 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the Best Grid-Map for Self-Driving Cars Localization? An Evaluation under Diverse Types of Illumination, Traffic, and Environment
Sep 19, 2020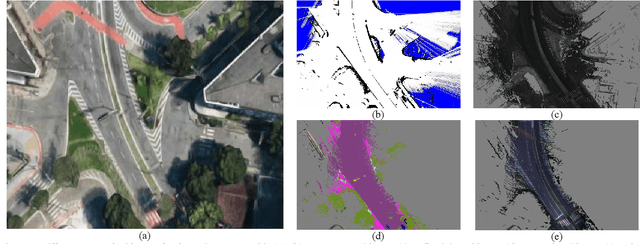
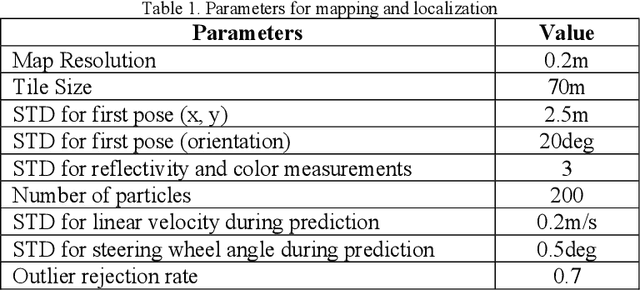
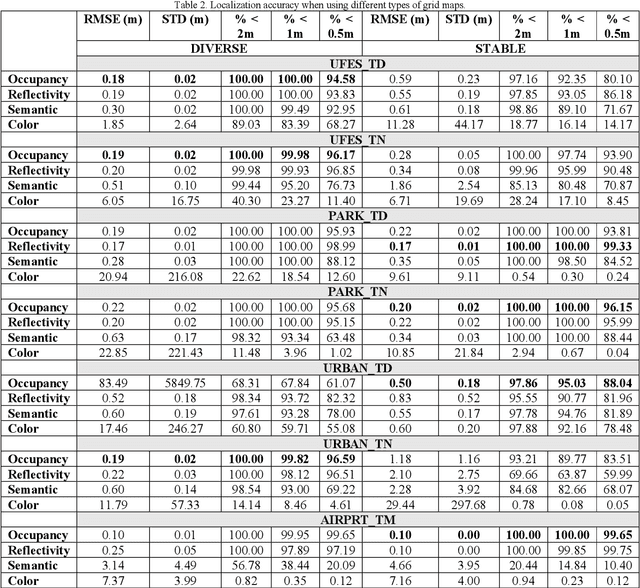
The localization of self-driving cars is needed for several tasks such as keeping maps updated, tracking objects, and planning. Localization algorithms often take advantage of maps for estimating the car pose. Since maintaining and using several maps is computationally expensive, it is important to analyze which type of map is more adequate for each application. In this work, we provide data for such analysis by comparing the accuracy of a particle filter localization when using occupancy, reflectivity, color, or semantic grid maps. To the best of our knowledge, such evaluation is missing in the literature. For building semantic and colour grid maps, point clouds from a Light Detection and Ranging (LiDAR) sensor are fused with images captured by a front-facing camera. Semantic information is extracted from images with a deep neural network. Experiments are performed in varied environments, under diverse conditions of illumination and traffic. Results show that occupancy grid maps lead to more accurate localization, followed by reflectivity grid maps. In most scenarios, the localization with semantic grid maps kept the position tracking without catastrophic losses, but with errors from 2 to 3 times bigger than the previous. Colour grid maps led to inaccurate and unstable localization even using a robust metric, the entropy correlation coefficient, for comparing online data and the map.
Training Agents using Upside-Down Reinforcement Learning
Dec 05, 2019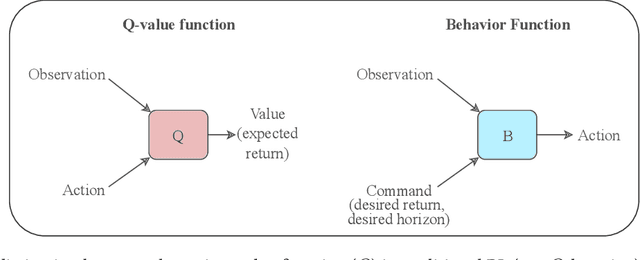



Traditional Reinforcement Learning (RL) algorithms either predict rewards with value functions or maximize them using policy search. We study an alternative: Upside-Down Reinforcement Learning (Upside-Down RL or UDRL), that solves RL problems primarily using supervised learning techniques. Many of its main principles are outlined in a companion report [34]. Here we present the first concrete implementation of UDRL and demonstrate its feasibility on certain episodic learning problems. Experimental results show that its performance can be surprisingly competitive with, and even exceed that of traditional baseline algorithms developed over decades of research.
