 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Lyapunov Model Predictive Control
Feb 21, 2020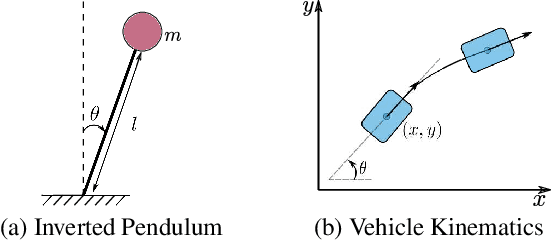

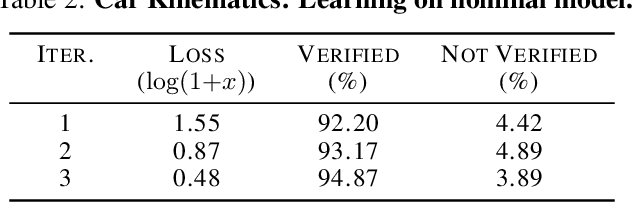
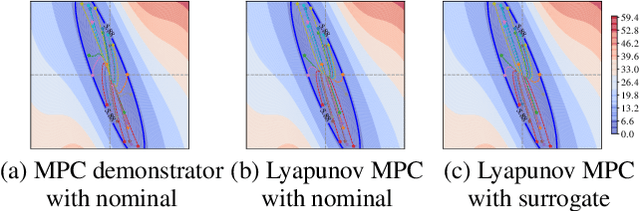
This paper presents Neural Lyapunov MPC, an algorithm to alternately train a Lyapunov neural network and a stabilising constrained Model Predictive Controller (MPC), given a neural network model of the system dynamics. This extends recent works on Lyapunov networks to be able to train solely from expert demonstrations of one-step transitions. The learned Lyapunov network is used as the value function for the MPC in order to guarantee stability and extend the stable region. Formal results are presented on the existence of a set of MPC parameters, such as discount factors, that guarantees stability with a horizon as short as one. Robustness margins are also discussed and existing performance bounds on value function MPC are extended to the case of imperfect models. The approach is tested on unstable non-linear continuous control tasks with hard constraints. Results demonstrate that, when a neural network trained on short sequences is used for predictions, a one-step horizon Neural Lyapunov MPC can successfully reproduce the expert behaviour and significantly outperform longer horizon MPCs.
Safe Interactive Model-Based Learning
Nov 18, 2019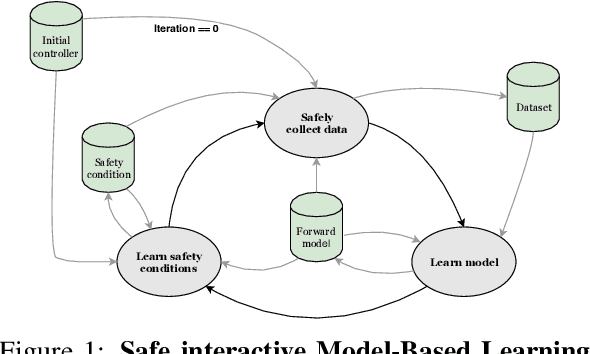
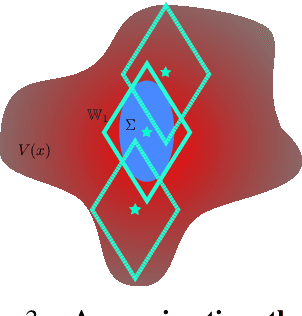
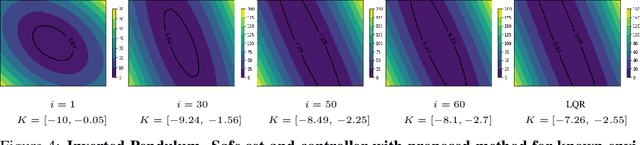
Control applications present hard operational constraints. A violation of these can result in unsafe behavior. This paper introduces Safe Interactive Model Based Learning (SiMBL), a framework to refine an existing controller and a system model while operating on the real environment. SiMBL is composed of the following trainable components: a Lyapunov function, which determines a safe set; a safe control policy; and a Bayesian RNN forward model. A min-max control framework, based on alternate minimisation and backpropagation through the forward model, is used for the offline computation of the controller and the safe set. Safety is formally verified a-posteriori with a probabilistic method that utilizes the Noise Contrastive Priors (NPC) idea to build a Bayesian RNN forward model with an additive state uncertainty estimate which is large outside the training data distribution. Iterative refinement of the model and the safe set is achieved thanks to a novel loss that conditions the uncertainty estimates of the new model to be close to the current one. The learned safe set and model can also be used for safe exploration, i.e., to collect data within the safe invariant set, for which a simple one-step MPC is proposed. The single components are tested on the simulation of an inverted pendulum with limited torque and stability region, showing that iteratively adding more data can improve the model, the controller and the size of the safe region.
