 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrazilian Portuguese Image Captioning with Transformers: A Study on Cross-Native-Translated Dataset
Jan 30, 2026Image captioning (IC) refers to the automatic generation of natural language descriptions for images, with applications ranging from social media content generation to assisting individuals with visual impairments. While most research has been focused on English-based models, low-resource languages such as Brazilian Portuguese face significant challenges due to the lack of specialized datasets and models. Several studies create datasets by automatically translating existing ones to mitigate resource scarcity. This work addresses this gap by proposing a cross-native-translated evaluation of Transformer-based vision and language models for Brazilian Portuguese IC. We use a version of Flickr30K comprised of captions manually created by native Brazilian Portuguese speakers and compare it to a version with captions automatically translated from English to Portuguese. The experiments include a cross-context approach, where models trained on one dataset are tested on the other to assess the translation impact. Additionally, we incorporate attention maps for model inference interpretation and use the CLIP-Score metric to evaluate the image-description alignment. Our findings show that Swin-DistilBERTimbau consistently outperforms other models, demonstrating strong generalization across datasets. ViTucano, a Brazilian Portuguese pre-trained VLM, surpasses larger multilingual models (GPT-4o, LLaMa 3.2 Vision) in traditional text-based evaluation metrics, while GPT-4 models achieve the highest CLIP-Score, highlighting improved image-text alignment. Attention analysis reveals systematic biases, including gender misclassification, object enumeration errors, and spatial inconsistencies. The datasets and the models generated and analyzed during the current study are available in: https://github.com/laicsiifes/transformer-caption-ptbr.
Cross-Domain Object Detection Using Unsupervised Image Translation
Jan 16, 2026Unsupervised domain adaptation for object detection addresses the adaption of detectors trained in a source domain to work accurately in an unseen target domain. Recently, methods approaching the alignment of the intermediate features proven to be promising, achieving state-of-the-art results. However, these methods are laborious to implement and hard to interpret. Although promising, there is still room for improvements to close the performance gap toward the upper-bound (when training with the target data). In this work, we propose a method to generate an artificial dataset in the target domain to train an object detector. We employed two unsupervised image translators (CycleGAN and an AdaIN-based model) using only annotated data from the source domain and non-annotated data from the target domain. Our key contributions are the proposal of a less complex yet more effective method that also has an improved interpretability. Results on real-world scenarios for autonomous driving show significant improvements, outperforming state-of-the-art methods in most cases, further closing the gap toward the upper-bound.