Hindsight policy gradients
Feb 20, 2019
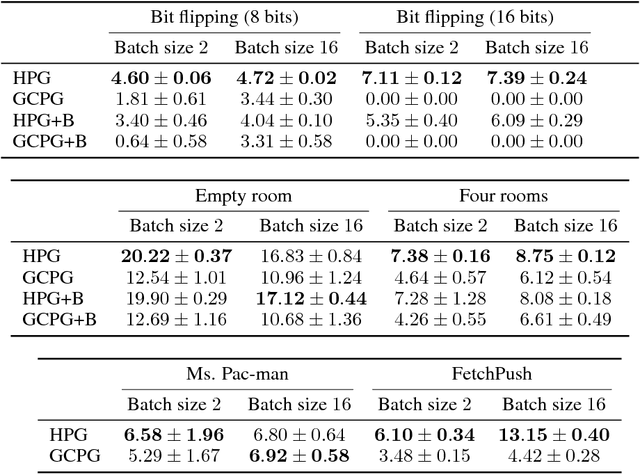
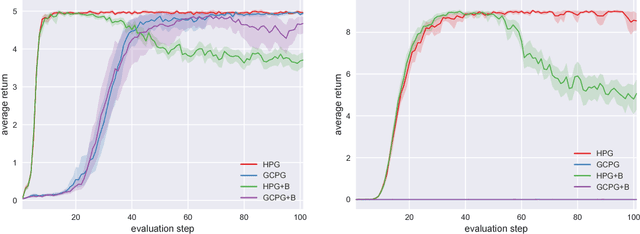
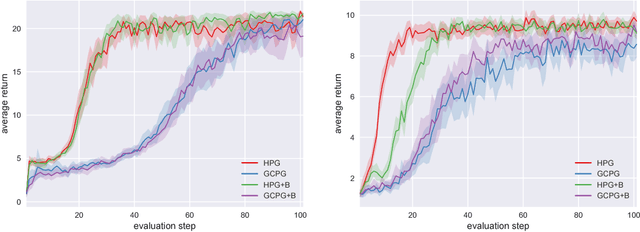
A reinforcement learning agent that needs to pursue different goals across episodes requires a goal-conditional policy. In addition to their potential to generalize desirable behavior to unseen goals, such policies may also enable higher-level planning based on subgoals. In sparse-reward environments, the capacity to exploit information about the degree to which an arbitrary goal has been achieved while another goal was intended appears crucial to enable sample efficient learning. However, reinforcement learning agents have only recently been endowed with such capacity for hindsight. In this paper, we demonstrate how hindsight can be introduced to policy gradient methods, generalizing this idea to a broad class of successful algorithms. Our experiments on a diverse selection of sparse-reward environments show that hindsight leads to a remarkable increase in sample efficiency.
