 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Object Detection Using Unsupervised Image Translation
Jan 16, 2026Unsupervised domain adaptation for object detection addresses the adaption of detectors trained in a source domain to work accurately in an unseen target domain. Recently, methods approaching the alignment of the intermediate features proven to be promising, achieving state-of-the-art results. However, these methods are laborious to implement and hard to interpret. Although promising, there is still room for improvements to close the performance gap toward the upper-bound (when training with the target data). In this work, we propose a method to generate an artificial dataset in the target domain to train an object detector. We employed two unsupervised image translators (CycleGAN and an AdaIN-based model) using only annotated data from the source domain and non-annotated data from the target domain. Our key contributions are the proposal of a less complex yet more effective method that also has an improved interpretability. Results on real-world scenarios for autonomous driving show significant improvements, outperforming state-of-the-art methods in most cases, further closing the gap toward the upper-bound.
Deep Learning-based Type Identification of Volumetric MRI Sequences
Jun 06, 2021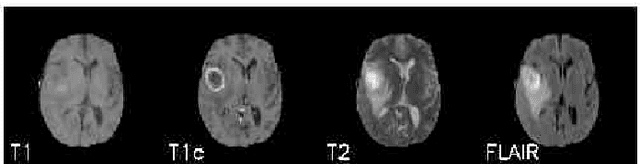
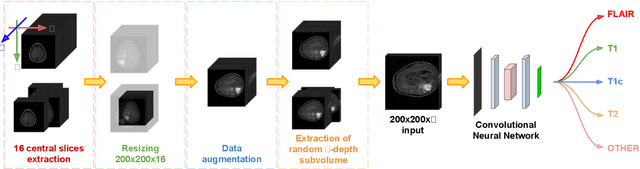
The analysis of Magnetic Resonance Imaging (MRI) sequences enables clinical professionals to monitor the progression of a brain tumor. As the interest for automatizing brain volume MRI analysis increases, it becomes convenient to have each sequence well identified. However, the unstandardized naming of MRI sequences makes their identification difficult for automated systems, as well as makes it difficult for researches to generate or use datasets for machine learning research. In the face of that, we propose a system for identifying types of brain MRI sequences based on deep learning. By training a Convolutional Neural Network (CNN) based on 18-layer ResNet architecture, our system can classify a volumetric brain MRI as a FLAIR, T1, T1c or T2 sequence, or whether it does not belong to any of these classes. The network was evaluated on publicly available datasets comprising both, pre-processed (BraTS dataset) and non-pre-processed (TCGA-GBM dataset), image types with diverse acquisition protocols, requiring only a few slices of the volume for training. Our system can classify among sequence types with an accuracy of 96.81%.
Copycat CNN: Are Random Non-Labeled Data Enough to Steal Knowledge from Black-box Models?
Jan 21, 2021
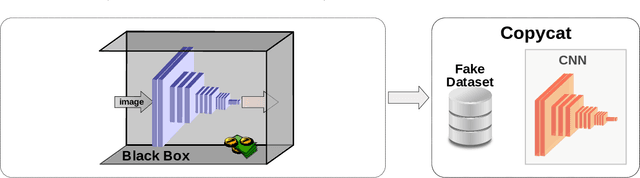

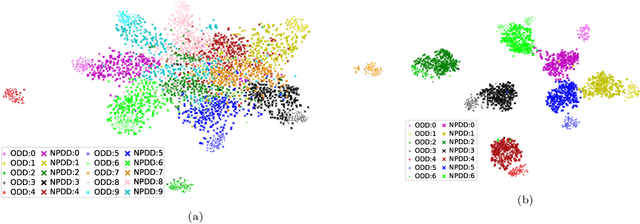
Convolutional neural networks have been successful lately enabling companies to develop neural-based products, which demand an expensive process, involving data acquisition and annotation; and model generation, usually requiring experts. With all these costs, companies are concerned about the security of their models against copies and deliver them as black-boxes accessed by APIs. Nonetheless, we argue that even black-box models still have some vulnerabilities. In a preliminary work, we presented a simple, yet powerful, method to copy black-box models by querying them with natural random images. In this work, we consolidate and extend the copycat method: (i) some constraints are waived; (ii) an extensive evaluation with several problems is performed; (iii) models are copied between different architectures; and, (iv) a deeper analysis is performed by looking at the copycat behavior. Results show that natural random images are effective to generate copycats for several problems.
