 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
LLM-based Rewriting of Inappropriate Argumentation using Reinforcement Learning from Machine Feedback
Jun 05, 2024Ensuring that online discussions are civil and productive is a major challenge for social media platforms. Such platforms usually rely both on users and on automated detection tools to flag inappropriate arguments of other users, which moderators then review. However, this kind of post-hoc moderation is expensive and time-consuming, and moderators are often overwhelmed by the amount and severity of flagged content. Instead, a promising alternative is to prevent negative behavior during content creation. This paper studies how inappropriate language in arguments can be computationally mitigated. We propose a reinforcement learning-based rewriting approach that balances content preservation and appropriateness based on existing classifiers, prompting an instruction-finetuned large language model (LLM) as our initial policy. Unlike related style transfer tasks, rewriting inappropriate arguments allows deleting and adding content permanently. It is therefore tackled on document level rather than sentence level. We evaluate different weighting schemes for the reward function in both absolute and relative human assessment studies. Systematic experiments on non-parallel data provide evidence that our approach can mitigate the inappropriateness of arguments while largely preserving their content. It significantly outperforms competitive baselines, including few-shot learning, prompting, and humans.
To Revise or Not to Revise: Learning to Detect Improvable Claims for Argumentative Writing Support
May 26, 2023



Optimizing the phrasing of argumentative text is crucial in higher education and professional development. However, assessing whether and how the different claims in a text should be revised is a hard task, especially for novice writers. In this work, we explore the main challenges to identifying argumentative claims in need of specific revisions. By learning from collaborative editing behaviors in online debates, we seek to capture implicit revision patterns in order to develop approaches aimed at guiding writers in how to further improve their arguments. We systematically compare the ability of common word embedding models to capture the differences between different versions of the same text, and we analyze their impact on various types of writing issues. To deal with the noisy nature of revision-based corpora, we propose a new sampling strategy based on revision distance. Opposed to approaches from prior work, such sampling can be done without employing additional annotations and judgments. Moreover, we provide evidence that using contextual information and domain knowledge can further improve prediction results. How useful a certain type of context is, depends on the issue the claim is suffering from, though.
Claim Optimization in Computational Argumentation
Dec 17, 2022



An optimal delivery of arguments is key to persuasion in any debate, both for humans and for AI systems. This requires the use of clear and fluent claims relevant to the given debate. Prior work has studied the automatic assessment of argument quality extensively. Yet, no approach actually improves the quality so far. Our work is the first step towards filling this gap. We propose the task of claim optimization: to rewrite argumentative claims to optimize their delivery. As an initial approach, we first generate a candidate set of optimized claims using a sequence-to-sequence model, such as BART, while taking into account contextual information. Our key idea is then to rerank generated candidates with respect to different quality metrics to find the best optimization. In automatic and human evaluation, we outperform different reranking baselines on an English corpus, improving 60% of all claims (worsening 16% only). Follow-up analyses reveal that, beyond copy editing, our approach often specifies claims with details, whereas it adds less evidence than humans do. Moreover, its capabilities generalize well to other domains, such as instructional texts.
Learning From Revisions: Quality Assessment of Claims in Argumentation at Scale
Jan 25, 2021
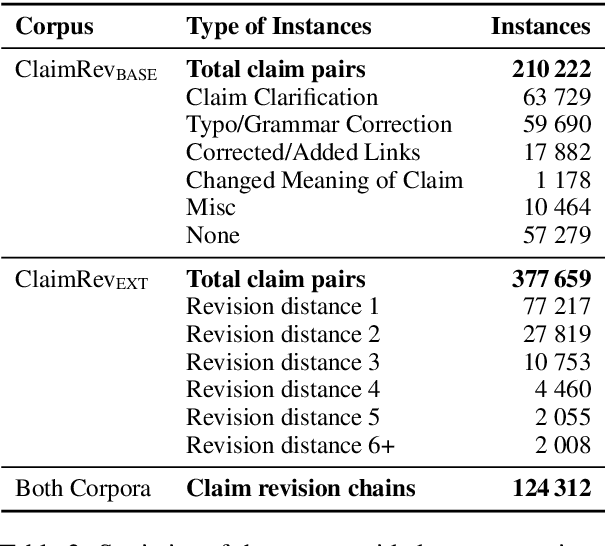

Assessing the quality of arguments and of the claims the arguments are composed of has become a key task in computational argumentation. However, even if different claims share the same stance on the same topic, their assessment depends on the prior perception and weighting of the different aspects of the topic being discussed. This renders it difficult to learn topic-independent quality indicators. In this paper, we study claim quality assessment irrespective of discussed aspects by comparing different revisions of the same claim. We compile a large-scale corpus with over 377k claim revision pairs of various types from kialo.com, covering diverse topics from politics, ethics, entertainment, and others. We then propose two tasks: (a) assessing which claim of a revision pair is better, and (b) ranking all versions of a claim by quality. Our first experiments with embedding-based logistic regression and transformer-based neural networks show promising results, suggesting that learned indicators generalize well across topics. In a detailed error analysis, we give insights into what quality dimensions of claims can be assessed reliably. We provide the data and scripts needed to reproduce all results.