Self-Driving Cars: A Survey
Jan 14, 2019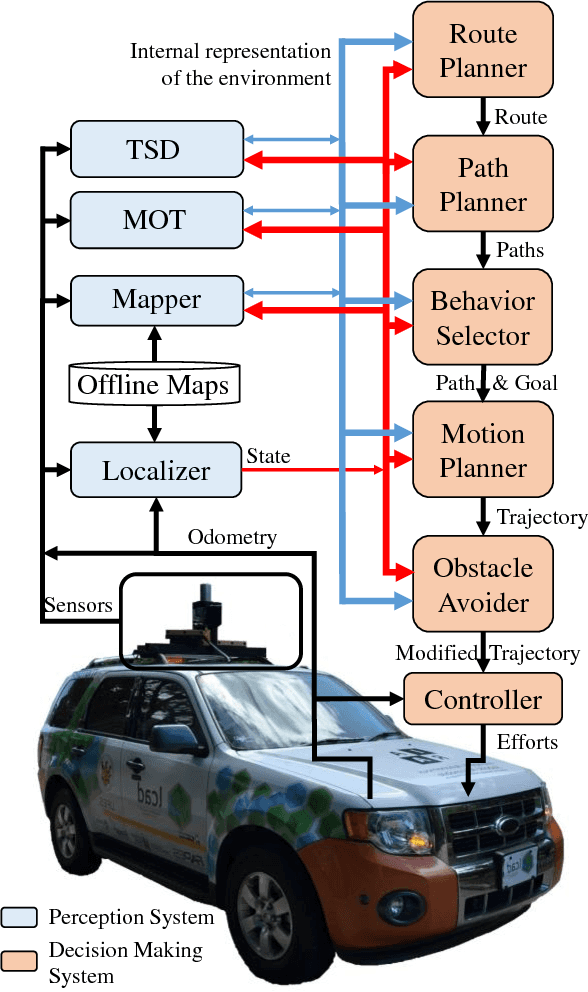


We survey research on self-driving cars published in the literature focusing on autonomous cars developed since the DARPA challenges, which are equipped with an autonomy system that can be categorized as SAE level 3 or higher. The architecture of the autonomy system of self-driving cars is typically organized into the perception system and the decision-making system. The perception system is generally divided into many subsystems responsible for tasks such as self-driving-car localization, static obstacles mapping, moving obstacles detection and tracking, road mapping, traffic signalization detection and recognition, among others. The decision-making system is commonly partitioned as well into many subsystems responsible for tasks such as route planning, path planning, behavior selection, motion planning, and control. In this survey, we present the typical architecture of the autonomy system of self-driving cars. We also review research on relevant methods for perception and decision making. Furthermore, we present a detailed description of the architecture of the autonomy system of the UFES's car, IARA. Finally, we list prominent autonomous research cars developed by technology companies and reported in the media.
Map Memorization and Forgetting in the IARA Autonomous Car
Oct 04, 2018
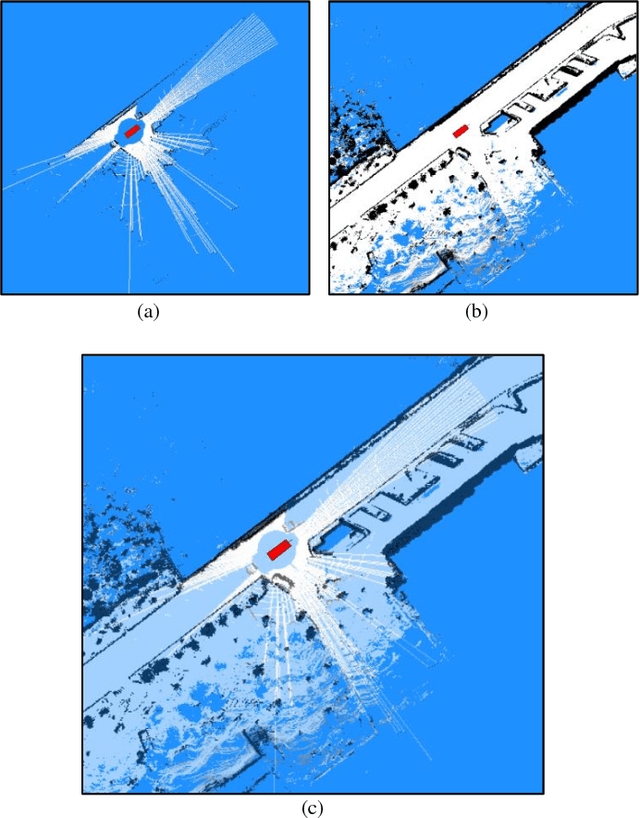
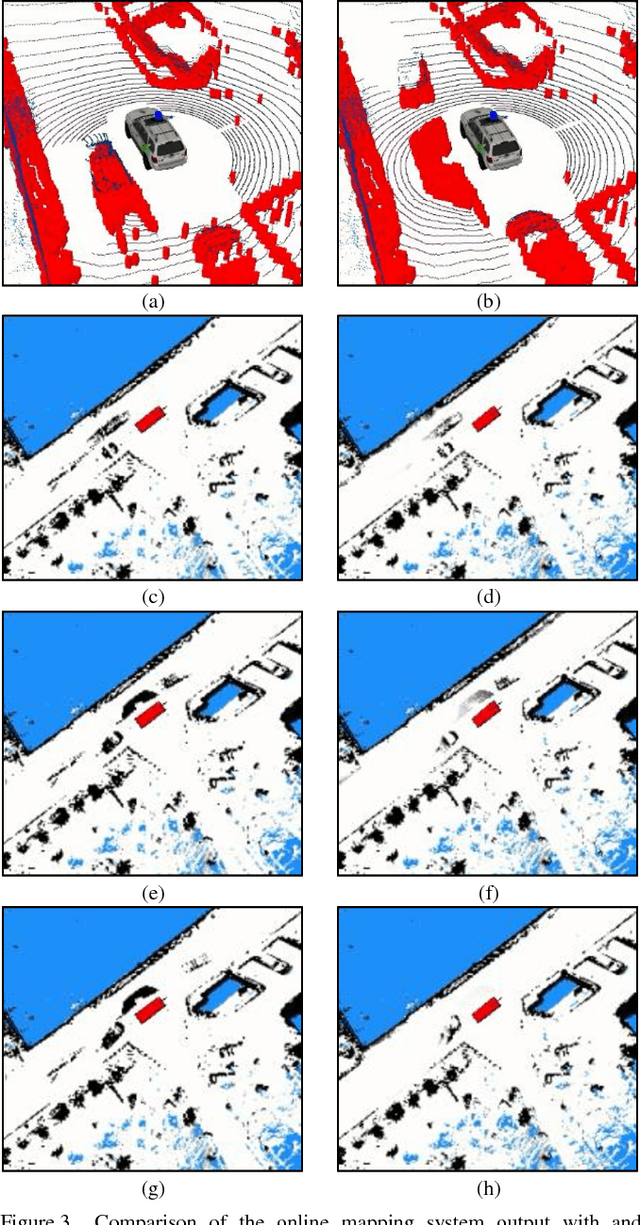
In this work, we present a novel strategy for correcting imperfections in occupancy grid maps called map decay. The objective of map decay is to correct invalid occupancy probabilities of map cells that are unobservable by sensors. The strategy was inspired by an analogy between the memory