacks, images from both non-problem domain and PD were used. All copycat networks achieved at least 93.7% of the performance of the original models with non-problem domain data, and at least 98.6% using additional data from the PD. Additionally, the copycat CNN successfully copied at least 97.3% of the performance of the Microsoft Azure Emotion API. Our results show that it is possible to create a copycat CNN by simply querying a target network as black-box with random non-labeled data.
Automatic Large-Scale Data Acquisition via Crowdsourcing for Crosswalk Classification: A Deep Learning Approach
May 30, 2018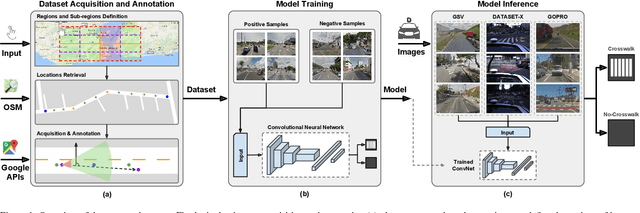
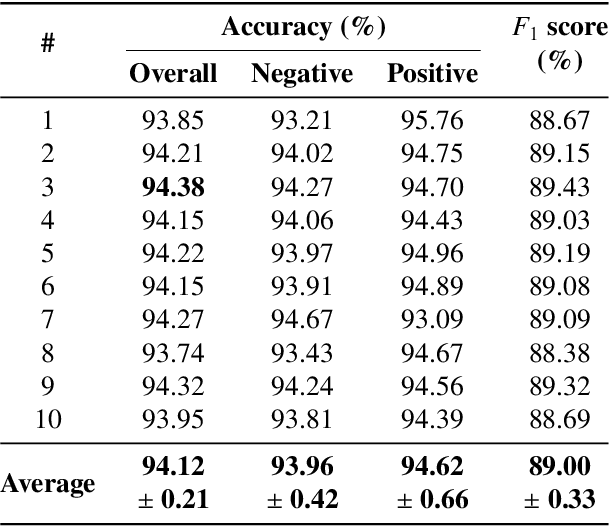
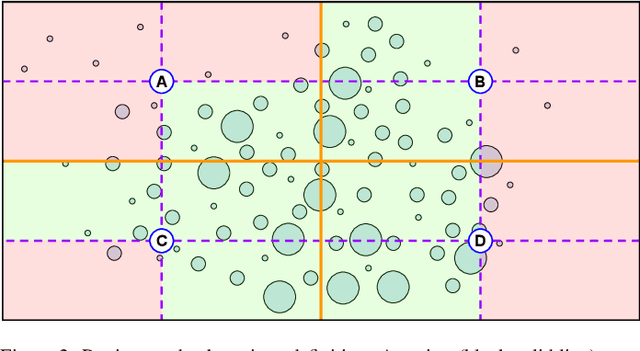
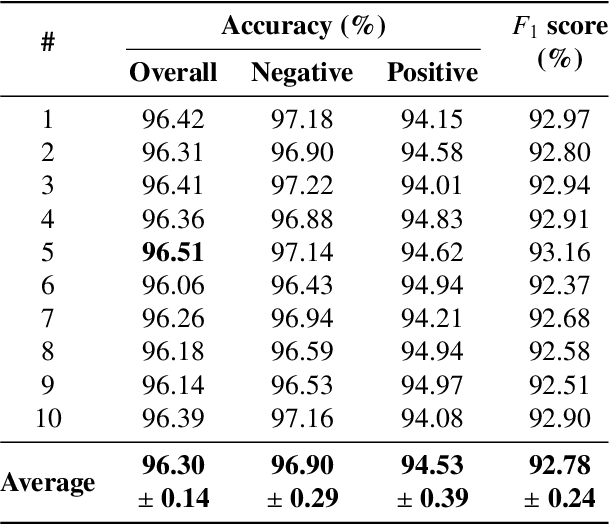
Correctly identifying crosswalks is an essential task for the driving activity and mobility autonomy. Many crosswalk classification, detection and localization systems have been proposed in the literature over the years. These systems use different perspectives to tackle the crosswalk classification problem: satellite imagery, cockpit view (from the top of a car or behind the windshield), and pedestrian perspective. Most of the works in the literature are designed and evaluated using small and local datasets, i.e. datasets that present low diversity. Scaling to large datasets imposes a challenge for the annotation procedure. Moreover, there is still need for cross-database experiments in the literature because it is usually hard to collect the data in the same place and conditions of the final application. In this paper, we present a crosswalk classification system based on deep learning. For that, crowdsourcing platforms, such as OpenStreetMap and Google Street View, are exploited to enable automatic training via automatic acquisition and annotation of a large-scale database. Additionally, this work proposes a comparison study of models trained using fully-automatic data acquisition and annotation against models that were partially annotated. Cross-database experiments were also included in the experimentation to show that the proposed methods enable use with real world applications. Our results show that the model trained on the fully-automatic database achieved high overall accuracy (94.12%), and that a statistically significant improvement (to 96.30%) can be achieved by manually annotating a specific part of the database. Finally, the results of the cross-database experiments show that both models are robust to the many variations of image and scenarios, presenting a consistent behavior.
* 13 pages, 13 figures, 3 videos, and GitHub with models
Deep Learning Based Large-Scale Automatic Satellite Crosswalk Classification
Jul 05, 2017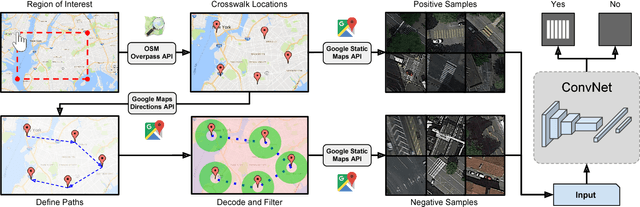


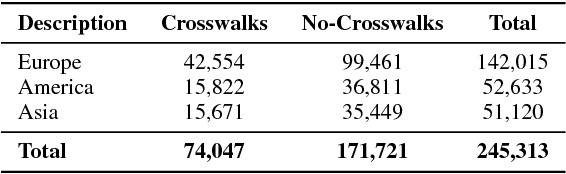
High-resolution satellite imagery have been increasingly used on remote sensing classification problems. One of the main factors is the availability of this kind of data. Even though, very little effort has been placed on the zebra crossing classification problem. In this letter, crowdsourcing systems are exploited in order to enable the automatic acquisition and annotation of a large-scale satellite imagery database for crosswalks related tasks. Then, this dataset is used to train deep-learning-based models in order to accurately classify satellite images that contains or not zebra crossings. A novel dataset with more than 240,000 images from 3 continents, 9 countries and more than 20 cities was used in the experiments. Experimental results showed that freely available crowdsourcing data can be used to accurately (97.11%) train robust models to perform crosswalk classification on a global scale.