Accelerating Neural ODEs with Spectral Elements
Jun 17, 2019
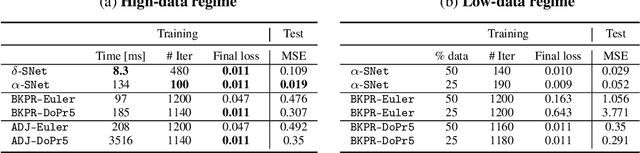
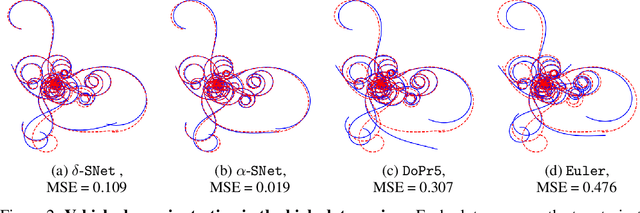

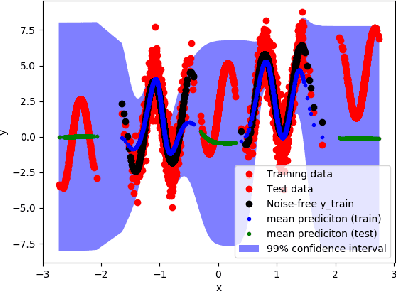
This paper proposes the use of spectral element methods \citep{canuto_spectral_1988} for fast and accurate training of Neural Ordinary Differential Equations (ODE-Nets; \citealp{Chen2018NeuralOD}). This is achieved by expressing their dynamics as truncated series of Legendre polynomials. The series coefficients, as well as the network weights, are computed by minimizing the weighted sum of the loss function and the violation of the ODE-Net dynamics. The problem is solved by coordinate descent that alternately minimizes, with respect to the coefficients and the weights, two unconstrained sub-problems using standard backpropagation and gradient methods. The resulting optimization scheme is fully time-parallel and results in a low memory footprint. Experimental comparison to standard methods, such as backpropagation through explicit solvers and the adjoint technique \citep{Chen2018NeuralOD}, on training surrogate models of small and medium-scale dynamical systems shows that it is at least one order of magnitude faster at reaching a comparable value of the loss function. The corresponding testing MSE is one order of magnitude smaller as well, suggesting generalization capabilities increase.
