 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotated History of Modern AI and Deep Learning
Dec 29, 2022Machine learning is the science of credit assignment: finding patterns in observations that predict the consequences of actions and help to improve future performance. Credit assignment is also required for human understanding of how the world works, not only for individuals navigating daily life, but also for academic professionals like historians who interpret the present in light of past events. Here I focus on the history of modern artificial intelligence (AI) which is dominated by artificial neural networks (NNs) and deep learning, both conceptually closer to the old field of cybernetics than to what's been called AI since 1956 (e.g., expert systems and logic programming). A modern history of AI will emphasize breakthroughs outside of the focus of traditional AI text books, in particular, mathematical foundations of today's NNs such as the chain rule (1676), the first NNs (linear regression, circa 1800), and the first working deep learners (1965-). From the perspective of 2022, I provide a timeline of the -- in hindsight -- most important relevant events in the history of NNs, deep learning, AI, computer science, and mathematics in general, crediting those who laid foundations of the field. The text contains numerous hyperlinks to relevant overview sites from my AI Blog. It supplements my previous deep learning survey (2015) which provides hundreds of additional references. Finally, to round it off, I'll put things in a broader historic context spanning the time since the Big Bang until when the universe will be many times older than it is now.
Deep Learning: Our Miraculous Year 1990-1991
May 12, 2020In 2020, we will celebrate that many of the basic ideas behind the deep learning revolution were published three decades ago within fewer than 12 months in our "Annus Mirabilis" or "Miraculous Year" 1990-1991 at TU Munich. Back then, few people were interested, but a quarter century later, neural networks based on these ideas were on over 3 billion devices such as smartphones, and used many billions of times per day, consuming a significant fraction of the world's compute.
Reinforcement Learning Upside Down: Don't Predict Rewards -- Just Map Them to Actions
Dec 05, 2019We transform reinforcement learning (RL) into a form of supervised learning (SL) by turning traditional RL on its head, calling this Upside Down RL (UDRL). Standard RL predicts rewards, while UDRL instead uses rewards as task-defining inputs, together with representations of time horizons and other computable functions of historic and desired future data. UDRL learns to interpret these input observations as commands, mapping them to actions (or action probabilities) through SL on past (possibly accidental) experience. UDRL generalizes to achieve high rewards or other goals, through input commands such as: get lots of reward within at most so much time! A separate paper [61] on first experiments with UDRL shows that even a pilot version of UDRL can outperform traditional baseline algorithms on certain challenging RL problems. We also introduce a related simple but general approach for teaching a robot to imitate humans. First videotape humans imitating the robot's current behaviors, then let the robot learn through SL to map the videos (as input commands) to these behaviors, then let it generalize and imitate videos of humans executing previously unknown behavior. This Imitate-Imitator concept may actually explain why biological evolution has resulted in parents who imitate the babbling of their babies.
Unsupervised Minimax: Adversarial Curiosity, Generative Adversarial Networks, and Predictability Minimization
Jun 11, 2019
Generative Adversarial Networks (GANs) learn to model data distributions through two unsupervised neural networks, each minimizing the objective function maximized by the other. We relate this game theoretic strategy to earlier neural networks playing unsupervised minimax games. (i) GANs can be formulated as a special case of Adversarial Curiosity (1990) based on a minimax duel between two networks, one generating data through its probabilistic actions, the other predicting consequences thereof. (ii) We correct a previously published claim that Predictability Minimization (PM, 1990s) is not based on a minimax game. PM models data distributions through a neural encoder that maximizes the objective function minimized by a neural predictor of the code components.
