 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Token Divergence: Measuring and Steering In-Context Computation Density
Dec 28, 2025Measuring the in-context computational effort of language models is a key challenge, as metrics like next-token loss fail to capture reasoning complexity. Prior methods based on latent state compressibility can be invasive and unstable. We propose Multiple Token Divergence (MTD), a simple measure of computational effort defined as the KL divergence between a model's full output distribution and that of a shallow, auxiliary prediction head. MTD can be computed directly from pre-trained models with multiple prediction heads, requiring no additional training. Building on this, we introduce Divergence Steering, a novel decoding method to control the computational character of generated text. We empirically show that MTD is more effective than prior methods at distinguishing complex tasks from simple ones. On mathematical reasoning benchmarks, MTD correlates positively with problem difficulty. Lower MTD is associated with more accurate reasoning. MTD provides a practical, lightweight tool for analyzing and steering the computational dynamics of language models.
Direct Molecular Polarizability Prediction with SO(3) Equivariant Local Frame GNNs
Nov 10, 2025

We introduce a novel equivariant graph neural network (GNN) architecture designed to predict the tensorial response properties of molecules. Unlike traditional frameworks that focus on regressing scalar quantities and derive tensorial properties from their derivatives, our approach maintains $SO(3)$-equivariance through the use of local coordinate frames. Our GNN effectively captures geometric information by integrating scalar, vector, and tensor channels within a local message-passing framework. To assess the accuracy of our model, we apply it to predict the polarizabilities of molecules in the QM7-X dataset and show that tensorial message passing outperforms scalar message passing models. This work marks an advancement towards developing structured, geometry-aware neural models for molecular property prediction.
ResNets Are Deeper Than You Think
Jun 17, 2025Residual connections remain ubiquitous in modern neural network architectures nearly a decade after their introduction. Their widespread adoption is often credited to their dramatically improved trainability: residual networks train faster, more stably, and achieve higher accuracy than their feedforward counterparts. While numerous techniques, ranging from improved initialization to advanced learning rate schedules, have been proposed to close the performance gap between residual and feedforward networks, this gap has persisted. In this work, we propose an alternative explanation: residual networks do not merely reparameterize feedforward networks, but instead inhabit a different function space. We design a controlled post-training comparison to isolate generalization performance from trainability; we find that variable-depth architectures, similar to ResNets, consistently outperform fixed-depth networks, even when optimization is unlikely to make a difference. These results suggest that residual connections confer performance advantages beyond optimization, pointing instead to a deeper inductive bias aligned with the structure of natural data.
Accelerating the inference of string generation-based chemical reaction models for industrial applications
Jul 12, 2024Template-free SMILES-to-SMILES translation models for reaction prediction and single-step retrosynthesis are of interest for industrial applications in computer-aided synthesis planning systems due to their state-of-the-art accuracy. However, they suffer from slow inference speed. We present a method to accelerate inference in autoregressive SMILES generators through speculative decoding by copying query string subsequences into target strings in the right places. We apply our method to the molecular transformer implemented in Pytorch Lightning and achieve over 3X faster inference in reaction prediction and single-step retrosynthesis, with no loss in accuracy.