AI-Driven Early Mental Health Screening with Limited Data: Analyzing Selfies of Pregnant Women
Oct 07, 2024
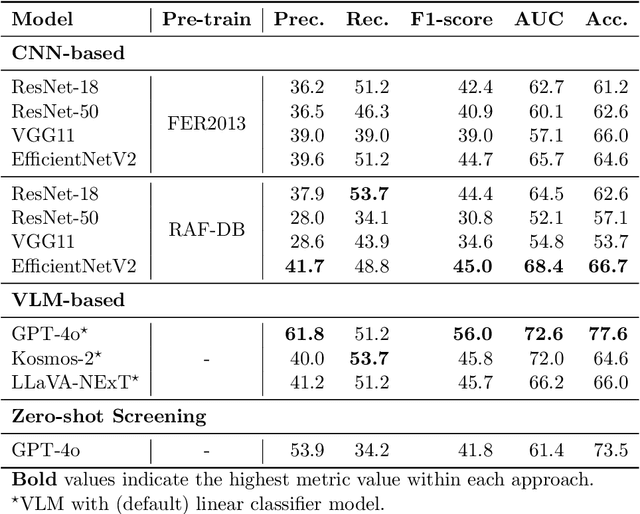
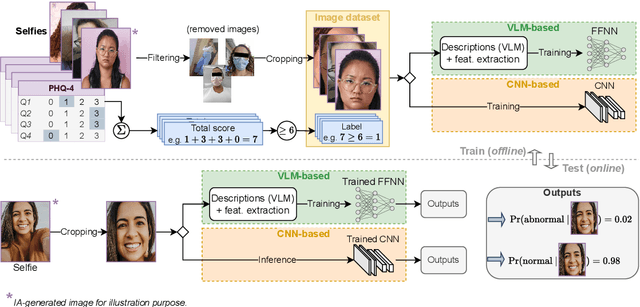
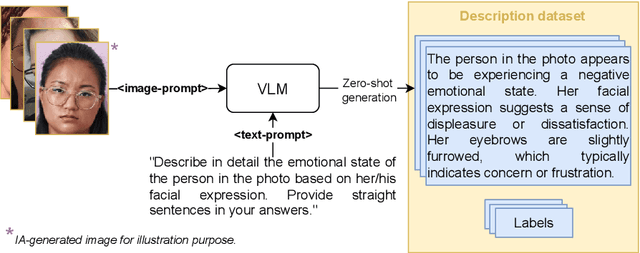
Major Depressive Disorder and anxiety disorders affect millions globally, contributing significantly to the burden of mental health issues. Early screening is crucial for effective intervention, as timely identification of mental health issues can significantly improve treatment outcomes. Artificial intelligence (AI) can be valuable for improving the screening of mental disorders, enabling early intervention and better treatment outcomes. AI-driven screening can leverage the analysis of multiple data sources, including facial features in digital images. However, existing methods often rely on controlled environments or specialized equipment, limiting their broad applicability. This study explores the potential of AI models for ubiquitous depression-anxiety screening given face-centric selfies. The investigation focuses on high-risk pregnant patients, a population that is particularly vulnerable to mental health issues. To cope with limited training data resulting from our clinical setup, pre-trained models were utilized in two different approaches: fine-tuning convolutional neural networks (CNNs) originally designed for facial expression recognition and employing vision-language models (VLMs) for zero-shot analysis of facial expressions. Experimental results indicate that the proposed VLM-based method significantly outperforms CNNs, achieving an accuracy of 77.6% and an F1-score of 56.0%. Although there is significant room for improvement, the results suggest that VLMs can be a promising approach for mental health screening, especially in scenarios with limited data.
Enhancing Brazilian Sign Language Recognition through Skeleton Image Representation
Apr 29, 2024


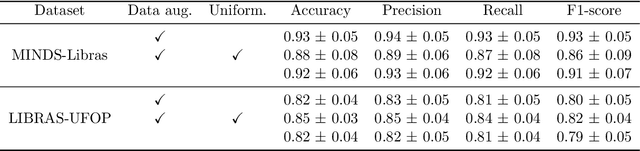
Effective communication is paramount for the inclusion of deaf individuals in society. However, persistent communication barriers due to limited Sign Language (SL) knowledge hinder their full participation. In this context, Sign Language Recognition (SLR) systems have been developed to improve communication between signing and non-signing individuals. In particular, there is the problem of recognizing isolated signs (Isolated Sign Language Recognition, ISLR) of great relevance in the development of vision-based SL search engines, learning tools, and translation systems. This work proposes an ISLR approach where body, hands, and facial landmarks are extracted throughout time and encoded as 2-D images. These images are processed by a convolutional neural network, which maps the visual-temporal information into a sign label. Experimental results demonstrate that our method surpassed the state-of-the-art in terms of performance metrics on two widely recognized datasets in Brazilian Sign Language (LIBRAS), the primary focus of this study. In addition to being more accurate, our method is more time-efficient and easier to train due to its reliance on a simpler network architecture and solely RGB data as input.
