 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conditional Companion: Lived Experiences of People with Mental Health Disorders Using LLMs
Jan 30, 2026Large Language Models (LLMs) are increasingly used for mental health support, yet little is known about how people with mental health challenges engage with them, how they evaluate their usefulness, and what design opportunities they envision. We conducted 20 semi-structured interviews with people in the UK who live with mental health conditions and have used LLMs for mental health support. Through reflexive thematic analysis, we found that participants engaged with LLMs in conditional and situational ways: for immediacy, the desire for non-judgement, self-paced disclosure, cognitive reframing, and relational engagement. Simultaneously, participants articulated clear boundaries informed by prior therapeutic experience: LLMs were effective for mild-to-moderate distress but inadequate for crises, trauma, and complex social-emotional situations. We contribute empirical insights into the lived use of LLMs for mental health, highlight boundary-setting as central to their safe role, and propose design and governance directions for embedding them responsibly within care ecosystem.
Lost in Moderation: How Commercial Content Moderation APIs Over- and Under-Moderate Group-Targeted Hate Speech and Linguistic Variations
Mar 03, 2025Commercial content moderation APIs are marketed as scalable solutions to combat online hate speech. However, the reliance on these APIs risks both silencing legitimate speech, called over-moderation, and failing to protect online platforms from harmful speech, known as under-moderation. To assess such risks, this paper introduces a framework for auditing black-box NLP systems. Using the framework, we systematically evaluate five widely used commercial content moderation APIs. Analyzing five million queries based on four datasets, we find that APIs frequently rely on group identity terms, such as ``black'', to predict hate speech. While OpenAI's and Amazon's services perform slightly better, all providers under-moderate implicit hate speech, which uses codified messages, especially against LGBTQIA+ individuals. Simultaneously, they over-moderate counter-speech, reclaimed slurs and content related to Black, LGBTQIA+, Jewish, and Muslim people. We recommend that API providers offer better guidance on API implementation and threshold setting and more transparency on their APIs' limitations. Warning: This paper contains offensive and hateful terms and concepts. We have chosen to reproduce these terms for reasons of transparency.
Writer-Defined AI Personas for On-Demand Feedback Generation
Sep 19, 2023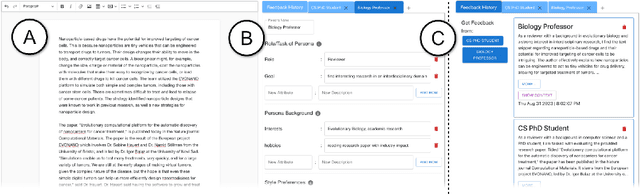
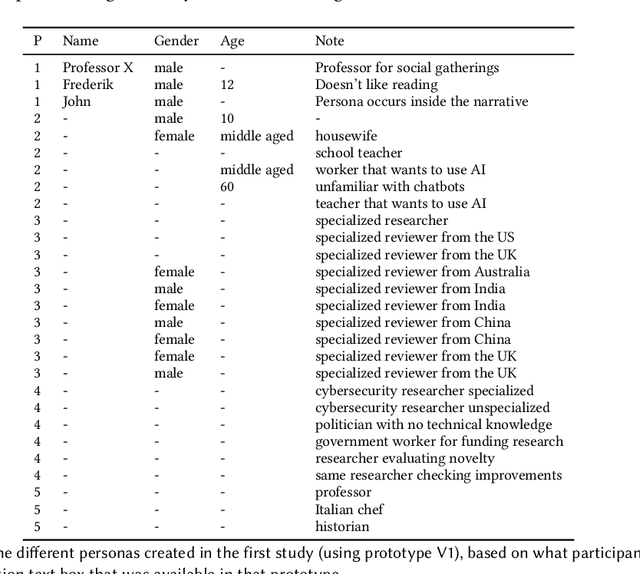