Diff-ETS: Learning a Diffusion Probabilistic Model for Electromyography-to-Speech Conversion
May 11, 2024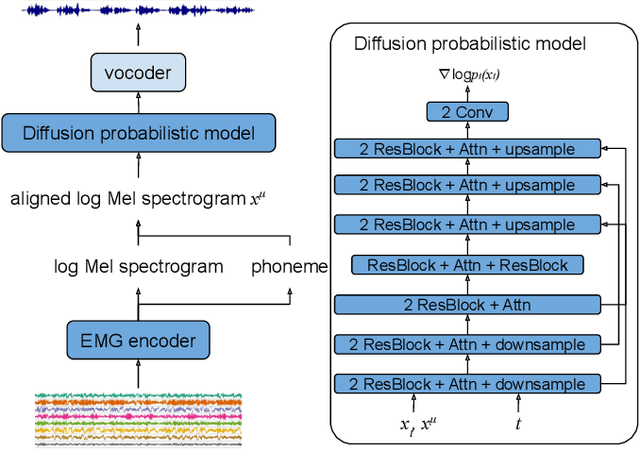
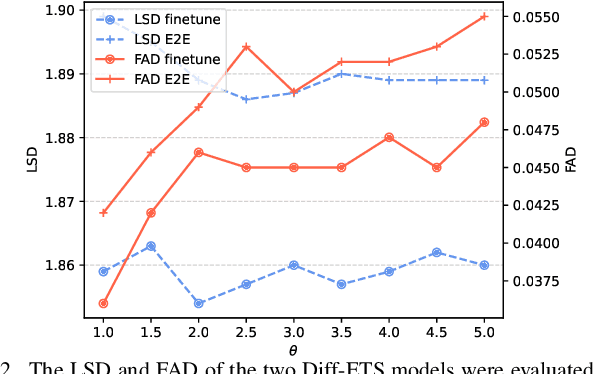
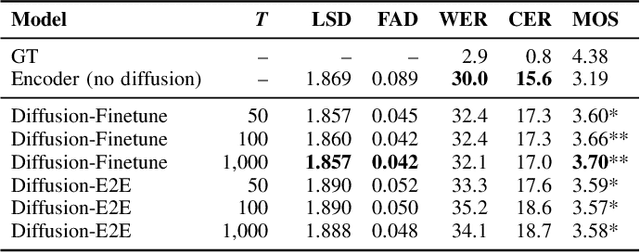
Electromyography-to-Speech (ETS) conversion has demonstrated its potential for silent speech interfaces by generating audible speech from Electromyography (EMG) signals during silent articulations. ETS models usually consist of an EMG encoder which converts EMG signals to acoustic speech features, and a vocoder which then synthesises the speech signals. Due to an inadequate amount of available data and noisy signals, the synthesised speech often exhibits a low level of naturalness. In this work, we propose Diff-ETS, an ETS model which uses a score-based diffusion probabilistic model to enhance the naturalness of synthesised speech. The diffusion model is applied to improve the quality of the acoustic features predicted by an EMG encoder. In our experiments, we evaluated fine-tuning the diffusion model on predictions of a pre-trained EMG encoder, and training both models in an end-to-end fashion. We compared Diff-ETS with a baseline ETS model without diffusion using objective metrics and a listening test. The results indicated the proposed Diff-ETS significantly improved speech naturalness over the baseline.
Spreads in Effective Learning Rates: The Perils of Batch Normalization During Early Training
Jun 01, 2023Excursions in gradient magnitude pose a persistent challenge when training deep networks. In this paper, we study the early training phases of deep normalized ReLU networks, accounting for the induced scale invariance by examining effective learning rates (LRs). Starting with the well-known fact that batch normalization (BN) leads to exponentially exploding gradients at initialization, we develop an ODE-based model to describe early training dynamics. Our model predicts that in the gradient flow, effective LRs will eventually equalize, aligning with empirical findings on warm-up training. Using large LRs is analogous to applying an explicit solver to a stiff non-linear ODE, causing overshooting and vanishing gradients in lower layers after the first step. Achieving overall balance demands careful tuning of LRs, depth, and (optionally) momentum. Our model predicts the formation of spreads in effective LRs, consistent with empirical measurements. Moreover, we observe that large spreads in effective LRs result in training issues concerning accuracy, indicating the importance of controlling these dynamics. To further support a causal relationship, we implement a simple scheduling scheme prescribing uniform effective LRs across layers and confirm accuracy benefits.
