 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Flow Networks
Aug 14, 2023



This paper introduces Bayesian Flow Networks (BFNs), a new class of generative model in which the parameters of a set of independent distributions are modified with Bayesian inference in the light of noisy data samples, then passed as input to a neural network that outputs a second, interdependent distribution. Starting from a simple prior and iteratively updating the two distributions yields a generative procedure similar to the reverse process of diffusion models; however it is conceptually simpler in that no forward process is required. Discrete and continuous-time loss functions are derived for continuous, discretised and discrete data, along with sample generation procedures. Notably, the network inputs for discrete data lie on the probability simplex, and are therefore natively differentiable, paving the way for gradient-based sample guidance and few-step generation in discrete domains such as language modelling. The loss function directly optimises data compression and places no restrictions on the network architecture. In our experiments BFNs achieve competitive log-likelihoods for image modelling on dynamically binarized MNIST and CIFAR-10, and outperform all known discrete diffusion models on the text8 character-level language modelling task.
Automatic design of novel potential 3CL$^{\text{pro}}$ and PL$^{\text{pro}}$ inhibitors
Jan 29, 2021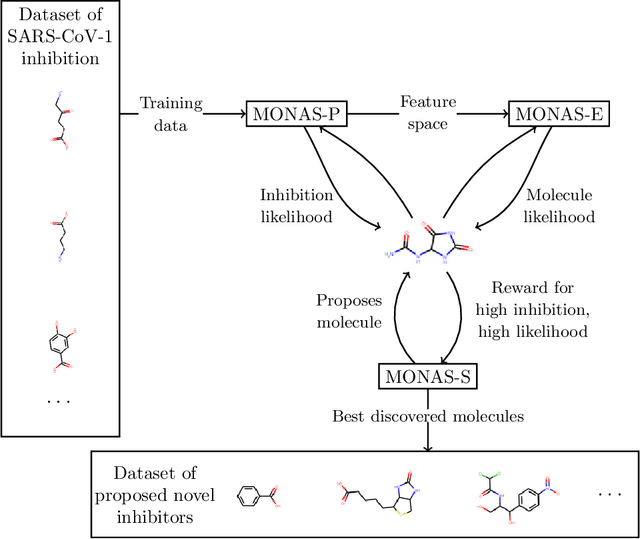
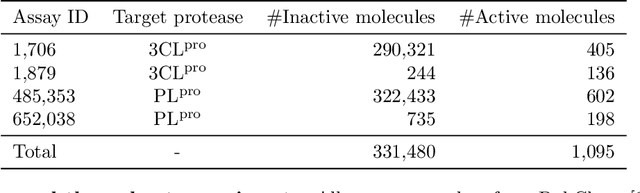
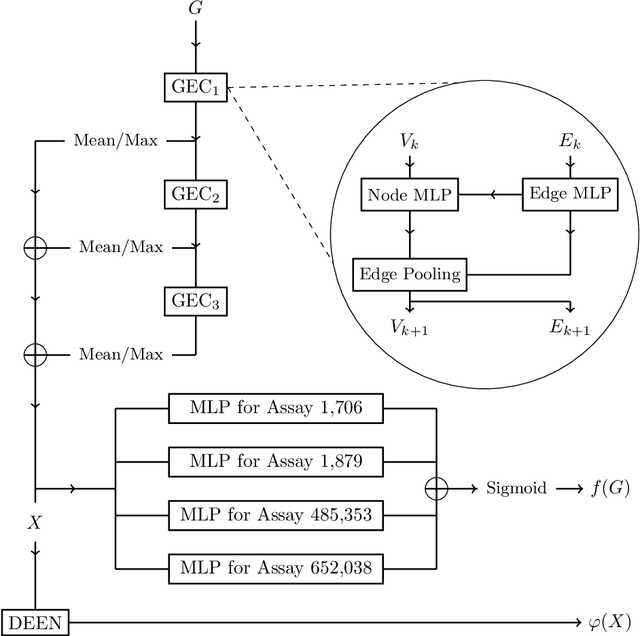
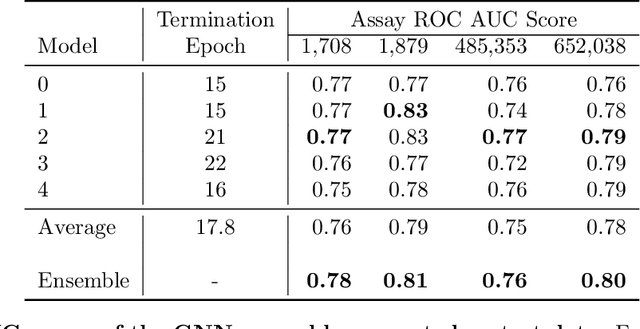
With the goal of designing novel inhibitors for SARS-CoV-1 and SARS-CoV-2, we propose the general molecule optimization framework, Molecular Neural Assay Search (MONAS), consisting of three components: a property predictor which identifies molecules with specific desirable properties, an energy model which approximates the statistical similarity of a given molecule to known training molecules, and a molecule search method. In this work, these components are instantiated with graph neural networks (GNNs), Deep Energy Estimator Networks (DEEN) and Monte Carlo tree search (MCTS), respectively. This implementation is used to identify 120K molecules (out of 40-million explored) which the GNN determined to be likely SARS-CoV-1 inhibitors, and, at the same time, are statistically close to the dataset used to train the GNN.