LSTM: A Search Space Odyssey
Oct 04, 2017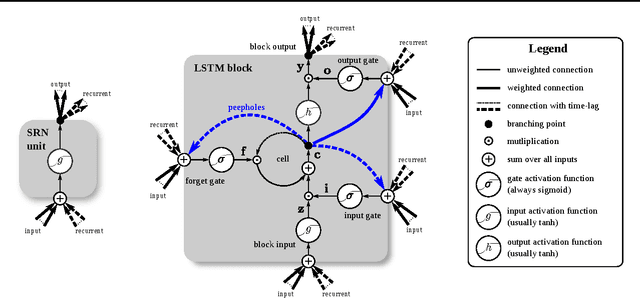
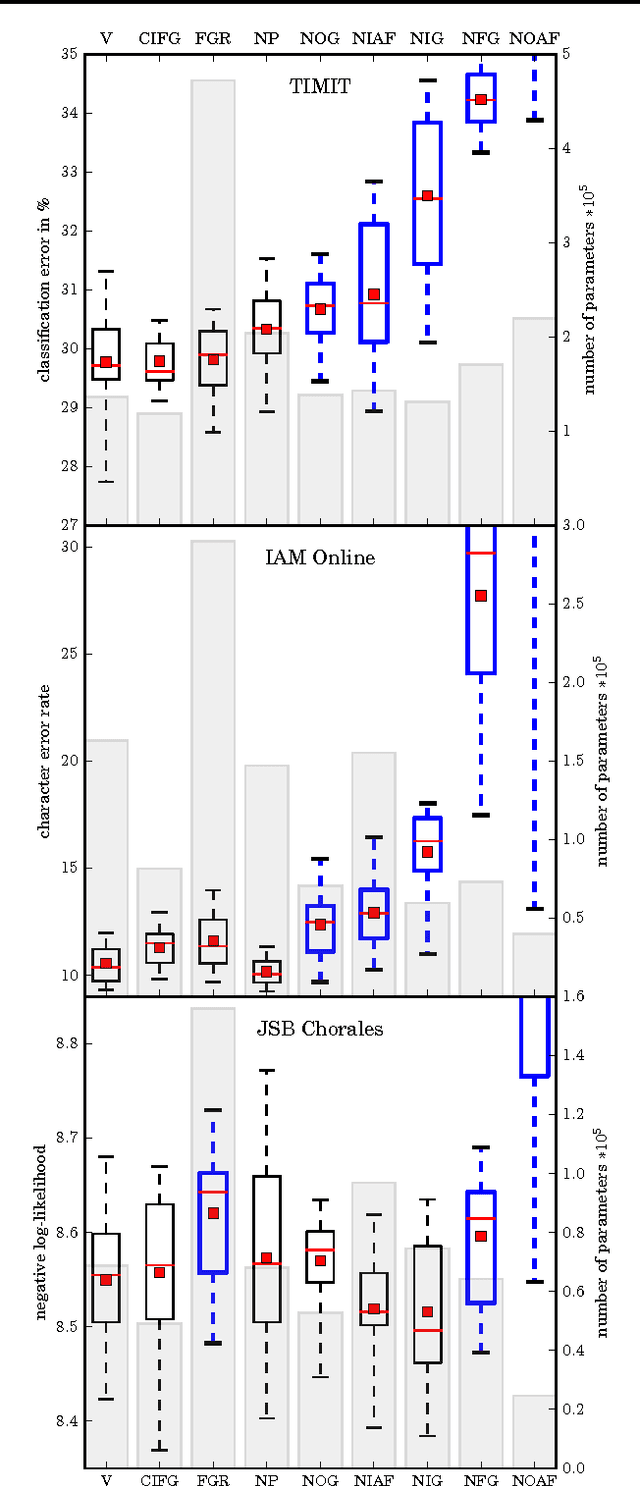
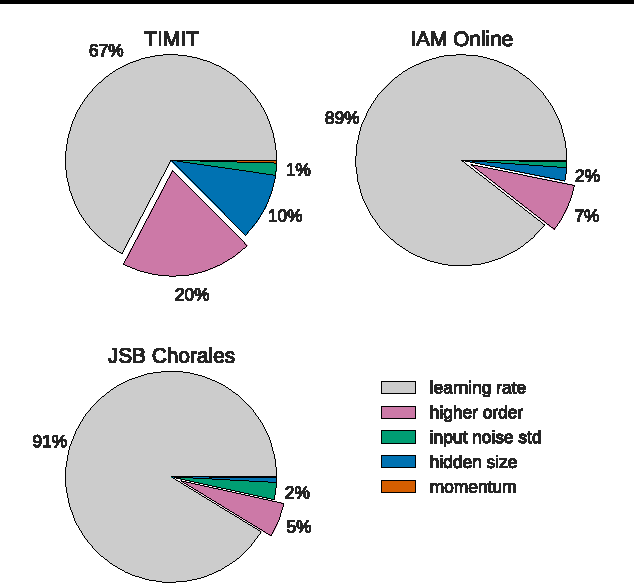
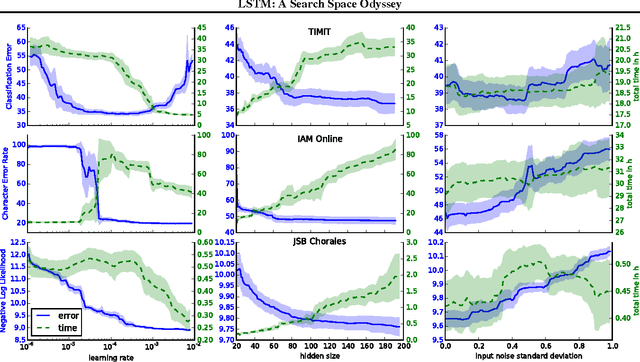
Several variants of the Long Short-Term Memory (LSTM) architecture for recurrent neural networks have been proposed since its inception in 1995. In recent years, these networks have become the state-of-the-art models for a variety of machine learning problems. This has led to a renewed interest in understanding the role and utility of various computational components of typical LSTM variants. In this paper, we present the first large-scale analysis of eight LSTM variants on three representative tasks: speech recognition, handwriting recognition, and polyphonic music modeling. The hyperparameters of all LSTM variants for each task were optimized separately using random search, and their importance was assessed using the powerful fANOVA framework. In total, we summarize the results of 5400 experimental runs ($\approx 15$ years of CPU time), which makes our study the largest of its kind on LSTM networks. Our results show that none of the variants can improve upon the standard LSTM architecture significantly, and demonstrate the forget gate and the output activation function to be its most critical components. We further observe that the studied hyperparameters are virtually independent and derive guidelines for their efficient adjustment.