architecture believed to exist in the human brain and the maps maintained by an autonomous vehicle. It consists in merging sensory information obtained during runtime (online) with a priori data from a high-precision map constructed offline. In map decay, cells observed by sensors are updated using traditional occupancy grid mapping techniques and unobserved cells are adjusted so that their occupancy probabilities tend to the values found in the offline map. This strategy is grounded in the idea that the most precise information available about an unobservable cell is the value found in the high-precision offline map. Map decay was successfully tested and is still in use in the IARA autonomous vehicle from Universidade Federal do Esp\'irito Santo.
A Model-Predictive Motion Planner for the IARA Autonomous Car
Nov 09, 2017
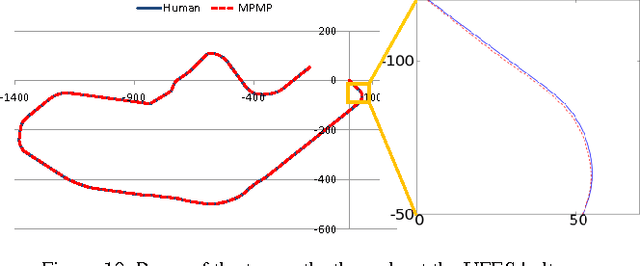

We present the Model-Predictive Motion Planner (MPMP) of the Intelligent Autonomous Robotic Automobile (IARA). IARA is a fully autonomous car that uses a path planner to compute a path from its current position to the desired destination. Using this path, the current position, a goal in the path and a map, IARA's MPMP is able to compute smooth trajectories from its current position to the goal in less than 50 ms. MPMP computes the poses of these trajectories so that they follow the path closely and, at the same time, are at a safe distance of eventual obstacles. Our experiments have shown that MPMP is able to compute trajectories that precisely follow a path produced by a Human driver (distance of 0.15 m in average) while smoothly driving IARA at speeds of up to 32.4 km/h (9 m/s).
* This is a preprint. Accepted by 2017 IEEE International Conference on Robotics and Automation (ICRA)