 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Stochastic Binarization of Deep Networks
Paper and Code
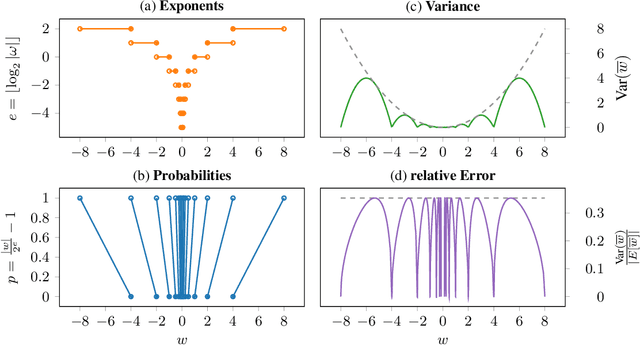
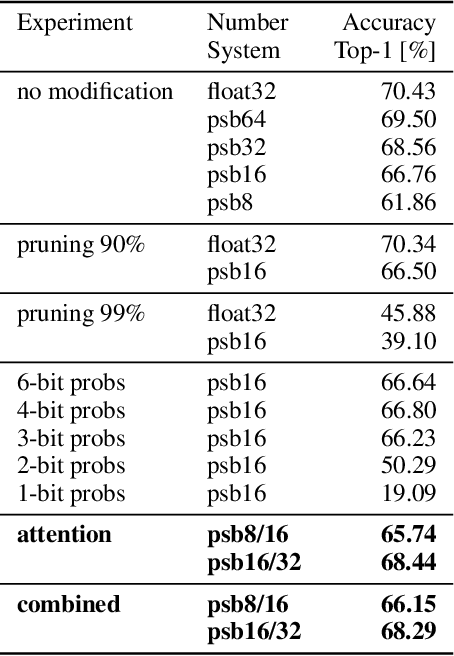
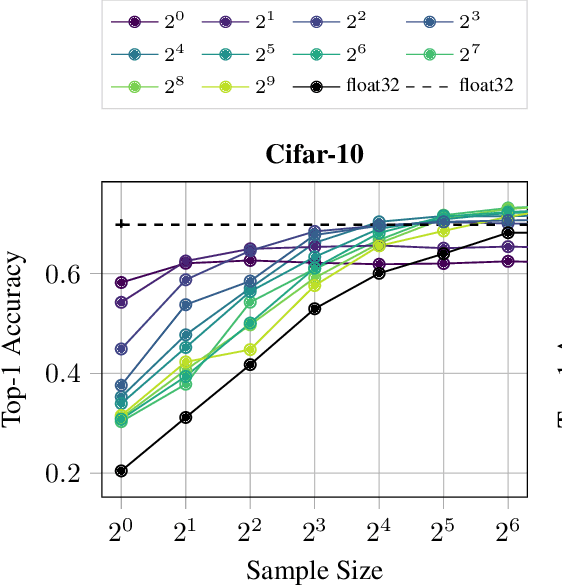

A plethora of recent research has focused on improving the memory footprint and inference speed of deep networks by reducing the complexity of (i) numerical representations (for example, by deterministic or stochastic quantization) and (ii) arithmetic operations (for example, by binarization of weights). We propose a stochastic binarization scheme for deep networks that allows for efficient inference on hardware by restricting itself to additions of small integers and fixed shifts. Unlike previous approaches, the underlying randomized approximation is progressive, thus permitting an adaptive control of the accuracy of each operation at run-time. In a low-precision setting, we match the accuracy of previous binarized approaches. Our representation is unbiased - it approaches continuous computation with increasing sample size. In a high-precision regime, the computational costs are competitive with previous quantization schemes. Progressive stochastic binarization also permits localized, dynamic accuracy control within a single network, thereby providing a new tool for adaptively focusing computational attention. We evaluate our method on networks of various architectures, already pretrained on ImageNet. With representational costs comparable to previous schemes, we obtain accuracies close to the original floating point implementation. This includes pruned networks, except the known special case of certain types of separated convolutions. By focusing computational attention using progressive sampling, we reduce inference costs on ImageNet further by a factor of up to 33% (before network pruning).