* 12 pages, 6 figures
Recurrent Highway Networks
Jul 04, 2017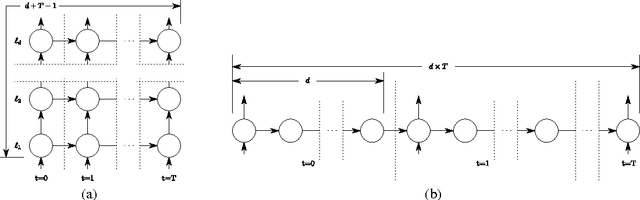
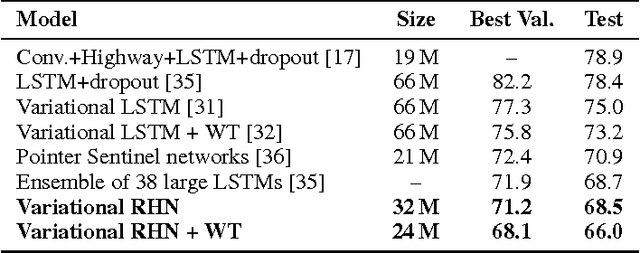
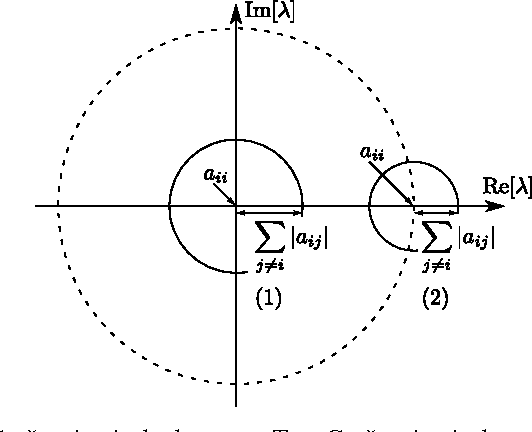
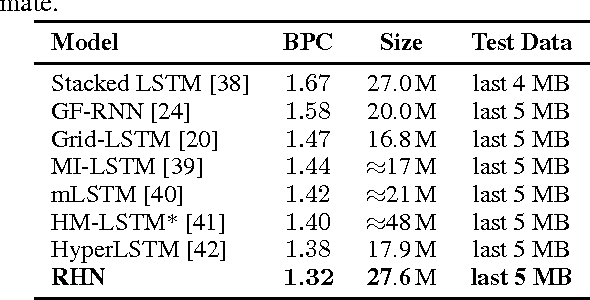
Many sequential processing tasks require complex nonlinear transition functions from one step to the next. However, recurrent neural networks with 'deep' transition functions remain difficult to train, even when using Long Short-Term Memory (LSTM) networks. We introduce a novel theoretical analysis of recurrent networks based on Gersgorin's circle theorem that illuminates several modeling and optimization issues and improves our understanding of the LSTM cell. Based on this analysis we propose Recurrent Highway Networks, which extend the LSTM architecture to allow step-to-step transition depths larger than one. Several language modeling experiments demonstrate that the proposed architecture results in powerful and efficient models. On the Penn Treebank corpus, solely increasing the transition depth from 1 to 10 improves word-level perplexity from 90.6 to 65.4 using the same number of parameters. On the larger Wikipedia datasets for character prediction (text8 and enwik8), RHNs outperform all previous results and achieve an entropy of 1.27 bits per character.