Safe Interactive Model-Based Learning
Nov 18, 2019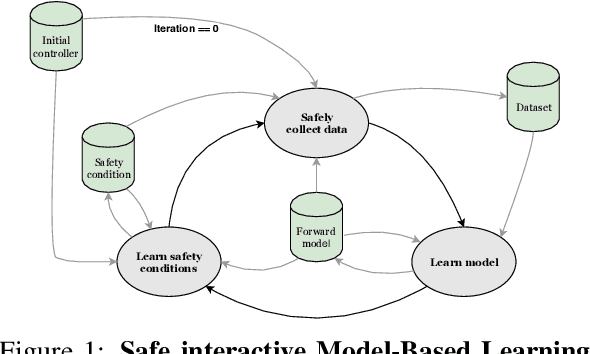
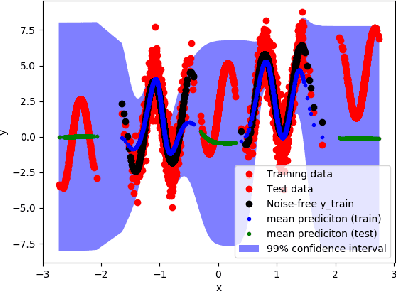
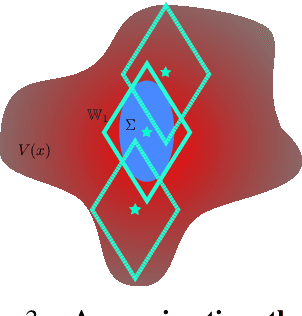
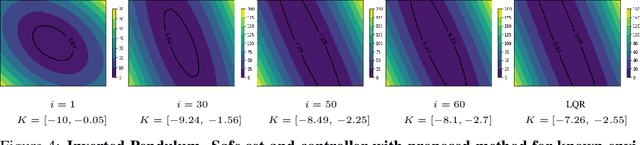
Control applications present hard operational constraints. A violation of these can result in unsafe behavior. This paper introduces Safe Interactive Model Based Learning (SiMBL), a framework to refine an existing controller and a system model while operating on the real environment. SiMBL is composed of the following trainable components: a Lyapunov function, which determines a safe set; a safe control policy; and a Bayesian RNN forward model. A min-max control framework, based on alternate minimisation and backpropagation through the forward model, is used for the offline computation of the controller and the safe set. Safety is formally verified a-posteriori with a probabilistic method that utilizes the Noise Contrastive Priors (NPC) idea to build a Bayesian RNN forward model with an additive state uncertainty estimate which is large outside the training data distribution. Iterative refinement of the model and the safe set is achieved thanks to a novel loss that conditions the uncertainty estimates of the new model to be close to the current one. The learned safe set and model can also be used for safe exploration, i.e., to collect data within the safe invariant set, for which a simple one-step MPC is proposed. The single components are tested on the simulation of an inverted pendulum with limited torque and stability region, showing that iteratively adding more data can improve the model, the controller and the size of the safe region.