* The code is available at https://github.com/jeiks/Stealing_DL_Models
Keep your Eyes on the Lane: Attention-guided Lane Detection
Oct 22, 2020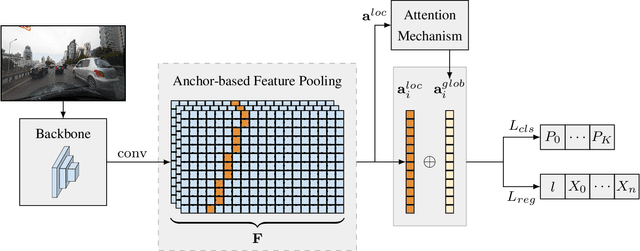
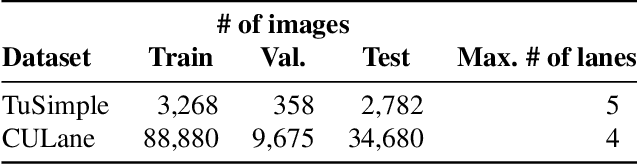
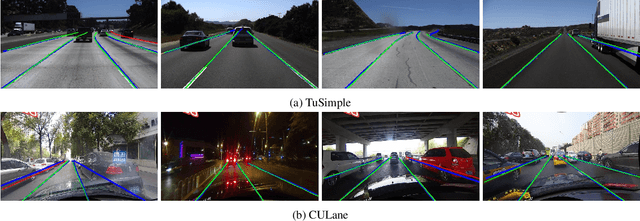
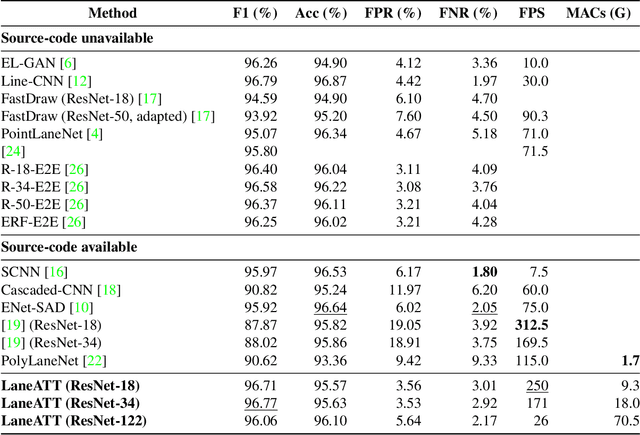
Modern lane detection methods have achieved remarkable performances in complex real-world scenarios, but many have issues maintaining real-time efficiency, which is important for autonomous vehicles. In this work, we propose LaneATT: an anchor-based deep lane detection model, which, akin to other generic deep object detectors, uses the anchors for the feature pooling step. Since lanes follow a regular pattern and are highly correlated, we hypothesize that in some cases global information may be crucial to infer their positions, especially in conditions such as occlusion, missing lane markers, and others. Thus, we propose a novel anchor-based attention mechanism that aggregates global information. The model was evaluated extensively on two of the most widely used datasets in the literature. The results show that our method outperforms the current state-of-the-art methods showing both a higher efficacy and efficiency. Moreover, we perform an ablation study and discuss efficiency trade-off options that are useful in practice. To reproduce our findings, source code and pretrained models are available at https://github.com/lucastabelini/LaneATT
What is the Best Grid-Map for Self-Driving Cars Localization? An Evaluation under Diverse Types of Illumination, Traffic, and Environment
Sep 19, 2020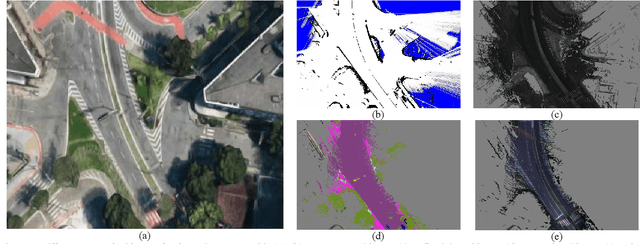
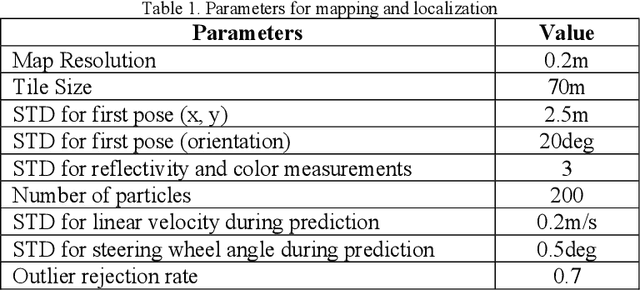
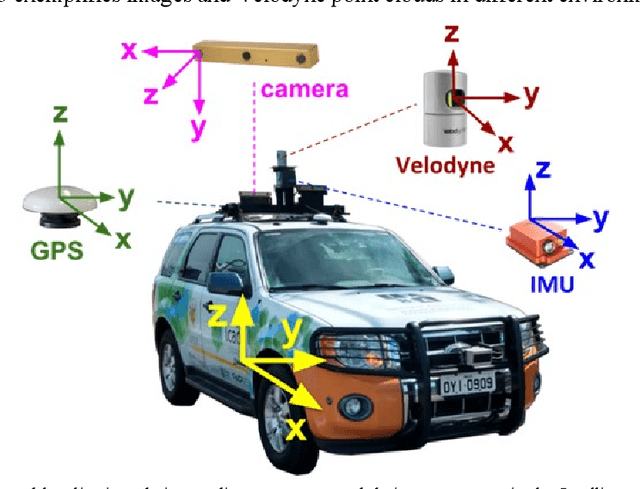
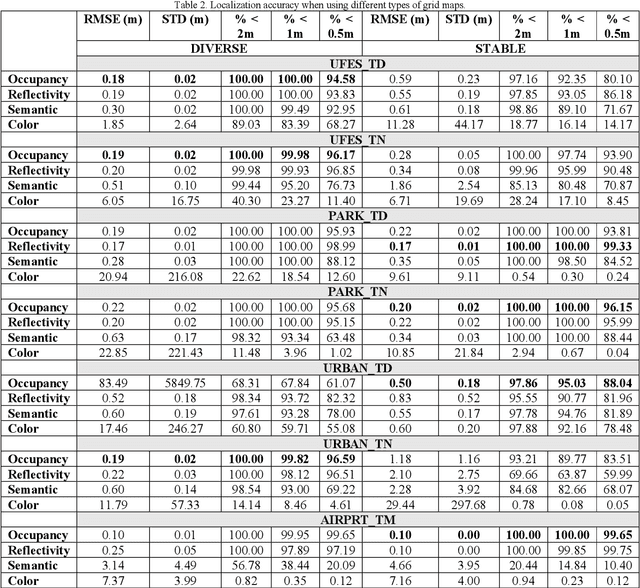
The localization of self-driving cars is needed for several tasks such as keeping maps updated, tracking objects, and planning. Localization algorithms often take advantage of maps for estimating the car pose. Since maintaining and using several maps is computationally expensive, it is important to analyze which type of map is more adequate for each application. In this work, we provide data for such analysis by comparing the accuracy of a particle filter localization when using occupancy, reflectivity, color, or semantic grid