Lipreading with Long Short-Term Memory
Jan 29, 2016
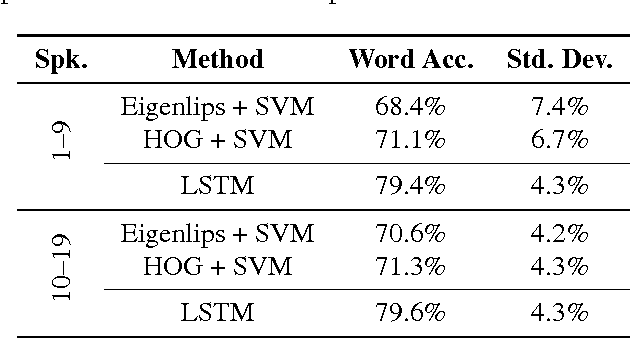
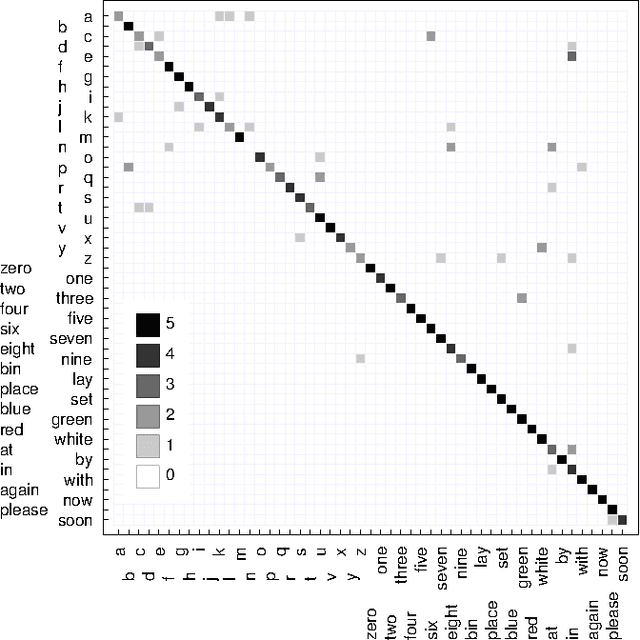
Lipreading, i.e. speech recognition from visual-only recordings of a speaker's face, can be achieved with a processing pipeline based solely on neural networks, yielding significantly better accuracy than conventional methods. Feed-forward and recurrent neural network layers (namely Long Short-Term Memory; LSTM) are stacked to form a single structure which is trained by back-propagating error gradients through all the layers. The performance of such a stacked network was experimentally evaluated and compared to a standard Support Vector Machine classifier using conventional computer vision features (Eigenlips and Histograms of Oriented Gradients). The evaluation was performed on data from 19 speakers of the publicly available GRID corpus. With 51 different words to classify, we report a best word accuracy on held-out evaluation speakers of 79.6% using the end-to-end neural network-based solution (11.6% improvement over the best feature-based solution evaluated).