Nonlinearities in Steerable SO(2)-Equivariant CNNs
Sep 14, 2021
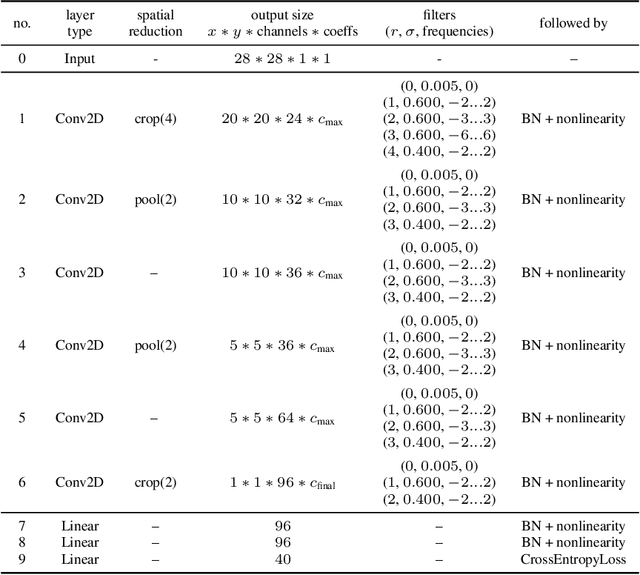


Invariance under symmetry is an important problem in machine learning. Our paper looks specifically at equivariant neural networks where transformations of inputs yield homomorphic transformations of outputs. Here, steerable CNNs have emerged as the standard solution. An inherent problem of steerable representations is that general nonlinear layers break equivariance, thus restricting architectural choices. Our paper applies harmonic distortion analysis to illuminate the effect of nonlinearities on Fourier representations of SO(2). We develop a novel FFT-based algorithm for computing representations of non-linearly transformed activations while maintaining band-limitation. It yields exact equivariance for polynomial (approximations of) nonlinearities, as well as approximate solutions with tunable accuracy for general functions. We apply the approach to build a fully E(3)-equivariant network for sampled 3D surface data. In experiments with 2D and 3D data, we obtain results that compare favorably to the state-of-the-art in terms of accuracy while permitting continuous symmetry and exact equivariance.
Deep Non-Line-of-Sight Reconstruction
Jan 29, 2020



The recent years have seen a surge of interest in methods for imaging beyond the direct line of sight. The most prominent techniques rely on time-resolved optical impulse responses, obtained by illuminating a diffuse wall with an ultrashort light pulse and observing multi-bounce indirect reflections with an ultrafast time-resolved imager. Reconstruction of geometry from such data, however, is a complex non-linear inverse problem that comes with substantial computational demands. In this paper, we employ convolutional feed-forward networks for solving the reconstruction problem efficiently while maintaining good reconstruction quality. Specifically, we devise a tailored autoencoder architecture, trained end-to-end, that maps transient images directly to a depth map representation. Training is done using an efficient transient renderer for diffuse three-bounce indirect light transport that enables the quick generation of large amounts of training data for the network. We examine the performance of our method on a variety of synthetic and experimental datasets and its dependency on the choice of training data and augmentation strategies, as well as architectural features. We demonstrate that our feed-forward network, even though it is trained solely on synthetic data, generalizes to measured data from SPAD sensors and is able to obtain results that are competitive with model-based reconstruction methods.
