 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudit Me If You Can: Query-Efficient Active Fairness Auditing of Black-Box LLMs
Jan 06, 2026Large Language Models (LLMs) exhibit systematic biases across demographic groups. Auditing is proposed as an accountability tool for black-box LLM applications, but suffers from resource-intensive query access. We conceptualise auditing as uncertainty estimation over a target fairness metric and introduce BAFA, the Bounded Active Fairness Auditor for query-efficient auditing of black-box LLMs. BAFA maintains a version space of surrogate models consistent with queried scores and computes uncertainty intervals for fairness metrics (e.g., $Δ$ AUC) via constrained empirical risk minimisation. Active query selection narrows these intervals to reduce estimation error. We evaluate BAFA on two standard fairness dataset case studies: \textsc{CivilComments} and \textsc{Bias-in-Bios}, comparing against stratified sampling, power sampling, and ablations. BAFA achieves target error thresholds with up to 40$\times$ fewer queries than stratified sampling (e.g., 144 vs 5,956 queries at $\varepsilon=0.02$ for \textsc{CivilComments}) for tight thresholds, demonstrates substantially better performance over time, and shows lower variance across runs. These results suggest that active sampling can reduce resources needed for independent fairness auditing with LLMs, supporting continuous model evaluations.
Out of Sight Out of Mind, Out of Sight Out of Mind: Measuring Bias in Language Models Against Overlooked Marginalized Groups in Regional Contexts
Apr 17, 2025
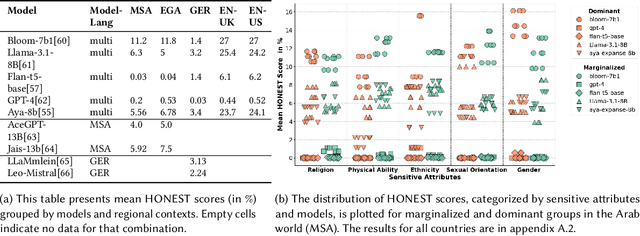


We know that language models (LMs) form biases and stereotypes of minorities, leading to unfair treatments of members of these groups, thanks to research mainly in the US and the broader English-speaking world. As the negative behavior of these models has severe consequences for society and individuals, industry and academia are actively developing methods to reduce the bias in LMs. However, there are many under-represented groups and languages that have been overlooked so far. This includes marginalized groups that are specific to individual countries and regions in the English speaking and Western world, but crucially also almost all marginalized groups in the rest of the world. The UN estimates, that between 600 million to 1.2 billion people worldwide are members of marginalized groups and in need for special protection. If we want to develop inclusive LMs that work for everyone, we have to broaden our understanding to include overlooked marginalized groups and low-resource languages and dialects. In this work, we contribute to this effort with the first study investigating offensive stereotyping bias in 23 LMs for 270 marginalized groups from Egypt, the remaining 21 Arab countries, Germany, the UK, and the US. Additionally, we investigate the impact of low-resource languages and dialects on the study of bias in LMs, demonstrating the limitations of current bias metrics, as we measure significantly higher bias when using the Egyptian Arabic dialect versus Modern Standard Arabic. Our results show, LMs indeed show higher bias against many marginalized groups in comparison to dominant groups. However, this is not the case for Arabic LMs, where the bias is high against both marginalized and dominant groups in relation to religion and ethnicity. Our results also show higher intersectional bias against Non-binary, LGBTQIA+ and Black women.
Lost in Moderation: How Commercial Content Moderation APIs Over- and Under-Moderate Group-Targeted Hate Speech and Linguistic Variations
Mar 03, 2025Commercial content moderation APIs are marketed as scalable solutions to combat online hate speech. However, the reliance on these APIs risks both silencing legitimate speech, called over-moderation, and failing to protect online platforms from harmful speech, known as under-moderation. To assess such risks, this paper introduces a framework for auditing black-box NLP systems. Using the framework, we systematically evaluate five widely used commercial content moderation APIs. Analyzing five million queries based on four datasets, we find that APIs frequently rely on group identity terms, such as ``black'', to predict hate speech. While OpenAI's and Amazon's services perform slightly better, all providers under-moderate implicit hate speech, which uses codified messages, especially against LGBTQIA+ individuals. Simultaneously, they over-moderate counter-speech, reclaimed slurs and content related to Black, LGBTQIA+, Jewish, and Muslim people. We recommend that API providers offer better guidance on API implementation and threshold setting and more transparency on their APIs' limitations. Warning: This paper contains offensive and hateful terms and concepts. We have chosen to reproduce these terms for reasons of transparency.