A Clockwork RNN
Feb 14, 2014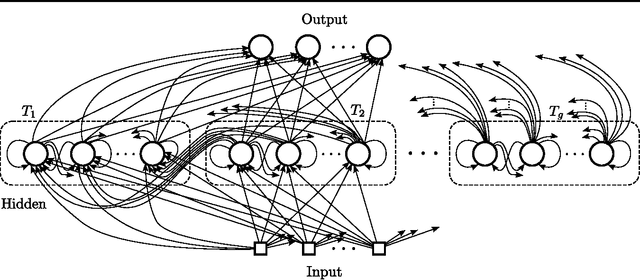
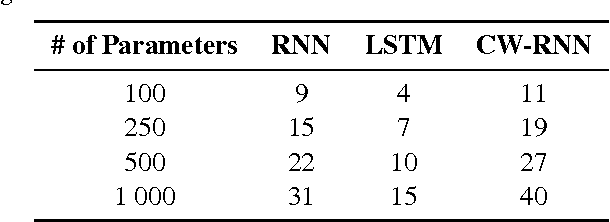
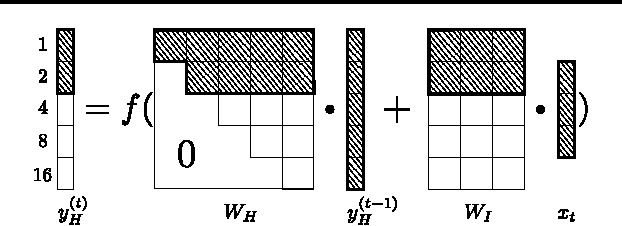
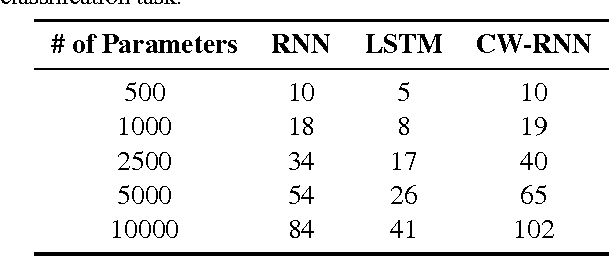
Sequence prediction and classification are ubiquitous and challenging problems in machine learning that can require identifying complex dependencies between temporally distant inputs. Recurrent Neural Networks (RNNs) have the ability, in theory, to cope with these temporal dependencies by virtue of the short-term memory implemented by their recurrent (feedback) connections. However, in practice they are difficult to train successfully when the long-term memory is required. This paper introduces a simple, yet powerful modification to the standard RNN architecture, the Clockwork RNN (CW-RNN), in which the hidden layer is partitioned into separate modules, each processing inputs at its own temporal granularity, making computations only at its prescribed clock rate. Rather than making the standard RNN models more complex, CW-RNN reduces the number of RNN parameters, improves the performance significantly in the tasks tested, and speeds up the network evaluation. The network is demonstrated in preliminary experiments involving two tasks: audio signal generation and TIMIT spoken word classification, where it outperforms both RNN and LSTM networks.