Hindsight policy gradients
Feb 20, 2019
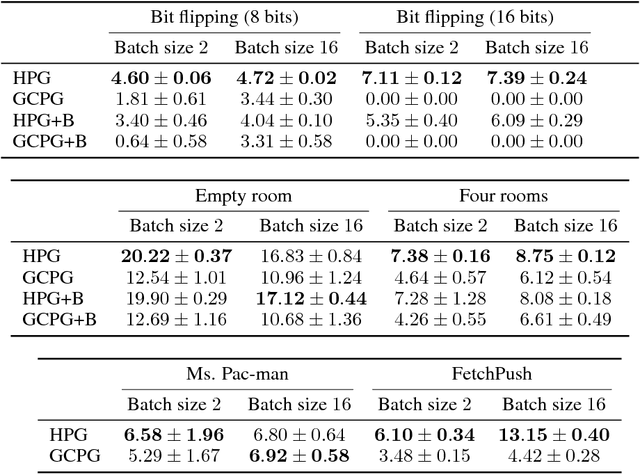
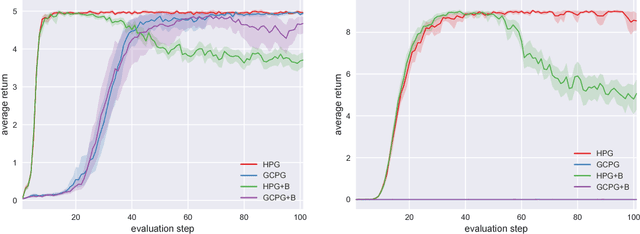
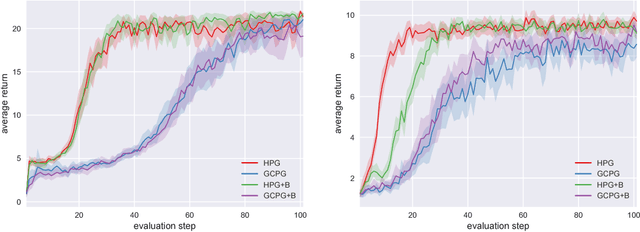
A reinforcement learning agent that needs to pursue different goals across episodes requires a goal-conditional policy. In addition to their potential to generalize desirable behavior to unseen goals, such policies may also enable higher-level planning based on subgoals. In sparse-reward environments, the capacity to exploit information about the degree to which an arbitrary goal has been achieved while another goal was intended appears crucial to enable sample efficient learning. However, reinforcement learning agents have only recently been endowed with such capacity for hindsight. In this paper, we demonstrate how hindsight can be introduced to policy gradient methods, generalizing this idea to a broad class of successful algorithms. Our experiments on a diverse selection of sparse-reward environments show that hindsight leads to a remarkable increase in sample efficiency.
Investigations on End-to-End Audiovisual Fusion
Apr 30, 2018
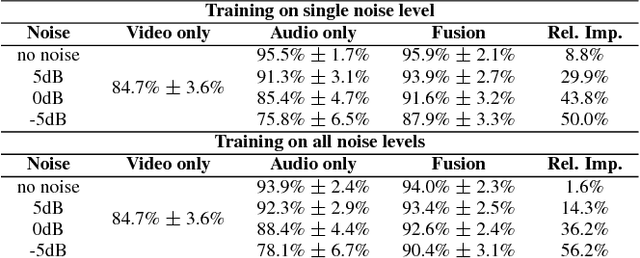
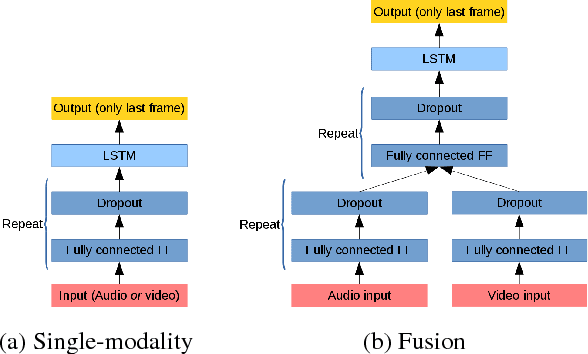

Audiovisual speech recognition (AVSR) is a method to alleviate the adverse effect of noise in the acoustic signal. Leveraging recent developments in deep neural network-based speech recognition, we present an AVSR neural network architecture which is trained end-to-end, without the need to separately model the process of decision fusion as in conventional (e.g. HMM-based) systems. The fusion system outperforms single-modality recognition under all noise conditions. Investigation of the saliency of the input features shows that the neural network automatically adapts to different noise levels in the acoustic signal.