Deep Learning-based Type Identification of Volumetric MRI Sequences
Jun 06, 2021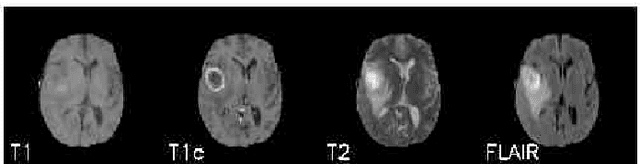
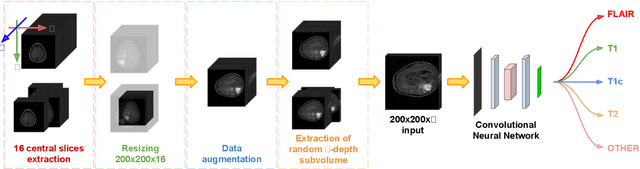
The analysis of Magnetic Resonance Imaging (MRI) sequences enables clinical professionals to monitor the progression of a brain tumor. As the interest for automatizing brain volume MRI analysis increases, it becomes convenient to have each sequence well identified. However, the unstandardized naming of MRI sequences makes their identification difficult for automated systems, as well as makes it difficult for researches to generate or use datasets for machine learning research. In the face of that, we propose a system for identifying types of brain MRI sequences based on deep learning. By training a Convolutional Neural Network (CNN) based on 18-layer ResNet architecture, our system can classify a volumetric brain MRI as a FLAIR, T1, T1c or T2 sequence, or whether it does not belong to any of these classes. The network was evaluated on publicly available datasets comprising both, pre-processed (BraTS dataset) and non-pre-processed (TCGA-GBM dataset), image types with diverse acquisition protocols, requiring only a few slices of the volume for training. Our system can classify among sequence types with an accuracy of 96.81%.
Deep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020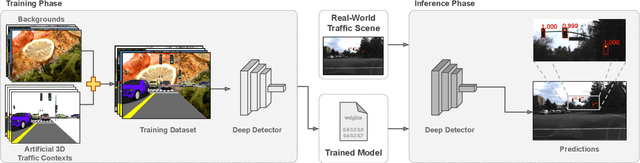

Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.
Keep your Eyes on the Lane: Attention-guided Lane Detection
Oct 22, 2020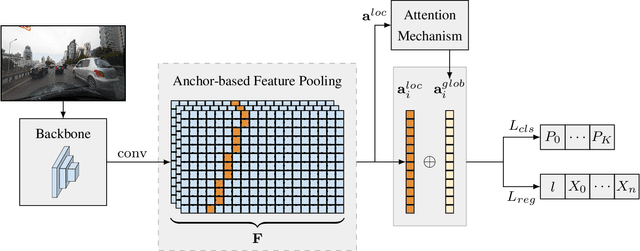
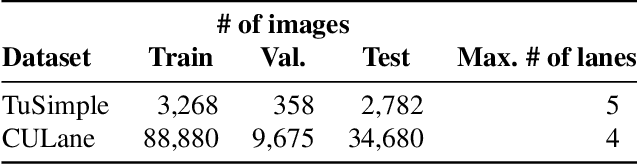
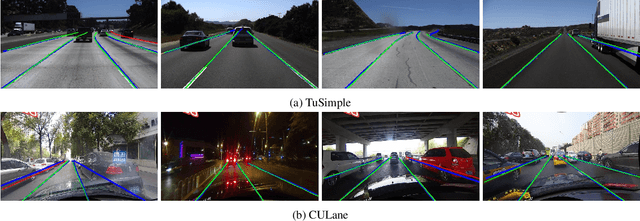
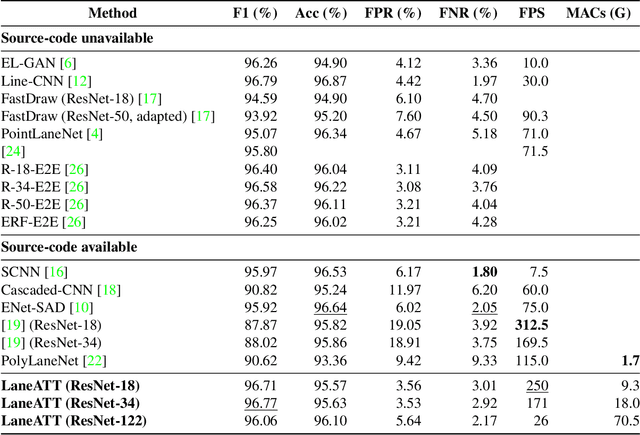
Modern lane detection methods have achieved remarkable performances in complex real-world scenarios, but many have issues maintaining real-time efficiency, which is important for autonomous vehicles. In this work, we propose LaneATT: an anchor-based deep lane detection model, which, akin to other generic deep object detectors, uses the anchors for the feature pooling step. Since lanes follow a regular pattern and are highly correlated, we hypothesize that in some cases global information may be crucial to infer their positions, especially in conditions such as occlusion, missing lane markers, and others. Thus, we propose a novel anchor-based attention mechanism that aggregates global information. The model was evaluated extensively on two of the most widely used datasets in the literature. The results show that our method outperforms the current state-of-the-art methods showing both a higher efficacy and efficiency. Moreover, we perform an ablation study and discuss efficiency trade-off options that are useful in practice. To reproduce our findings, source code and pretrained models are available at https://github.com/lucastabelini/LaneATT
