 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Revisions: Quality Assessment of Claims in Argumentation at Scale
Jan 25, 2021
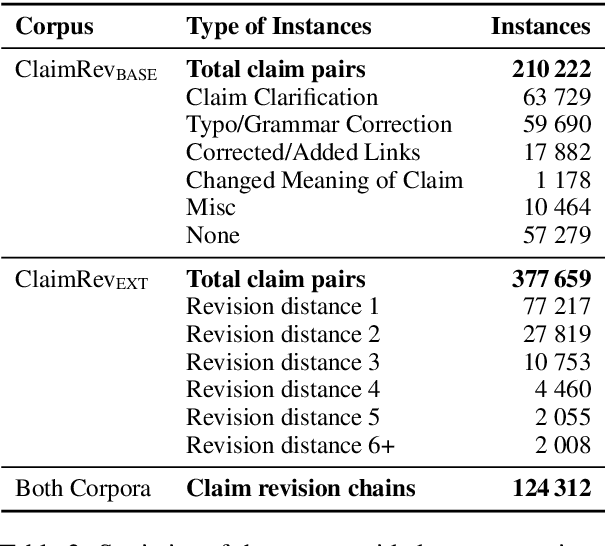

Assessing the quality of arguments and of the claims the arguments are composed of has become a key task in computational argumentation. However, even if different claims share the same stance on the same topic, their assessment depends on the prior perception and weighting of the different aspects of the topic being discussed. This renders it difficult to learn topic-independent quality indicators. In this paper, we study claim quality assessment irrespective of discussed aspects by comparing different revisions of the same claim. We compile a large-scale corpus with over 377k claim revision pairs of various types from kialo.com, covering diverse topics from politics, ethics, entertainment, and others. We then propose two tasks: (a) assessing which claim of a revision pair is better, and (b) ranking all versions of a claim by quality. Our first experiments with embedding-based logistic regression and transformer-based neural networks show promising results, suggesting that learned indicators generalize well across topics. In a detailed error analysis, we give insights into what quality dimensions of claims can be assessed reliably. We provide the data and scripts needed to reproduce all results.
Is It Worth the Attention? A Comparative Evaluation of Attention Layers for Argument Unit Segmentation
Jun 24, 2019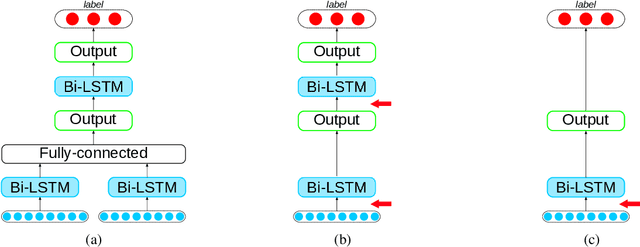
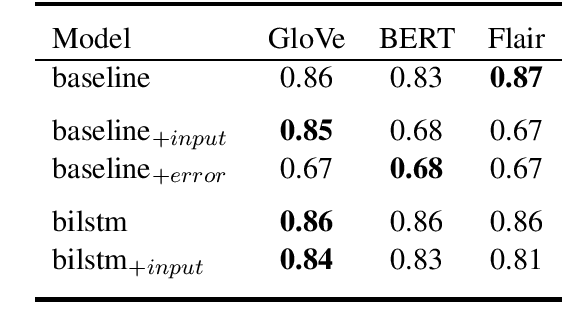
Attention mechanisms have seen some success for natural language processing downstream tasks in recent years and generated new State-of-the-Art results. A thorough evaluation of the attention mechanism for the task of Argumentation Mining is missing, though. With this paper, we report a comparative evaluation of attention layers in combination with a bidirectional long short-term memory network, which is the current state-of-the-art approach to the unit segmentation task. We also compare sentence-level contextualized word embeddings to pre-generated ones. Our findings suggest that for this task the additional attention layer does not improve upon a less complex approach. In most cases, the contextualized embeddings do also not show an improvement on the baseline score.