A Frequency-Domain Encoding for Neuroevolution
Dec 28, 2012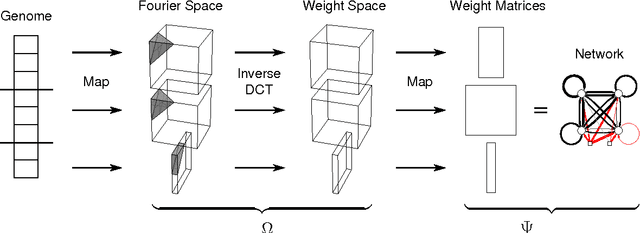
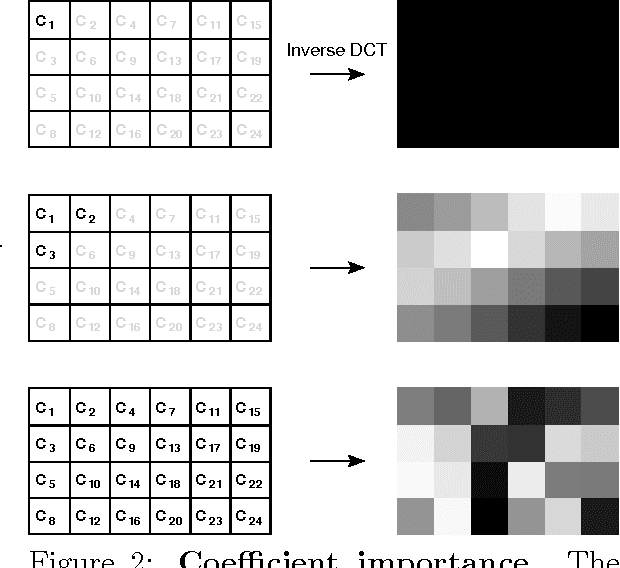
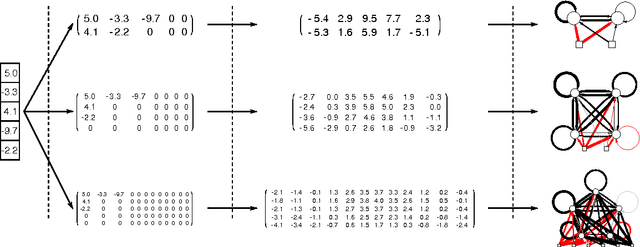
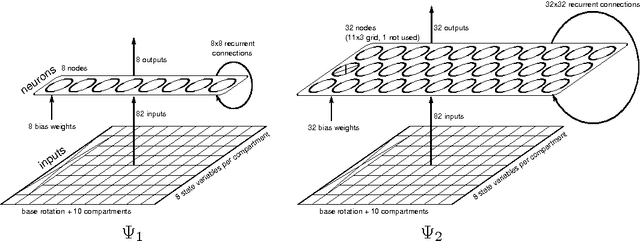
Neuroevolution has yet to scale up to complex reinforcement learning tasks that require large networks. Networks with many inputs (e.g. raw video) imply a very high dimensional search space if encoded directly. Indirect methods use a more compact genotype representation that is transformed into networks of potentially arbitrary size. In this paper, we present an indirect method where networks are encoded by a set of Fourier coefficients which are transformed into network weight matrices via an inverse Fourier-type transform. Because there often exist network solutions whose weight matrices contain regularity (i.e. adjacent weights are correlated), the number of coefficients required to represent these networks in the frequency domain is much smaller than the number of weights (in the same way that natural images can be compressed by ignore high-frequency components). This "compressed" encoding is compared to the direct approach where search is conducted in the weight space on the high-dimensional octopus arm task. The results show that representing networks in the frequency domain can reduce the search-space dimensionality by as much as two orders of magnitude, both accelerating convergence and yielding more general solutions.