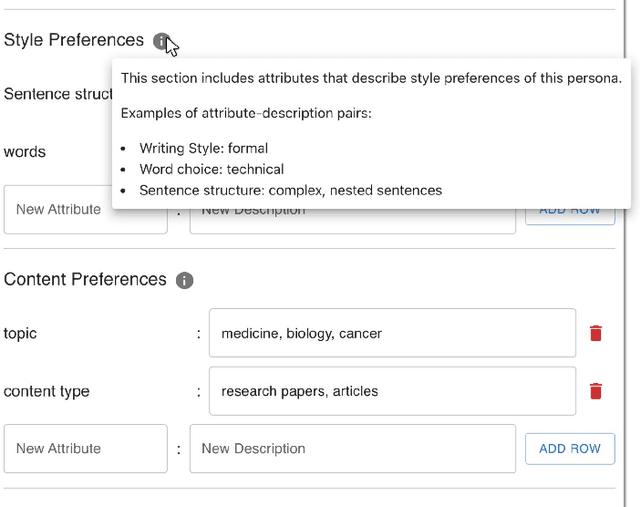
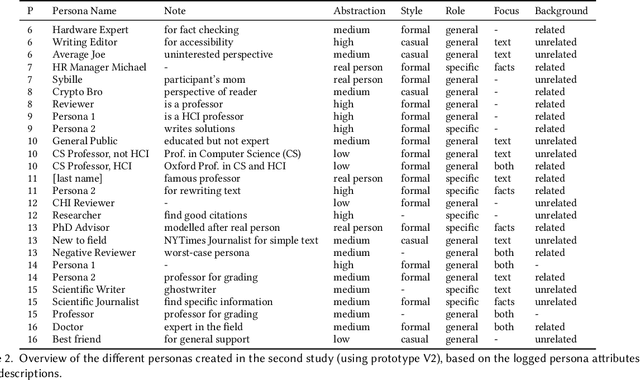
Compelling writing is tailored to its audience. This is challenging, as writers may struggle to empathize with readers, get feedback in time, or gain access to the target group. We propose a concept that generates on-demand feedback, based on writer-defined AI personas of any target audience. We explore this concept with a prototype (using GPT-3.5) in two user studies (N=5 and N=11): Writers appreciated the concept and strategically used personas for getting different perspectives. The feedback was seen as helpful and inspired revisions of text and personas, although it was often verbose and unspecific. We discuss the impact of on-demand feedback, the limited representativity of contemporary AI systems, and further ideas for defining AI personas. This work contributes to the vision of supporting writers with AI by expanding the socio-technical perspective in AI tool design: To empower creators, we also need to keep in mind their relationship to an audience.
Methods for the Design and Evaluation of HCI+NLP Systems
Feb 26, 2021

HCI and NLP traditionally focus on different evaluation methods. While HCI involves a small number of people directly and deeply, NLP traditionally relies on standardized benchmark evaluations that involve a larger number of people indirectly. We present five methodological proposals at the intersection of HCI and NLP and situate them in the context of ML-based NLP models. Our goal is to foster interdisciplinary collaboration and progress in both fields by emphasizing what the fields can learn from each other.
More Than Accuracy: Towards Trustworthy Machine Learning Interfaces for Object Recognition
Aug 05, 2020
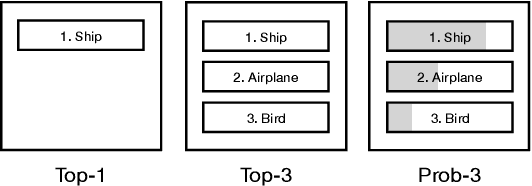
This paper investigates the user experience of visualizations of a machine learning (ML) system that recognizes objects in images. This is important since even good systems can fail in unexpected ways as misclassifications on photo-sharing websites showed. In our study, we exposed users with a background in ML to three visualizations of three systems with different levels of accuracy. In interviews, we explored how the visualization helped users assess the accuracy of systems in use and how the visualization and the accuracy of the system affected trust and reliance. We found that participants do not only focus on accuracy when assessing ML systems. They also take the perceived plausibility and severity of misclassification into account and prefer seeing the probability of predictions. Semantically plausible errors are judged as less severe than errors that are implausible, which means that system accuracy could be communicated through the types of errors.