Watching the Watchers: A Comparative Fairness Audit of Cloud-based Content Moderation Services
Jun 20, 2024

Online platforms face the challenge of moderating an ever-increasing volume of content, including harmful hate speech. In the absence of clear legal definitions and a lack of transparency regarding the role of algorithms in shaping decisions on content moderation, there is a critical need for external accountability. Our study contributes to filling this gap by systematically evaluating four leading cloud-based content moderation services through a third-party audit, highlighting issues such as biases against minorities and vulnerable groups that may arise through over-reliance on these services. Using a black-box audit approach and four benchmark data sets, we measure performance in explicit and implicit hate speech detection as well as counterfactual fairness through perturbation sensitivity analysis and present disparities in performance for certain target identity groups and data sets. Our analysis reveals that all services had difficulties detecting implicit hate speech, which relies on more subtle and codified messages. Moreover, our results point to the need to remove group-specific bias. It seems that biases towards some groups, such as Women, have been mostly rectified, while biases towards other groups, such as LGBTQ+ and PoC remain.
Fast whole-slide cartography in colon cancer histology using superpixels and CNN classification
Jun 30, 2021
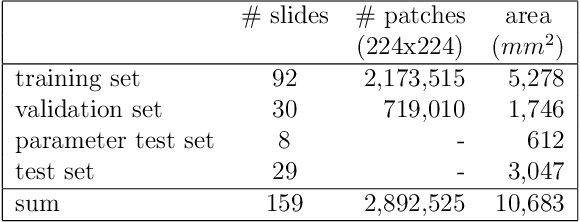
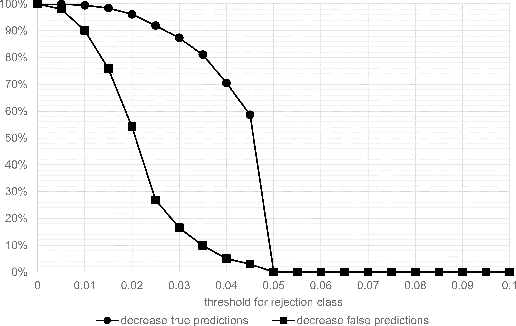
Whole-slide-image cartography is the process of automatically detecting and outlining different tissue types in digitized histological specimen. This semantic segmentation provides a basis for many follow-up analyses and can potentially guide subsequent medical decisions. Due to their large size, whole-slide-images typically have to be divided into smaller patches which are then analyzed individually using machine learning-based approaches. Thereby, local dependencies of image regions get lost and since a whole-slide-image comprises many thousands of such patches this process is inherently slow. We propose to subdivide the image into coherent regions prior to classification by grouping visually similar adjacent image pixels into larger segments, i.e. superpixels. Afterwards, only a random subset of patches per superpixel is classified and patch labels are combined into a single superpixel label. The algorithm has been developed and validated on a dataset of 159 hand-annotated whole-slide-images of colon resections and its performance has been compared to a standard patch-based approach. The algorithm shows an average speed-up of 41% on the test data and the overall accuracy is increased from 93.8% to 95.7%. We additionally propose a metric for identifying superpixels with an uncertain classification so they can be excluded from further analysis. Finally, we evaluate two potential medical applications, namely tumor area estimation including tumor invasive margin generation and tumor composition analysis.
