 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Co-Constructive Behavior of Large Language Models in Explanation Dialogues
Apr 25, 2025The ability to generate explanations that are understood by explainees is the quintessence of explainable artificial intelligence. Since understanding depends on the explainee's background and needs, recent research has focused on co-constructive explanation dialogues, where the explainer continuously monitors the explainee's understanding and adapts explanations dynamically. We investigate the ability of large language models (LLMs) to engage as explainers in co-constructive explanation dialogues. In particular, we present a user study in which explainees interact with LLMs, of which some have been instructed to explain a predefined topic co-constructively. We evaluate the explainees' understanding before and after the dialogue, as well as their perception of the LLMs' co-constructive behavior. Our results indicate that current LLMs show some co-constructive behaviors, such as asking verification questions, that foster the explainees' engagement and can improve understanding of a topic. However, their ability to effectively monitor the current understanding and scaffold the explanations accordingly remains limited.
Adaptive Prompting: Ad-hoc Prompt Composition for Social Bias Detection
Feb 10, 2025Recent advances on instruction fine-tuning have led to the development of various prompting techniques for large language models, such as explicit reasoning steps. However, the success of techniques depends on various parameters, such as the task, language model, and context provided. Finding an effective prompt is, therefore, often a trial-and-error process. Most existing approaches to automatic prompting aim to optimize individual techniques instead of compositions of techniques and their dependence on the input. To fill this gap, we propose an adaptive prompting approach that predicts the optimal prompt composition ad-hoc for a given input. We apply our approach to social bias detection, a highly context-dependent task that requires semantic understanding. We evaluate it with three large language models on three datasets, comparing compositions to individual techniques and other baselines. The results underline the importance of finding an effective prompt composition. Our approach robustly ensures high detection performance, and is best in several settings. Moreover, first experiments on other tasks support its generalizability.
Disentangling Dialect from Social Bias via Multitask Learning to Improve Fairness
Jun 14, 2024Dialects introduce syntactic and lexical variations in language that occur in regional or social groups. Most NLP methods are not sensitive to such variations. This may lead to unfair behavior of the methods, conveying negative bias towards dialect speakers. While previous work has studied dialect-related fairness for aspects like hate speech, other aspects of biased language, such as lewdness, remain fully unexplored. To fill this gap, we investigate performance disparities between dialects in the detection of five aspects of biased language and how to mitigate them. To alleviate bias, we present a multitask learning approach that models dialect language as an auxiliary task to incorporate syntactic and lexical variations. In our experiments with African-American English dialect, we provide empirical evidence that complementing common learning approaches with dialect modeling improves their fairness. Furthermore, the results suggest that multitask learning achieves state-of-the-art performance and helps to detect properties of biased language more reliably.
Claim Optimization in Computational Argumentation
Dec 17, 2022



An optimal delivery of arguments is key to persuasion in any debate, both for humans and for AI systems. This requires the use of clear and fluent claims relevant to the given debate. Prior work has studied the automatic assessment of argument quality extensively. Yet, no approach actually improves the quality so far. Our work is the first step towards filling this gap. We propose the task of claim optimization: to rewrite argumentative claims to optimize their delivery. As an initial approach, we first generate a candidate set of optimized claims using a sequence-to-sequence model, such as BART, while taking into account contextual information. Our key idea is then to rerank generated candidates with respect to different quality metrics to find the best optimization. In automatic and human evaluation, we outperform different reranking baselines on an English corpus, improving 60% of all claims (worsening 16% only). Follow-up analyses reveal that, beyond copy editing, our approach often specifies claims with details, whereas it adds less evidence than humans do. Moreover, its capabilities generalize well to other domains, such as instructional texts.
No Word Embedding Model Is Perfect: Evaluating the Representation Accuracy for Social Bias in the Media
Nov 07, 2022News articles both shape and reflect public opinion across the political spectrum. Analyzing them for social bias can thus provide valuable insights, such as prevailing stereotypes in society and the media, which are often adopted by NLP models trained on respective data. Recent work has relied on word embedding bias measures, such as WEAT. However, several representation issues of embeddings can harm the measures' accuracy, including low-resource settings and token frequency differences. In this work, we study what kind of embedding algorithm serves best to accurately measure types of social bias known to exist in US online news articles. To cover the whole spectrum of political bias in the US, we collect 500k articles and review psychology literature with respect to expected social bias. We then quantify social bias using WEAT along with embedding algorithms that account for the aforementioned issues. We compare how models trained with the algorithms on news articles represent the expected social bias. Our results suggest that the standard way to quantify bias does not align well with knowledge from psychology. While the proposed algorithms reduce the~gap, they still do not fully match the literature.
Key Point Analysis via Contrastive Learning and Extractive Argument Summarization
Sep 30, 2021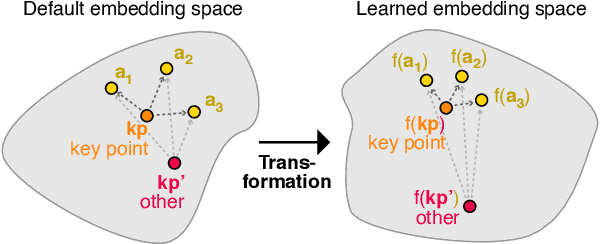