Deep Traffic Sign Detection and Recognition Without Target Domain Real Images
Jul 30, 2020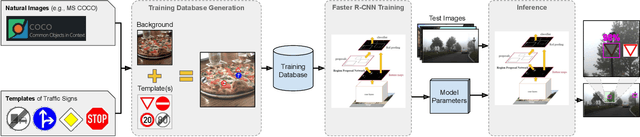
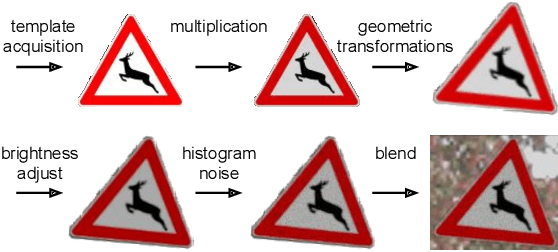


Deep learning has been successfully applied to several problems related to autonomous driving, often relying on large databases of real target-domain images for proper training. The acquisition of such real-world data is not always possible in the self-driving context, and sometimes their annotation is not feasible. Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. Particularly, traffic sign detection is a challenging problem in which these three issues are seen altogether. To address these challenges, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the target-domain, and (ii) templates of the traffic signs. The method does not aim at overcoming the training with real data, but to be a compatible alternative when the real data is not available. The effortlessly generated database is shown to be effective for the training of a deep detector on traffic signs from multiple countries. On large data sets, training with a fully synthetic data set almost matches the performance of training with a real one. When compared to training with a smaller data set of real images, training with synthetic images increased the accuracy by 12.25%. The proposed method also improves the performance of the detector when target-domain data are available.
Self-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents
Jul 01, 2020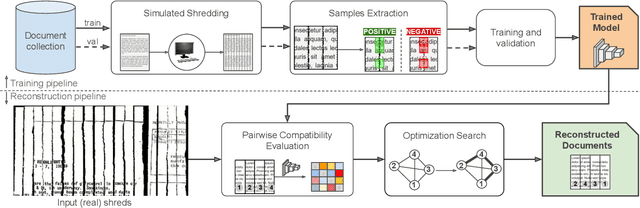

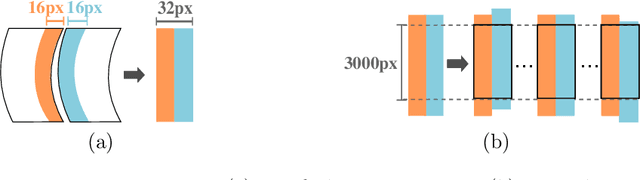
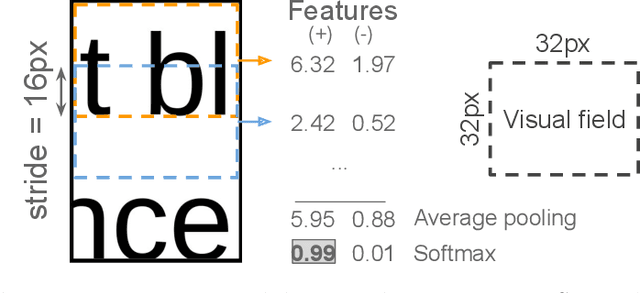
The reconstruction of shredded documents consists of coherently arranging fragments of paper (shreds) to recover the original document(s). A great challenge in computational reconstruction is to properly evaluate the compatibility between the shreds. While traditional pixel-based approaches are not robust to real shredding, more sophisticated solutions compromise significantly time performance. The solution presented in this work extends our previous deep learning method for single-page reconstruction to a more realistic/complex scenario: the reconstruction of several mixed shredded documents at once. In our approach, the compatibility evaluation is modeled as a two-class (valid or invalid) pattern recognition problem. The model is trained in a self-supervised manner on samples extracted from simulated-shredded documents, which obviates manual annotation. Experimental results on three datasets -- including a new collection of 100 strip-shredded documents produced for this work -- have shown that the proposed method outperforms the competing ones on complex scenarios, achieving accuracy superior to 90%.
