 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoTorch: Scalable Evolutionary Computation in Python
Feb 27, 2023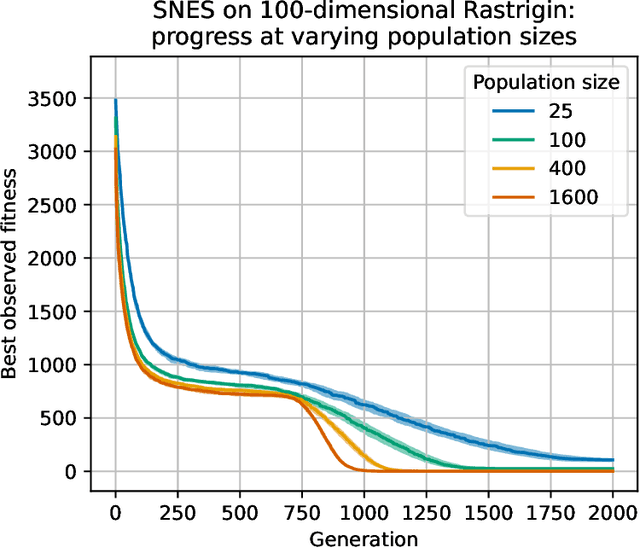
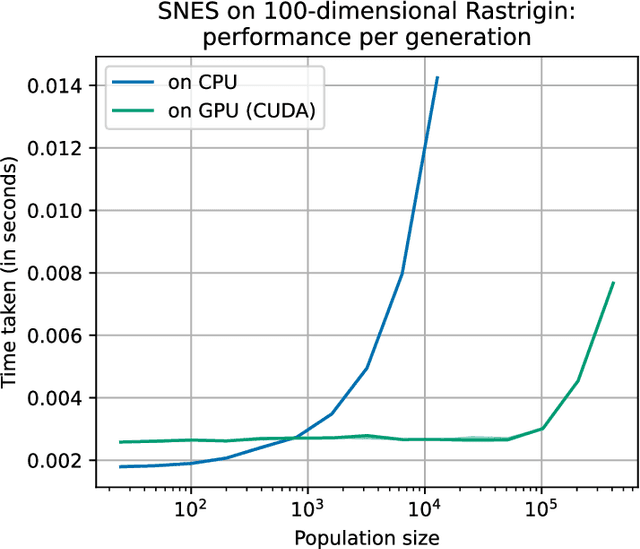
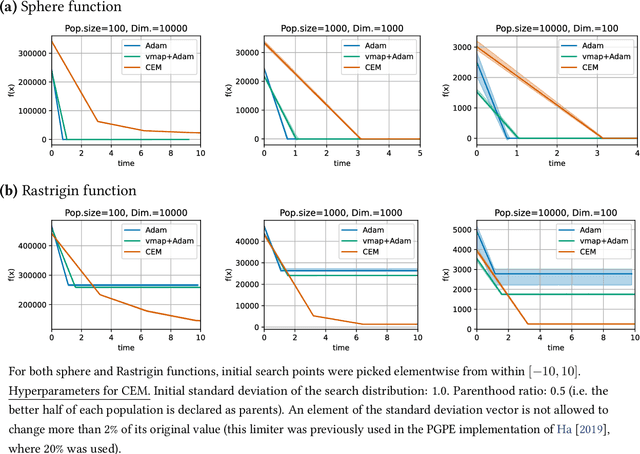
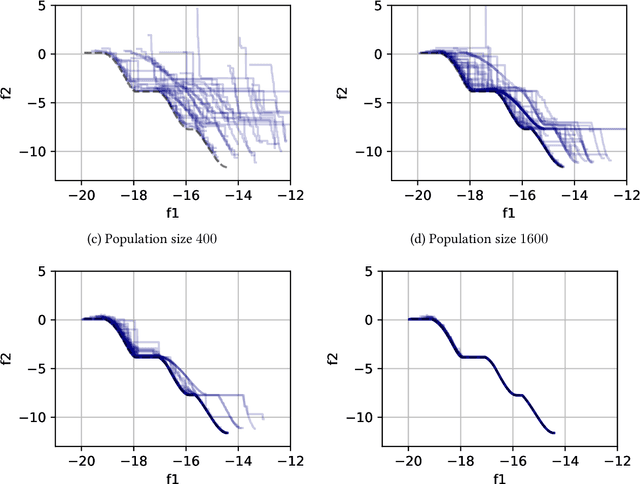
Evolutionary computation is an important component within various fields such as artificial intelligence research, reinforcement learning, robotics, industrial automation and/or optimization, engineering design, etc. Considering the increasing computational demands and the dimensionalities of modern optimization problems, the requirement for scalable, re-usable, and practical evolutionary algorithm implementations has been growing. To address this requirement, we present EvoTorch: an evolutionary computation library designed to work with high-dimensional optimization problems, with GPU support and with high parallelization capabilities. EvoTorch is based on and seamlessly works with the PyTorch library, and therefore, allows the users to define their optimization problems using a well-known API.
