Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText comparison using word vector representations and dimensionality reduction
Paper and Code
Jul 02, 2016
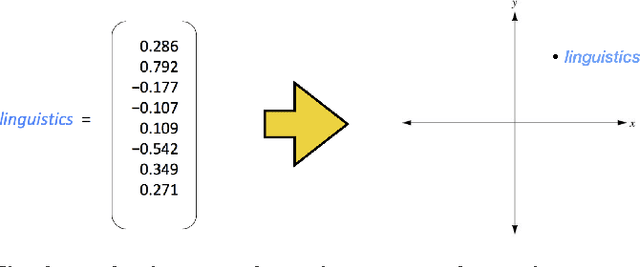


This paper describes a technique to compare large text sources using word vector representations (word2vec) and dimensionality reduction (t-SNE) and how it can be implemented using Python. The technique provides a bird's-eye view of text sources, e.g. text summaries and their source material, and enables users to explore text sources like a geographical map. Word vector representations capture many linguistic properties such as gender, tense, plurality and even semantic concepts like "capital city of". Using dimensionality reduction, a 2D map can be computed where semantically similar words are close to each other. The technique uses the word2vec model from the gensim Python library and t-SNE from scikit-learn.
View paper on