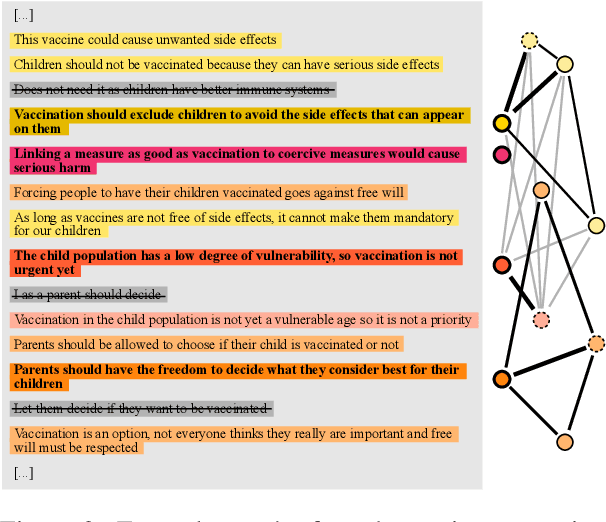

Key point analysis is the task of extracting a set of concise and high-level statements from a given collection of arguments, representing the gist of these arguments. This paper presents our proposed approach to the Key Point Analysis shared task, collocated with the 8th Workshop on Argument Mining. The approach integrates two complementary components. One component employs contrastive learning via a siamese neural network for matching arguments to key points; the other is a graph-based extractive summarization model for generating key points. In both automatic and manual evaluation, our approach was ranked best among all submissions to the shared task.
Argument from Old Man's View: Assessing Social Bias in Argumentation
Nov 24, 2020



Social bias in language - towards genders, ethnicities, ages, and other social groups - poses a problem with ethical impact for many NLP applications. Recent research has shown that machine learning models trained on respective data may not only adopt, but even amplify the bias. So far, however, little attention has been paid to bias in computational argumentation. In this paper, we study the existence of social biases in large English debate portals. In particular, we train word embedding models on portal-specific corpora and systematically evaluate their bias using WEAT, an existing metric to measure bias in word embeddings. In a word co-occurrence analysis, we then investigate causes of bias. The results suggest that all tested debate corpora contain unbalanced and biased data, mostly in favor of male people with European-American names. Our empirical insights contribute towards an understanding of bias in argumentative data sources.
Is It Worth the Attention? A Comparative Evaluation of Attention Layers for Argument Unit Segmentation
Jun 24, 2019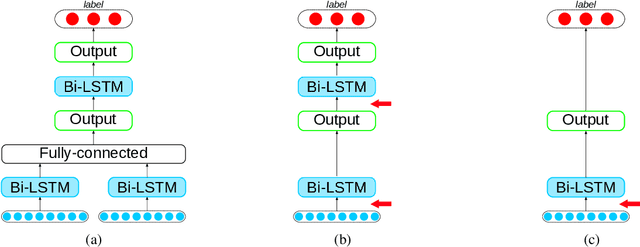
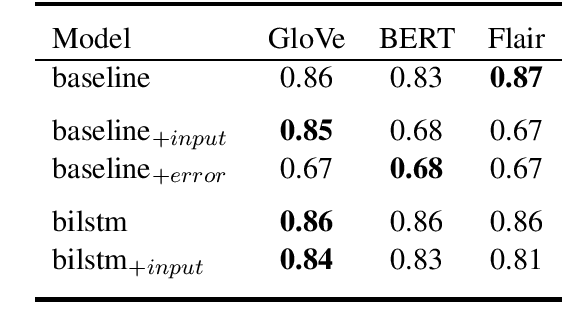
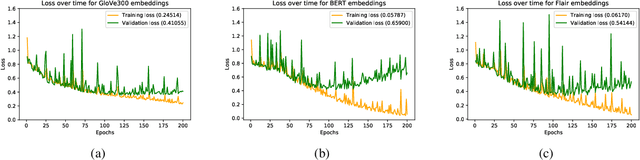
Attention mechanisms have seen some success for natural language processing downstream tasks in recent years and generated new State-of-the-Art results. A thorough evaluation of the attention mechanism for the task of Argumentation Mining is missing, though. With this paper, we report a comparative evaluation of attention layers in combination with a bidirectional long short-term memory network, which is the current state-of-the-art approach to the unit segmentation task. We also compare sentence-level contextualized word embeddings to pre-generated ones. Our findings suggest that for this task the additional attention layer does not improve upon a less complex approach. In most cases, the contextualized embeddings do also not show an improvement on the baseline score.