 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents
Jul 01, 2020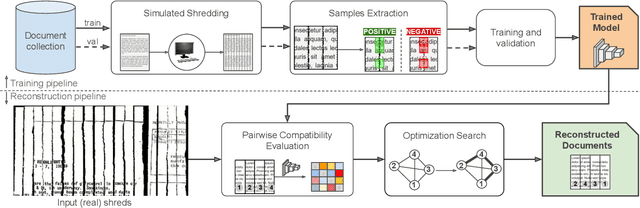

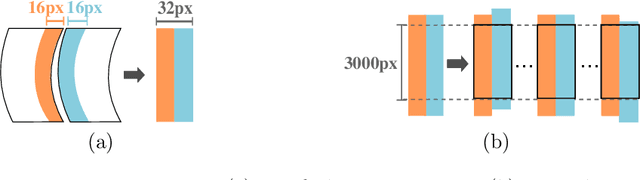
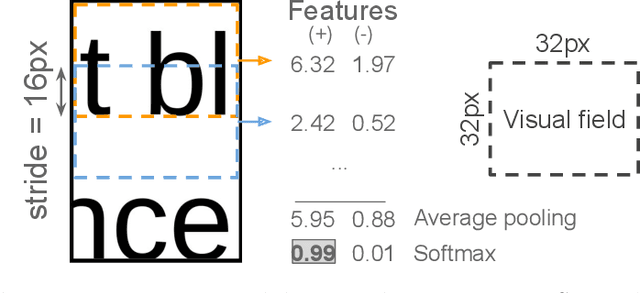
The reconstruction of shredded documents consists of coherently arranging fragments of paper (shreds) to recover the original document(s). A great challenge in computational reconstruction is to properly evaluate the compatibility between the shreds. While traditional pixel-based approaches are not robust to real shredding, more sophisticated solutions compromise significantly time performance. The solution presented in this work extends our previous deep learning method for single-page reconstruction to a more realistic/complex scenario: the reconstruction of several mixed shredded documents at once. In our approach, the compatibility evaluation is modeled as a two-class (valid or invalid) pattern recognition problem. The model is trained in a self-supervised manner on samples extracted from simulated-shredded documents, which obviates manual annotation. Experimental results on three datasets -- including a new collection of 100 strip-shredded documents produced for this work -- have shown that the proposed method outperforms the competing ones on complex scenarios, achieving accuracy superior to 90%.
Fast(er) Reconstruction of Shredded Text Documents via Self-Supervised Deep Asymmetric Metric Learning
Apr 29, 2020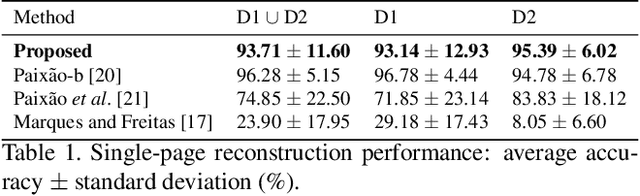
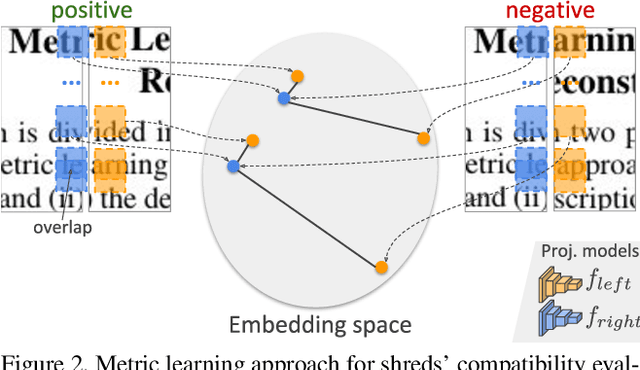
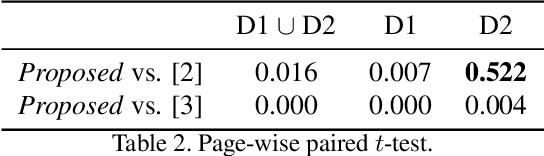
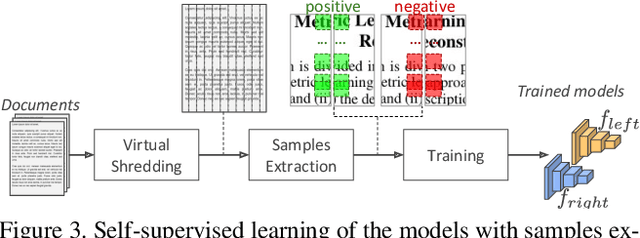
The reconstruction of shredded documents consists in arranging the pieces of paper (shreds) in order to reassemble the original aspect of such documents. This task is particularly relevant for supporting forensic investigation as documents may contain criminal evidence. As an alternative to the laborious and time-consuming manual process, several researchers have been investigating ways to perform automatic digital reconstruction. A central problem in automatic reconstruction of shredded documents is the pairwise compatibility evaluation of the shreds, notably for binary text documents. In this context, deep learning has enabled great progress for accurate reconstructions in the domain of mechanically-shredded documents. A sensitive issue, however, is that current deep model solutions require an inference whenever a pair of shreds has to be evaluated. This work proposes a scalable deep learning approach for measuring pairwise compatibility in which the number of inferences scales linearly (rather than quadratically) with the number of shreds. Instead of predicting compatibility directly, deep models are leveraged to asymmetrically project the raw shred content onto a common metric space in which distance is proportional to the compatibility. Experimental results show that our method has accuracy comparable to the state-of-the-art with a speed-up of about 22 times for a test instance with 505 shreds (20 mixed shredded-pages from different documents).