Fast(er) Reconstruction of Shredded Text Documents via Self-Supervised Deep Asymmetric Metric Learning
Apr 29, 2020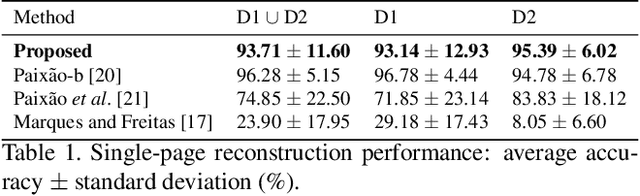
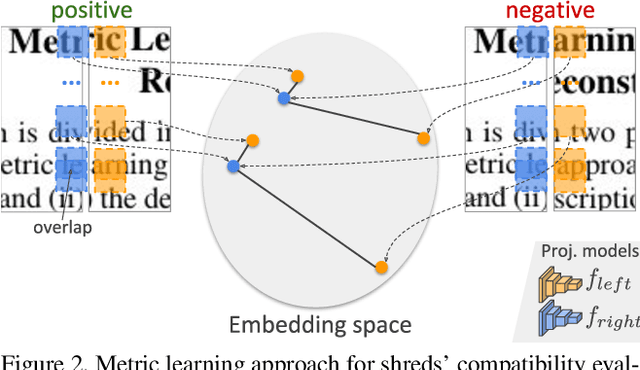
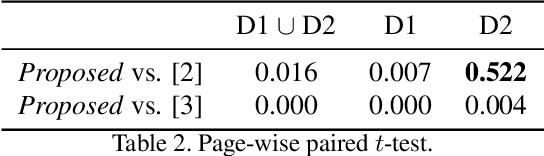
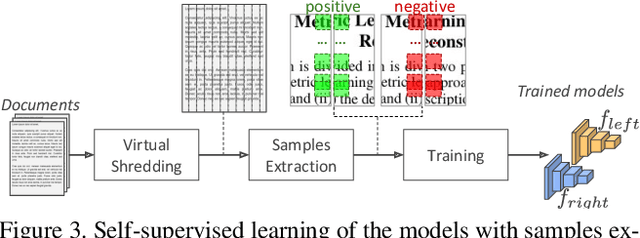
The reconstruction of shredded documents consists in arranging the pieces of paper (shreds) in order to reassemble the original aspect of such documents. This task is particularly relevant for supporting forensic investigation as documents may contain criminal evidence. As an alternative to the laborious and time-consuming manual process, several researchers have been investigating ways to perform automatic digital reconstruction. A central problem in automatic reconstruction of shredded documents is the pairwise compatibility evaluation of the shreds, notably for binary text documents. In this context, deep learning has enabled great progress for accurate reconstructions in the domain of mechanically-shredded documents. A sensitive issue, however, is that current deep model solutions require an inference whenever a pair of shreds has to be evaluated. This work proposes a scalable deep learning approach for measuring pairwise compatibility in which the number of inferences scales linearly (rather than quadratically) with the number of shreds. Instead of predicting compatibility directly, deep models are leveraged to asymmetrically project the raw shred content onto a common metric space in which distance is proportional to the compatibility. Experimental results show that our method has accuracy comparable to the state-of-the-art with a speed-up of about 22 times for a test instance with 505 shreds (20 mixed shredded-pages from different documents).