Progressive Stochastic Binarization of Deep Networks
Apr 03, 2019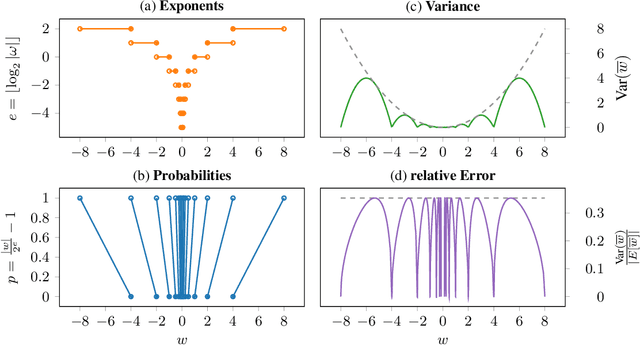
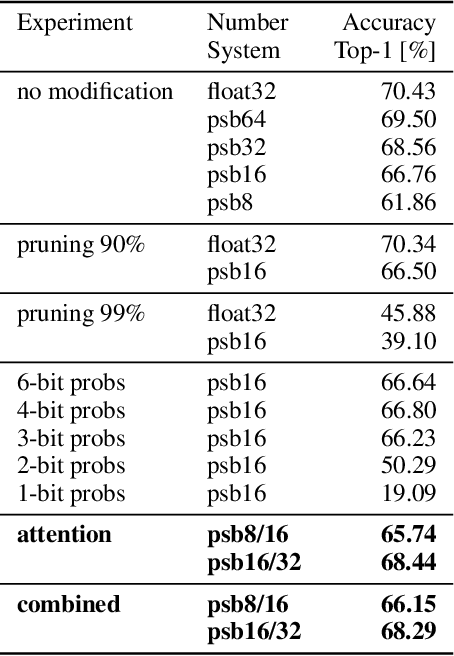
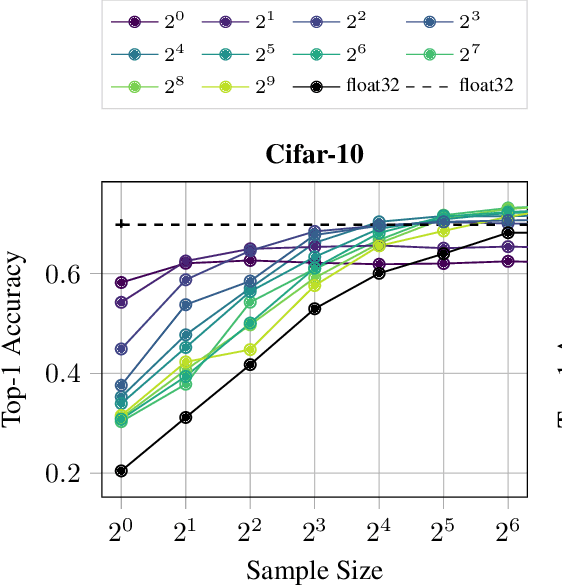

A plethora of recent research has focused on improving the memory footprint and inference speed of deep networks by reducing the complexity of (i) numerical representations (for example, by deterministic or stochastic quantization) and (ii) arithmetic operations (for example, by binarization of weights). We propose a stochastic binarization scheme for deep networks that allows for efficient inference on hardware by restricting itself to additions of small integers and fixed shifts. Unlike previous approaches, the underlying randomized approximation is progressive, thus permitting an adaptive control of the accuracy of each operation at run-time. In a low-precision setting, we match the accuracy of previous binarized approaches. Our representation is unbiased - it approaches continuous computation with increasing sample size. In a high-precision regime, the computational costs are competitive with previous quantization schemes. Progressive stochastic binarization also permits localized, dynamic accuracy control within a single network, thereby providing a new tool for adaptively focusing computational attention. We evaluate our method on networks of various architectures, already pretrained on ImageNet. With representational costs comparable to previous schemes, we obtain accuracies close to the original floating point implementation. This includes pruned networks, except the known special case of certain types of separated convolutions. By focusing computational attention using progressive sampling, we reduce inference costs on ImageNet further by a factor of up to 33% (before network pruning).