maps. To the best of our knowledge, such evaluation is missing in the literature. For building semantic and colour grid maps, point clouds from a Light Detection and Ranging (LiDAR) sensor are fused with images captured by a front-facing camera. Semantic information is extracted from images with a deep neural network. Experiments are performed in varied environments, under diverse conditions of illumination and traffic. Results show that occupancy grid maps lead to more accurate localization, followed by reflectivity grid maps. In most scenarios, the localization with semantic grid maps kept the position tracking without catastrophic losses, but with errors from 2 to 3 times bigger than the previous. Colour grid maps led to inaccurate and unstable localization even using a robust metric, the entropy correlation coefficient, for comparing online data and the map.
Deep Traffic Sign Detection and Recognition Without Target Domain Real Images
Jul 30, 2020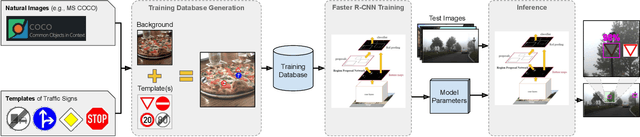
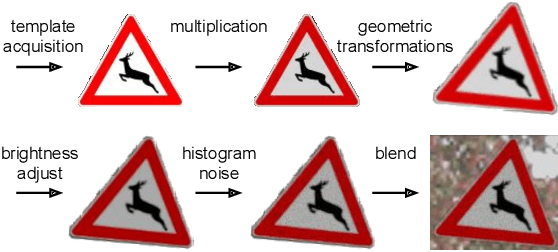


Deep learning has been successfully applied to several problems related to autonomous driving, often relying on large databases of real target-domain images for proper training. The acquisition of such real-world data is not always possible in the self-driving context, and sometimes their annotation is not feasible. Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. Particularly, traffic sign detection is a challenging problem in which these three issues are seen altogether. To address these challenges, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the target-domain, and (ii) templates of the traffic signs. The method does not aim at overcoming the training with real data, but to be a compatible alternative when the real data is not available. The effortlessly generated database is shown to be effective for the training of a deep detector on traffic signs from multiple countries. On large data sets, training with a fully synthetic data set almost matches the performance of training with a real one. When compared to training with a smaller data set of real images, training with synthetic images increased the accuracy by 12.25%. The proposed method also improves the performance of the detector when target-domain data are available.