ClipUp: A Simple and Powerful Optimizer for Distribution-based Policy Evolution
Aug 05, 2020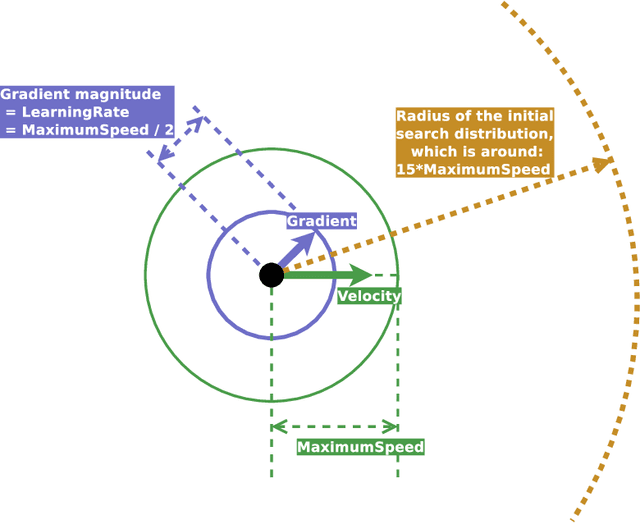


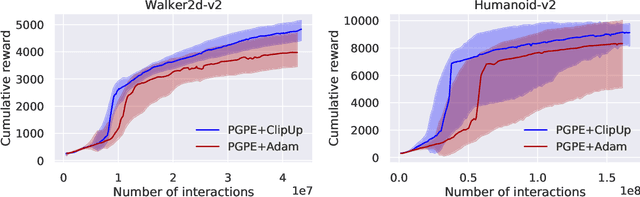
Distribution-based search algorithms are an effective approach for evolutionary reinforcement learning of neural network controllers. In these algorithms, gradients of the total reward with respect to the policy parameters are estimated using a population of solutions drawn from a search distribution, and then used for policy optimization with stochastic gradient ascent. A common choice in the community is to use the Adam optimization algorithm for obtaining an adaptive behavior during gradient ascent, due to its success in a variety of supervised learning settings. As an alternative to Adam, we propose to enhance classical momentum-based gradient ascent with two simple techniques: gradient normalization and update clipping. We argue that the resulting optimizer called ClipUp (short for "clipped updates") is a better choice for distribution-based policy evolution because its working principles are simple and easy to understand and its hyperparameters can be tuned more intuitively in practice. Moreover, it removes the need to re-tune hyperparameters if the reward scale changes. Experiments show that ClipUp is competitive with Adam despite its simplicity and is effective on challenging continuous control benchmarks, including the Humanoid control task based on the Bullet physics simulator.
Safe Interactive Model-Based Learning
Nov 18, 2019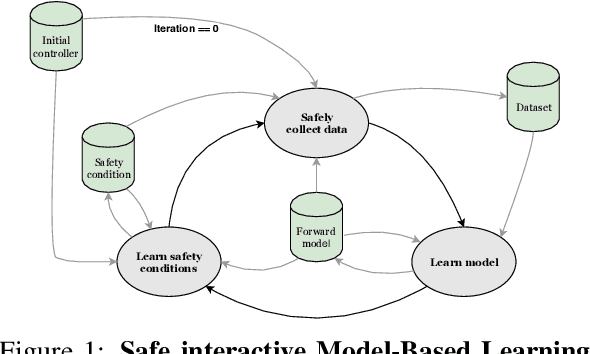
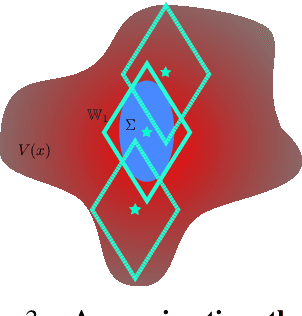
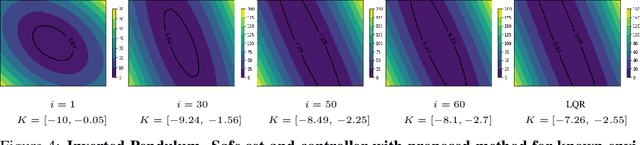
Control applications present hard operational constraints. A violation of these can result in unsafe behavior. This paper introduces Safe Interactive Model Based Learning (SiMBL), a framework to refine an existing controller and a system model while operating on the real environment. SiMBL is composed of the following trainable components: a Lyapunov function, which determines a safe set; a safe control policy; and a Bayesian RNN forward model. A min-max control framework, based on alternate minimisation and backpropagation through the forward model, is used for the offline computation of the controller and the safe set. Safety is formally verified a-posteriori with a probabilistic method that utilizes the Noise Contrastive Priors (NPC) idea to build a Bayesian RNN forward model with an additive state uncertainty estimate which is large outside the training data distribution. Iterative refinement of the model and the safe set is achieved thanks to a novel loss that conditions the uncertainty estimates of the new model to be close to the current one. The learned safe set and model can also be used for safe exploration, i.e., to collect data within the safe invariant set, for which a simple one-step MPC is proposed. The single components are tested on the simulation of an inverted pendulum with limited torque and stability region, showing that iteratively adding more data can improve the model, the controller and the size of the safe region.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
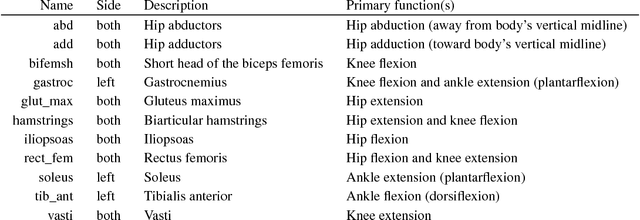
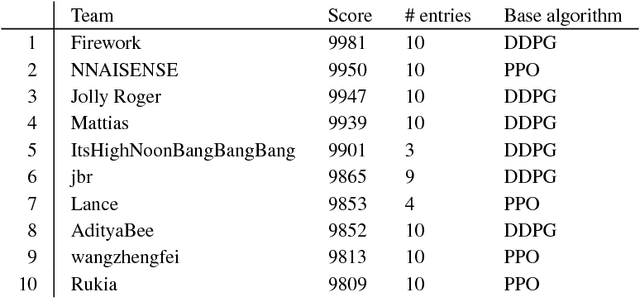

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.