* Published at ICASSP 2018
One Big Net For Everything
Feb 24, 2018I apply recent work on "learning to think" (2015) and on PowerPlay (2011) to the incremental training of an increasingly general problem solver, continually learning to solve new tasks without forgetting previous skills. The problem solver is a single recurrent neural network (or similar general purpose computer) called ONE. ONE is unusual in the sense that it is trained in various ways, e.g., by black box optimization / reinforcement learning / artificial evolution as well as supervised / unsupervised learning. For example, ONE may learn through neuroevolution to control a robot through environment-changing actions, and learn through unsupervised gradient descent to predict future inputs and vector-valued reward signals as suggested in 1990. User-given tasks can be defined through extra goal-defining input patterns, also proposed in 1990. Suppose ONE has already learned many skills. Now a copy of ONE can be re-trained to learn a new skill, e.g., through neuroevolution without a teacher. Here it may profit from re-using previously learned subroutines, but it may also forget previous skills. Then ONE is retrained in PowerPlay style (2011) on stored input/output traces of (a) ONE's copy executing the new skill and (b) previous instances of ONE whose skills are still considered worth memorizing. Simultaneously, ONE is retrained on old traces (even those of unsuccessful trials) to become a better predictor, without additional expensive interaction with the enviroment. More and more control and prediction skills are thus collapsed into ONE, like in the chunker-automatizer system of the neural history compressor (1991). This forces ONE to relate partially analogous skills (with shared algorithmic information) to each other, creating common subroutines in form of shared subnetworks of ONE, to greatly speed up subsequent learning of additional, novel but algorithmically related skills.
Improving Speaker-Independent Lipreading with Domain-Adversarial Training
Aug 04, 2017
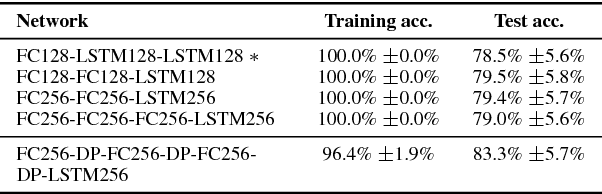
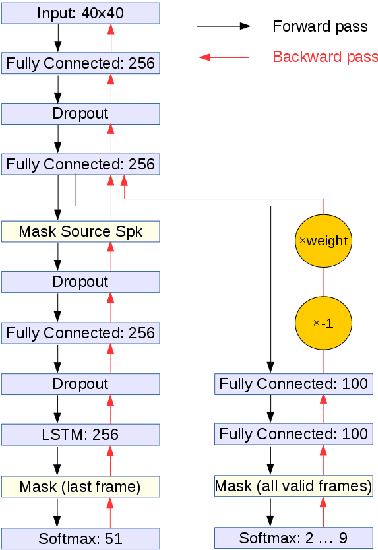

We present a Lipreading system, i.e. a speech recognition system using only visual features, which uses domain-adversarial training for speaker independence. Domain-adversarial training is integrated into the optimization of a lipreader based on a stack of feedforward and LSTM (Long Short-Term Memory) recurrent neural networks, yielding an end-to-end trainable system which only requires a very small number of frames of untranscribed target data to substantially improve the recognition accuracy on the target speaker. On pairs of different source and target speakers, we achieve a relative accuracy improvement of around 40% with only 15 to 20 seconds of untranscribed target speech data. On multi-speaker training setups, the accuracy improvements are smaller but still substantial.