NAIS-Net: Stable Deep Networks from Non-Autonomous Differential Equations
Nov 03, 2018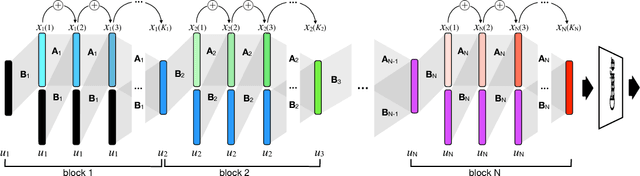

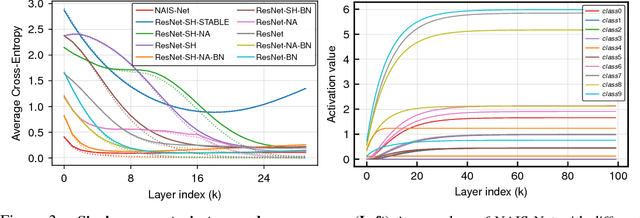
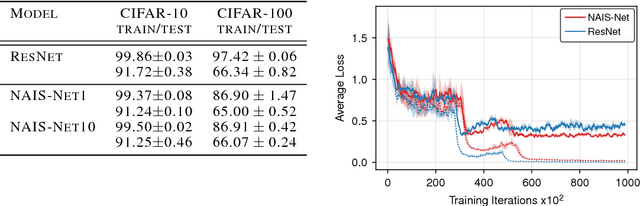
This paper introduces Non-Autonomous Input-Output Stable Network (NAIS-Net), a very deep architecture where each stacked processing block is derived from a time-invariant non-autonomous dynamical system. Non-autonomy is implemented by skip connections from the block input to each of the unrolled processing stages and allows stability to be enforced so that blocks can be unrolled adaptively to a pattern-dependent processing depth. NAIS-Net induces non-trivial, Lipschitz input-output maps, even for an infinite unroll length. We prove that the network is globally asymptotically stable so that for every initial condition there is exactly one input-dependent equilibrium assuming tanh units, and multiple stable equilibria for ReL units. An efficient implementation that enforces the stability under derived conditions for both fully-connected and convolutional layers is also presented. Experimental results show how NAIS-Net exhibits stability in practice, yielding a significant reduction in generalization gap compared to ResNets.
Model-Based Active Exploration
Oct 29, 2018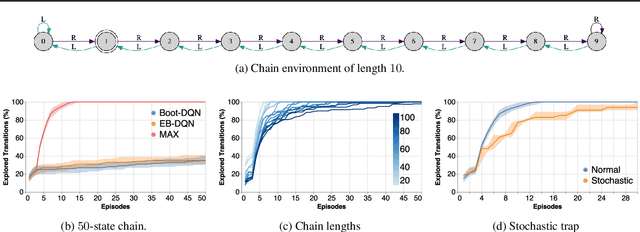
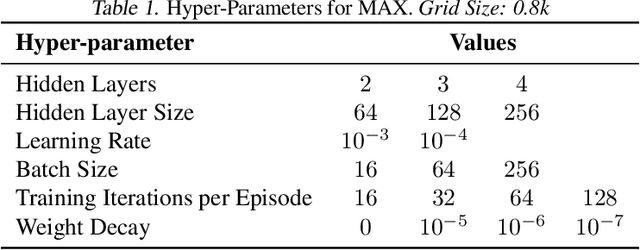

Efficient exploration is an unsolved problem in Reinforcement Learning. We introduce Model-Based Active eXploration (MAX), an algorithm that actively explores the environment. It minimizes data required to comprehensively model the environment by planning to observe novel events, instead of merely reacting to novelty encountered by chance. Non-stationarity induced by traditional exploration bonus techniques is avoided by constructing fresh exploration policies only at time of action. In semi-random toy environments where directed exploration is critical to make progress, our algorithm is at least an order of magnitude more efficient than strong baselines.
Understanding Locally Competitive Networks
Apr 09, 2015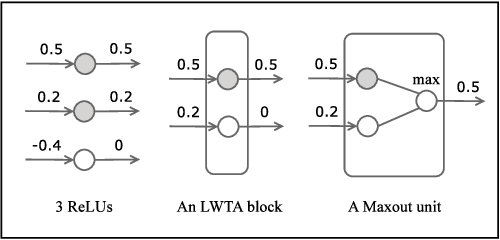
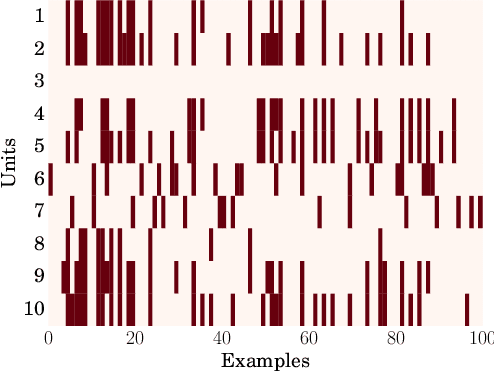


Recently proposed neural network activation functions such as rectified linear, maxout, and local winner-take-all have allowed for faster and more effective training of deep neural architectures on large and complex datasets. The common trait among these functions is that they implement local competition between small groups of computational units within a layer, so that only part of the network is activated for any given input pattern. In this paper, we attempt to visualize and understand this self-modularization, and suggest a unified explanation for the beneficial properties of such networks. We also show how our insights can be directly useful for efficiently performing retrieval over large datasets using neural networks.