Progressive Stochastic Binarization of Deep Networks
Apr 03, 2019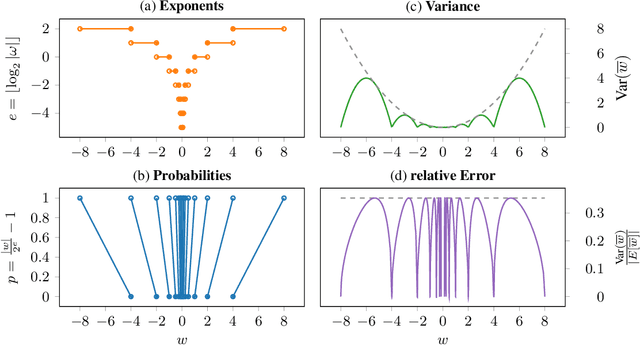
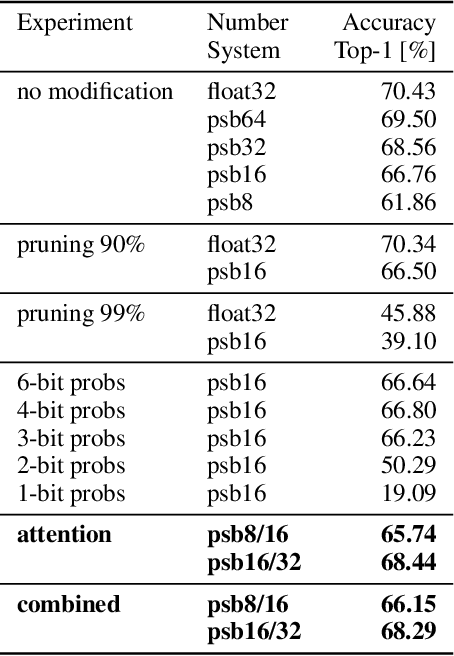
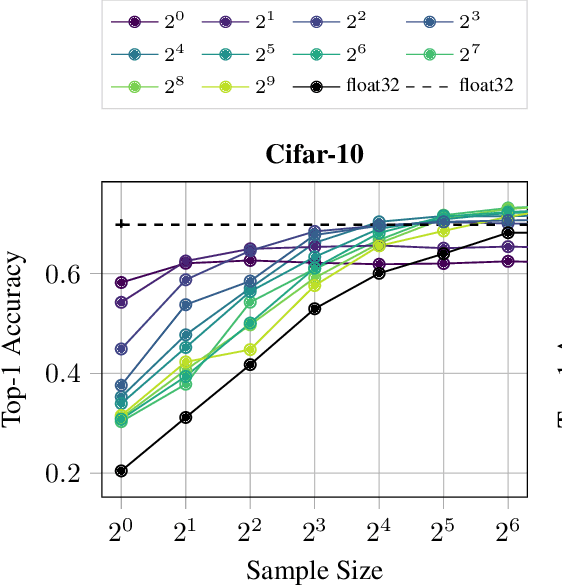

A plethora of recent research has focused on improving the memory footprint and inference speed of deep networks by reducing the complexity of (i) numerical representations (for example, by deterministic or stochastic quantization) and (ii) arithmetic operations (for example, by binarization of weights). We propose a stochastic binarization scheme for deep networks that allows for efficient inference on hardware by restricting itself to additions of small integers and fixed shifts. Unlike previous approaches, the underlying randomized approximation is progressive, thus permitting an adaptive control of the accuracy of each operation at run-time. In a low-precision setting, we match the accuracy of previous binarized approaches. Our representation is unbiased - it approaches continuous computation with increasing sample size. In a high-precision regime, the computational costs are competitive with previous quantization schemes. Progressive stochastic binarization also permits localized, dynamic accuracy control within a single network, thereby providing a new tool for adaptively focusing computational attention. We evaluate our method on networks of various architectures, already pretrained on ImageNet. With representational costs comparable to previous schemes, we obtain accuracies close to the original floating point implementation. This includes pruned networks, except the known special case of certain types of separated convolutions. By focusing computational attention using progressive sampling, we reduce inference costs on ImageNet further by a factor of up to 33% (before network pruning).
Investigations on End-to-End Audiovisual Fusion
Apr 30, 2018
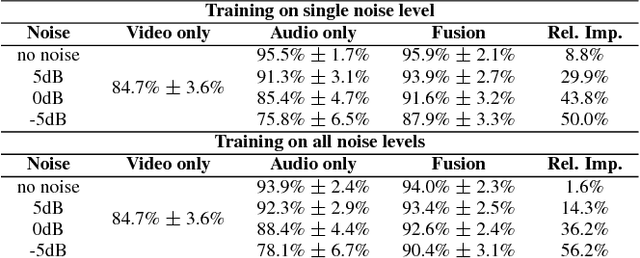
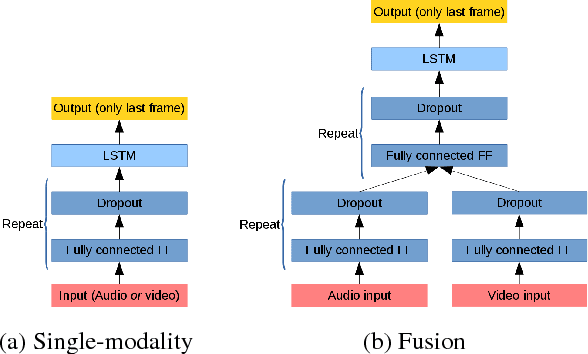

Audiovisual speech recognition (AVSR) is a method to alleviate the adverse effect of noise in the acoustic signal. Leveraging recent developments in deep neural network-based speech recognition, we present an AVSR neural network architecture which is trained end-to-end, without the need to separately model the process of decision fusion as in conventional (e.g. HMM-based) systems. The fusion system outperforms single-modality recognition under all noise conditions. Investigation of the saliency of the input features shows that the neural network automatically adapts to different noise levels in the acoustic signal.
* Published at ICASSP 2018