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models
Nov 30, 2015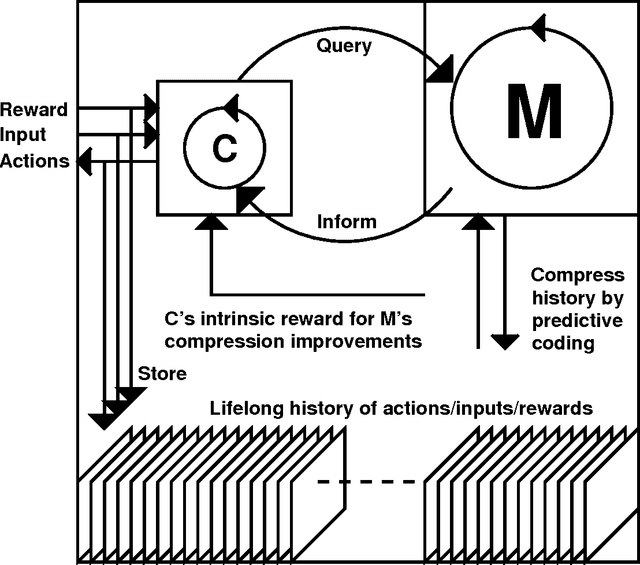
This paper addresses the general problem of reinforcement learning (RL) in partially observable environments. In 2013, our large RL recurrent neural networks (RNNs) learned from scratch to drive simulated cars from high-dimensional video input. However, real brains are more powerful in many ways. In particular, they learn a predictive model of their initially unknown environment, and somehow use it for abstract (e.g., hierarchical) planning and reasoning. Guided by algorithmic information theory, we describe RNN-based AIs (RNNAIs) designed to do the same. Such an RNNAI can be trained on never-ending sequences of tasks, some of them provided by the user, others invented by the RNNAI itself in a curious, playful fashion, to improve its RNN-based world model. Unlike our previous model-building RNN-based RL machines dating back to 1990, the RNNAI learns to actively query its model for abstract reasoning and planning and decision making, essentially "learning to think." The basic ideas of this report can be applied to many other cases where one RNN-like system exploits the algorithmic information content of another. They are taken from a grant proposal submitted in Fall 2014, and also explain concepts such as "mirror neurons." Experimental results will be described in separate papers.
Parallel Multi-Dimensional LSTM, With Application to Fast Biomedical Volumetric Image Segmentation
Jun 24, 2015
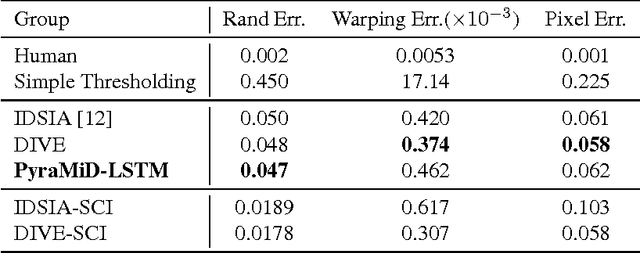

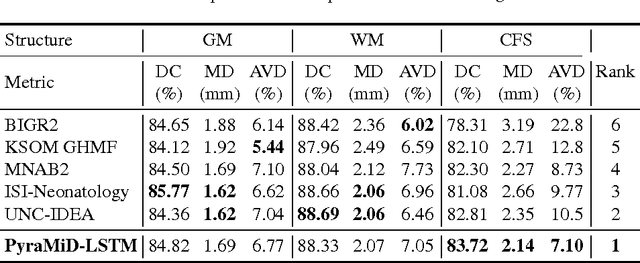
Convolutional Neural Networks (CNNs) can be shifted across 2D images or 3D videos to segment them. They have a fixed input size and typically perceive only small local contexts of the pixels to be classified as foreground or background. In contrast, Multi-Dimensional Recurrent NNs (MD-RNNs) can perceive the entire spatio-temporal context of each pixel in a few sweeps through all pixels, especially when the RNN is a Long Short-Term Memory (LSTM). Despite these theoretical advantages, however, unlike CNNs, previous MD-LSTM variants were hard to parallelize on GPUs. Here we re-arrange the traditional cuboid order of computations in MD-LSTM in pyramidal fashion. The resulting PyraMiD-LSTM is easy to parallelize, especially for 3D data such as stacks of brain slice images. PyraMiD-LSTM achieved best known pixel-wise brain image segmentation results on MRBrainS13 (and competitive results on EM-ISBI12).