 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgInstruct: Specialized Instruction Fine-Tuning for Computational Argumentation
May 28, 2025Training large language models (LLMs) to follow instructions has significantly enhanced their ability to tackle unseen tasks. However, despite their strong generalization capabilities, instruction-following LLMs encounter difficulties when dealing with tasks that require domain knowledge. This work introduces a specialized instruction fine-tuning for the domain of computational argumentation (CA). The goal is to enable an LLM to effectively tackle any unseen CA tasks while preserving its generalization capabilities. Reviewing existing CA research, we crafted natural language instructions for 105 CA tasks to this end. On this basis, we developed a CA-specific benchmark for LLMs that allows for a comprehensive evaluation of LLMs' capabilities in solving various CA tasks. We synthesized 52k CA-related instructions, adapting the self-instruct process to train a CA-specialized instruction-following LLM. Our experiments suggest that CA-specialized instruction fine-tuning significantly enhances the LLM on both seen and unseen CA tasks. At the same time, performance on the general NLP tasks of the SuperNI benchmark remains stable.
LLM-based Rewriting of Inappropriate Argumentation using Reinforcement Learning from Machine Feedback
Jun 05, 2024Ensuring that online discussions are civil and productive is a major challenge for social media platforms. Such platforms usually rely both on users and on automated detection tools to flag inappropriate arguments of other users, which moderators then review. However, this kind of post-hoc moderation is expensive and time-consuming, and moderators are often overwhelmed by the amount and severity of flagged content. Instead, a promising alternative is to prevent negative behavior during content creation. This paper studies how inappropriate language in arguments can be computationally mitigated. We propose a reinforcement learning-based rewriting approach that balances content preservation and appropriateness based on existing classifiers, prompting an instruction-finetuned large language model (LLM) as our initial policy. Unlike related style transfer tasks, rewriting inappropriate arguments allows deleting and adding content permanently. It is therefore tackled on document level rather than sentence level. We evaluate different weighting schemes for the reward function in both absolute and relative human assessment studies. Systematic experiments on non-parallel data provide evidence that our approach can mitigate the inappropriateness of arguments while largely preserving their content. It significantly outperforms competitive baselines, including few-shot learning, prompting, and humans.
Argument Quality Assessment in the Age of Instruction-Following Large Language Models
Mar 24, 2024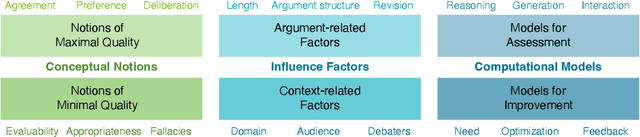

The computational treatment of arguments on controversial issues has been subject to extensive NLP research, due to its envisioned impact on opinion formation, decision making, writing education, and the like. A critical task in any such application is the assessment of an argument's quality - but it is also particularly challenging. In this position paper, we start from a brief survey of argument quality research, where we identify the diversity of quality notions and the subjectiveness of their perception as the main hurdles towards substantial progress on argument quality assessment. We argue that the capabilities of instruction-following large language models (LLMs) to leverage knowledge across contexts enable a much more reliable assessment. Rather than just fine-tuning LLMs towards leaderboard chasing on assessment tasks, they need to be instructed systematically with argumentation theories and scenarios as well as with ways to solve argument-related problems. We discuss the real-world opportunities and ethical issues emerging thereby.
Modeling Appropriate Language in Argumentation
May 24, 2023Online discussion moderators must make ad-hoc decisions about whether the contributions of discussion participants are appropriate or should be removed to maintain civility. Existing research on offensive language and the resulting tools cover only one aspect among many involved in such decisions. The question of what is considered appropriate in a controversial discussion has not yet been systematically addressed. In this paper, we operationalize appropriate language in argumentation for the first time. In particular, we model appropriateness through the absence of flaws, grounded in research on argument quality assessment, especially in aspects from rhetoric. From these, we derive a new taxonomy of 14 dimensions that determine inappropriate language in online discussions. Building on three argument quality corpora, we then create a corpus of 2191 arguments annotated for the 14 dimensions. Empirical analyses support that the taxonomy covers the concept of appropriateness comprehensively, showing several plausible correlations with argument quality dimensions. Moreover, results of baseline approaches to assessing appropriateness suggest that all dimensions can be modeled computationally on the corpus.