Fast(er) Reconstruction of Shredded Text Documents via Self-Supervised Deep Asymmetric Metric Learning
Apr 29, 2020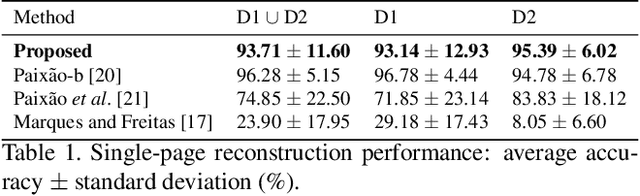
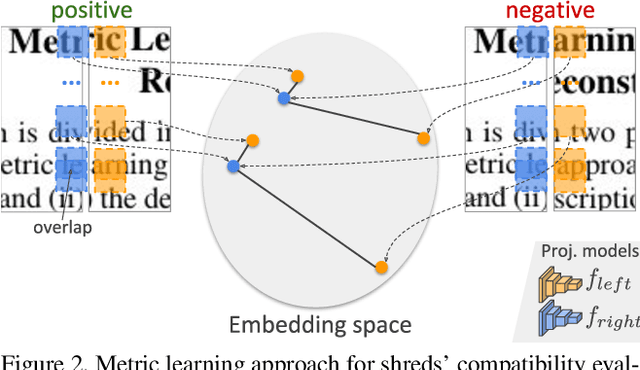
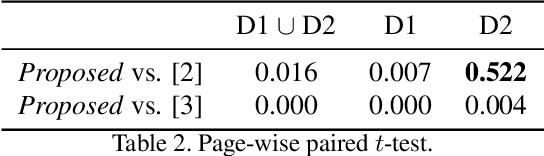
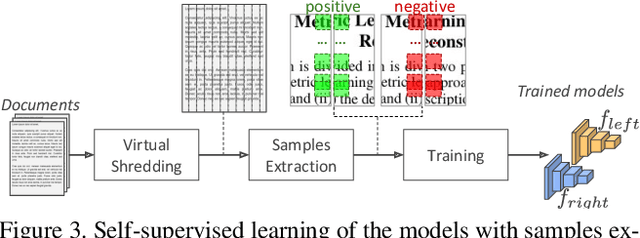
The reconstruction of shredded documents consists in arranging the pieces of paper (shreds) in order to reassemble the original aspect of such documents. This task is particularly relevant for supporting forensic investigation as documents may contain criminal evidence. As an alternative to the laborious and time-consuming manual process, several researchers have been investigating ways to perform automatic digital reconstruction. A central problem in automatic reconstruction of shredded documents is the pairwise compatibility evaluation of the shreds, notably for binary text documents. In this context, deep learning has enabled great progress for accurate reconstructions in the domain of mechanically-shredded documents. A sensitive issue, however, is that current deep model solutions require an inference whenever a pair of shreds has to be evaluated. This work proposes a scalable deep learning approach for measuring pairwise compatibility in which the number of inferences scales linearly (rather than quadratically) with the number of shreds. Instead of predicting compatibility directly, deep models are leveraged to asymmetrically project the raw shred content onto a common metric space in which distance is proportional to the compatibility. Experimental results show that our method has accuracy comparable to the state-of-the-art with a speed-up of about 22 times for a test instance with 505 shreds (20 mixed shredded-pages from different documents).