* UMAP '20: Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization
Is It Worth the Attention? A Comparative Evaluation of Attention Layers for Argument Unit Segmentation
Jun 24, 2019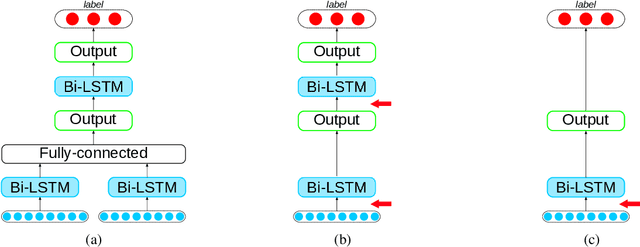
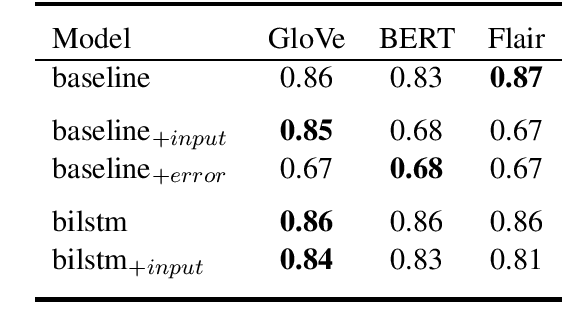
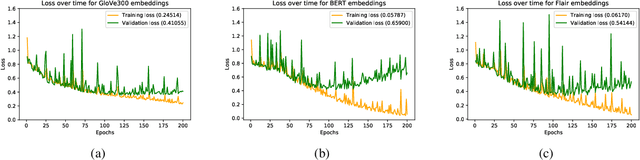
Attention mechanisms have seen some success for natural language processing downstream tasks in recent years and generated new State-of-the-Art results. A thorough evaluation of the attention mechanism for the task of Argumentation Mining is missing, though. With this paper, we report a comparative evaluation of attention layers in combination with a bidirectional long short-term memory network, which is the current state-of-the-art approach to the unit segmentation task. We also compare sentence-level contextualized word embeddings to pre-generated ones. Our findings suggest that for this task the additional attention layer does not improve upon a less complex approach. In most cases, the contextualized embeddings do also not show an improvement on the baseline score.
Generating captions without looking beyond objects
Oct 18, 2016

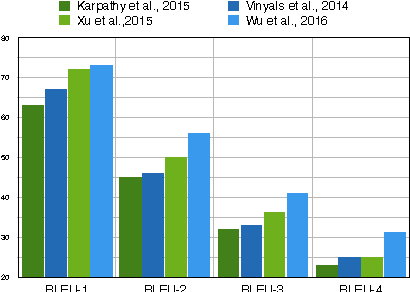
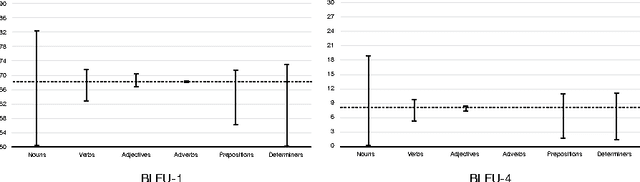
This paper explores new evaluation perspectives for image captioning and introduces a noun translation task that achieves comparative image caption generation performance by translating from a set of nouns to captions. This implies that in image captioning, all word categories other than nouns can be evoked by a powerful language model without sacrificing performance on n-gram precision. The paper also investigates lower and upper bounds of how much individual word categories in the captions contribute to the final BLEU score. A large possible improvement exists for nouns, verbs, and prepositions.
Text comparison using word vector representations and dimensionality reduction
Jul 02, 2016
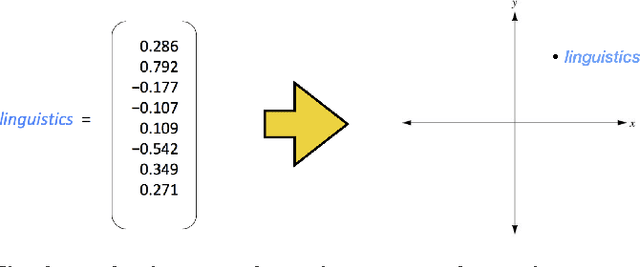


This paper describes a technique to compare large text sources using word vector representations (word2vec) and dimensionality reduction (t-SNE) and how it can be implemented using Python. The technique provides a bird's-eye view of text sources, e.g. text summaries and their source material, and enables users to explore text sources like a geographical map. Word vector representations capture many linguistic properties such as gender, tense, plurality and even semantic concepts like "capital city of". Using dimensionality reduction, a 2D map can be computed where semantically similar words are close to each other. The technique uses the word2vec model from the gensim Python library and t-SNE from scikit-learn.