 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Sight Out of Mind, Out of Sight Out of Mind: Measuring Bias in Language Models Against Overlooked Marginalized Groups in Regional Contexts
Apr 17, 2025
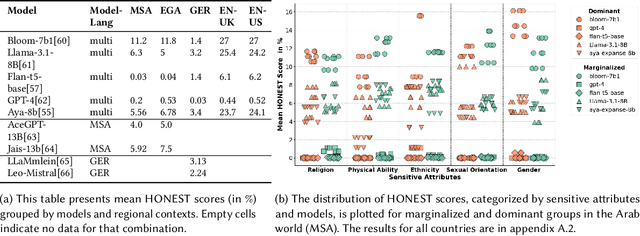


We know that language models (LMs) form biases and stereotypes of minorities, leading to unfair treatments of members of these groups, thanks to research mainly in the US and the broader English-speaking world. As the negative behavior of these models has severe consequences for society and individuals, industry and academia are actively developing methods to reduce the bias in LMs. However, there are many under-represented groups and languages that have been overlooked so far. This includes marginalized groups that are specific to individual countries and regions in the English speaking and Western world, but crucially also almost all marginalized groups in the rest of the world. The UN estimates, that between 600 million to 1.2 billion people worldwide are members of marginalized groups and in need for special protection. If we want to develop inclusive LMs that work for everyone, we have to broaden our understanding to include overlooked marginalized groups and low-resource languages and dialects. In this work, we contribute to this effort with the first study investigating offensive stereotyping bias in 23 LMs for 270 marginalized groups from Egypt, the remaining 21 Arab countries, Germany, the UK, and the US. Additionally, we investigate the impact of low-resource languages and dialects on the study of bias in LMs, demonstrating the limitations of current bias metrics, as we measure significantly higher bias when using the Egyptian Arabic dialect versus Modern Standard Arabic. Our results show, LMs indeed show higher bias against many marginalized groups in comparison to dominant groups. However, this is not the case for Arabic LMs, where the bias is high against both marginalized and dominant groups in relation to religion and ethnicity. Our results also show higher intersectional bias against Non-binary, LGBTQIA+ and Black women.
Thesis Distillation: Investigating The Impact of Bias in NLP Models on Hate Speech Detection
Aug 31, 2023This paper is a summary of the work in my PhD thesis. In which, I investigate the impact of bias in NLP models on the task of hate speech detection from three perspectives: explainability, offensive stereotyping bias, and fairness. I discuss the main takeaways from my thesis and how they can benefit the broader NLP community. Finally, I discuss important future research directions. The findings of my thesis suggest that bias in NLP models impacts the task of hate speech detection from all three perspectives. And that unless we start incorporating social sciences in studying bias in NLP models, we will not effectively overcome the current limitations of measuring and mitigating bias in NLP models.
Systematic Offensive Stereotyping (SOS) Bias in Language Models
Aug 21, 2023Research has shown that language models (LMs) are socially biased. However, toxicity and offensive stereotyping bias in LMs are understudied. In this paper, we investigate the systematic offensive stereotype (SOS) bias in LMs. We propose a method to measure it. Then, we validate the SOS bias and investigate the effectiveness of debias methods from the literature on removing it. Finally, we investigate the impact of the SOS bias in LMs on their performance and their fairness on the task of hate speech detection. Our results suggest that all the inspected LMs are SOS biased. The results suggest that the SOS bias in LMs is reflective of the hate experienced online by the inspected marginalized groups. The results indicate that removing the SOS bias in LMs, using a popular debias method from the literature, leads to worse SOS bias scores. Finally, Our results show no strong evidence that the SOS bias in LMs is impactful on their performance on hate speech detection. On the other hand, there is evidence that the SOS bias in LMs is impactful on their fairness.
On Bias and Fairness in NLP: How to have a fairer text classification?
May 22, 2023In this paper, we provide a holistic analysis of the different sources of bias, Upstream, Sample and Overampflication biases, in NLP models. We investigate how they impact the fairness of the task of text classification. We also investigate the impact of removing these biases using different debiasing techniques on the fairness of text classification. We found that overamplification bias is the most impactful bias on the fairness of text classification. And that removing overamplification bias by fine-tuning the LM models on a dataset with balanced representations of the different identity groups leads to fairer text classification models. Finally, we build on our findings and introduce practical guidelines on how to have a fairer text classification model.
On the Origins of Bias in NLP through the Lens of the Jim Code
May 16, 2023
In this paper, we trace the biases in current natural language processing (NLP) models back to their origins in racism, sexism, and homophobia over the last 500 years. We review literature from critical race theory, gender studies, data ethics, and digital humanities studies, and summarize the origins of bias in NLP models from these social science perspective. We show how the causes of the biases in the NLP pipeline are rooted in social issues. Finally, we argue that the only way to fix the bias and unfairness in NLP is by addressing the social problems that caused them in the first place and by incorporating social sciences and social scientists in efforts to mitigate bias in NLP models. We provide actionable recommendations for the NLP research community to do so.