PolyLaneNet: Lane Estimation via Deep Polynomial Regression
Apr 23, 2020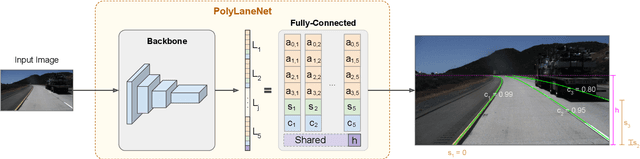


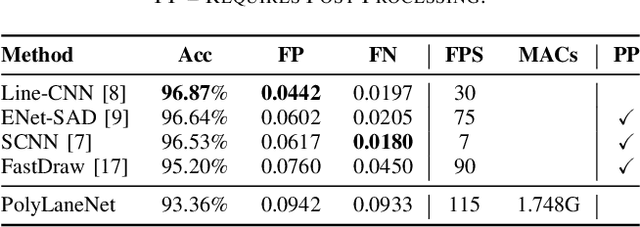
One of the main factors that contributed to the large advances in autonomous driving is the advent of deep learning. For safer self-driving vehicles, one of the problems that has yet to be solved completely is lane detection. Since methods for this task have to work in real time (+30 FPS), they not only have to be effective (i.e., have high accuracy) but they also have to be efficient (i.e., fast). In this work, we present a novel method for lane detection that uses as input an image from a forward-looking camera mounted in the vehicle and outputs polynomials representing each lane marking in the image, via deep polynomial regression. The proposed method is shown to be competitive with existing state-of-the-art methods in the TuSimple dataset, while maintaining its efficiency (115 FPS). Additionally, extensive qualitative results on two additional public datasets are presented, alongside with limitations in the evaluation metrics used by recent works for lane detection. Finally, we provide source code and trained models that allow others to replicate all the results shown in this paper, which is surprisingly rare in state-of-the-art lane detection methods.
Bio-Inspired Foveated Technique for Augmented-Range Vehicle Detection Using Deep Neural Networks
Oct 02, 2019

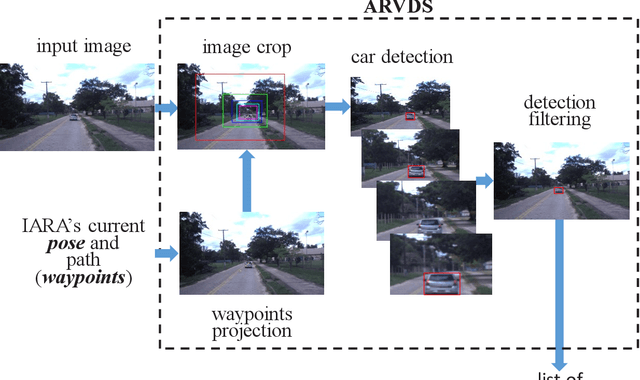
We propose a bio-inspired foveated technique to detect cars in a long range camera view using a deep convolutional neural network (DCNN) for the IARA self-driving car. The DCNN receives as input (i) an image, which is captured by a camera installed on IARA's roof; and (ii) crops of the image, which are centered in the waypoints computed by IARA's path planner and whose sizes increase with the distance from IARA. We employ an overlap filter to discard detections of the same car in different crops of the same image based on the percentage of overlap of detections' bounding boxes. We evaluated the performance of the proposed augmented-range vehicle detection system (ARVDS) using the hardware and software infrastructure available in the IARA self-driving car. Using IARA, we captured thousands of images of real traffic situations containing cars in a long range. Experimental results show that ARVDS increases the Average Precision (AP) of long range car detection from 29.51% (using a single whole image) to 63.15%.
Effortless Deep Training for Traffic Sign Detection Using Templates and Arbitrary Natural Images
Jul 23, 2019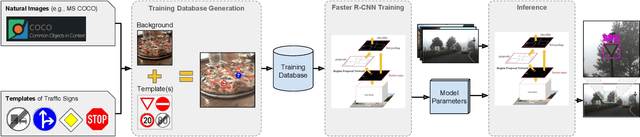



Deep learning has been successfully applied to several problems related to autonomous driving. Often, these solutions rely on large networks that require databases of real image samples of the problem (i.e., real world) for proper training. The acquisition of such real-world data sets is not always possible in the autonomous driving context, and sometimes their annotation is not feasible (e.g., takes too long or is too expensive). Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. It turns out that traffic sign detection is a problem in which these three issues are seen altogether. In this work, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the domain of interest, and (ii) templates of the traffic signs, i.e., templates synthetically created to illustrate the appearance of the category of a traffic sign. The effortlessly generated training database is shown to be effective for the training of a deep detector (such as Faster R-CNN) on German traffic signs, achieving 95.66% of mAP on average. In addition, the proposed method is able to detect traffic signs with an average precision, recall and F1-score of about 94%, 91% and 93%, respectively. The experiments surprisingly show that detectors can be trained with simple data generation methods and without problem domain data for the background, which is in the opposite direction of the common sense for deep learning.