Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigations on End-to-End Audiovisual Fusion
Paper and Code
Apr 30, 2018
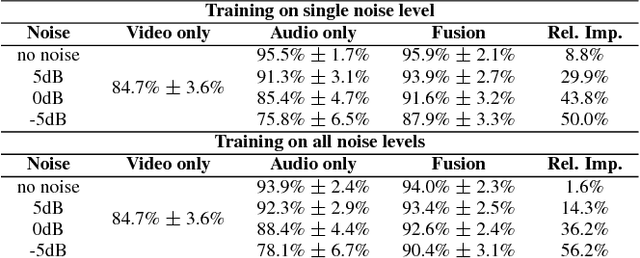
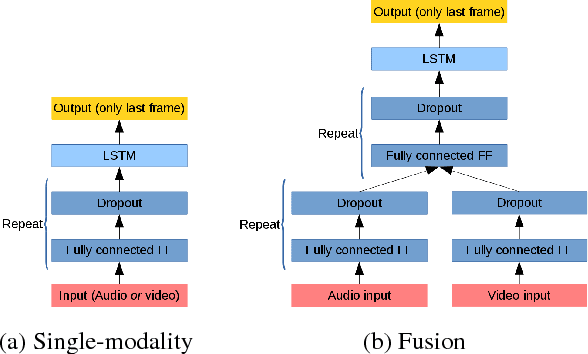

Audiovisual speech recognition (AVSR) is a method to alleviate the adverse effect of noise in the acoustic signal. Leveraging recent developments in deep neural network-based speech recognition, we present an AVSR neural network architecture which is trained end-to-end, without the need to separately model the process of decision fusion as in conventional (e.g. HMM-based) systems. The fusion system outperforms single-modality recognition under all noise conditions. Investigation of the saliency of the input features shows that the neural network automatically adapts to different noise levels in the acoustic signal.
* Proceedings of the 2018 IEEE International Conference on
Acoustics, Speech and Signal Processing, pages 3041 - 3045 * Published at ICASSP 2018
View paper on