Kernel-based Information Criterion
Dec 15, 2014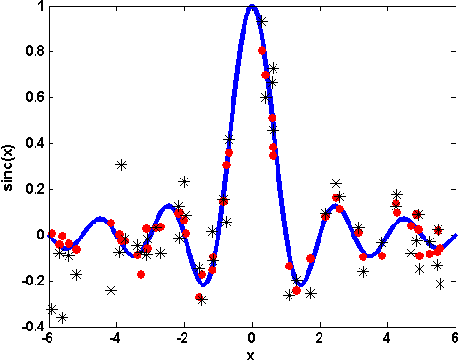
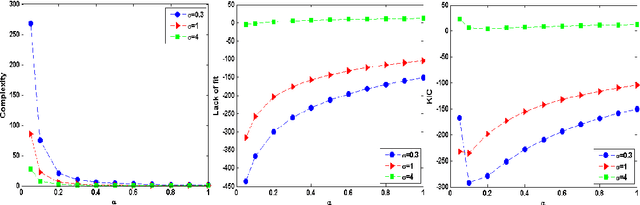
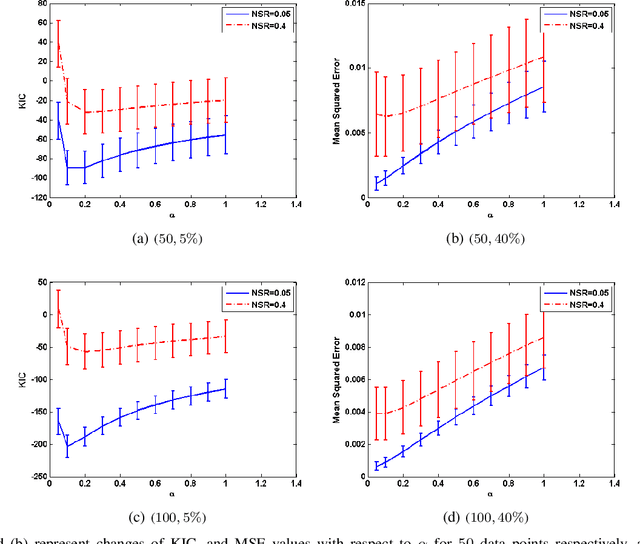
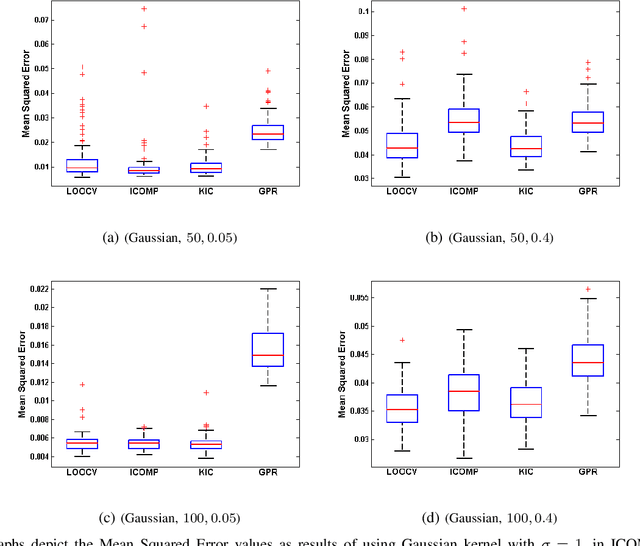
This paper introduces Kernel-based Information Criterion (KIC) for model selection in regression analysis. The novel kernel-based complexity measure in KIC efficiently computes the interdependency between parameters of the model using a variable-wise variance and yields selection of better, more robust regressors. Experimental results show superior performance on both simulated and real data sets compared to Leave-One-Out Cross-Validation (LOOCV), kernel-based Information Complexity (ICOMP), and maximum log of marginal likelihood in Gaussian Process Regression (GPR).
Deep Networks with Internal Selective Attention through Feedback Connections
Jul 28, 2014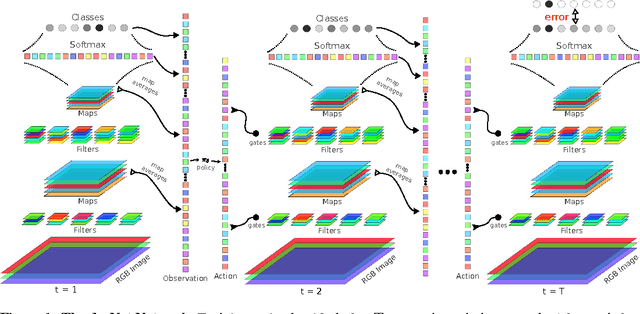
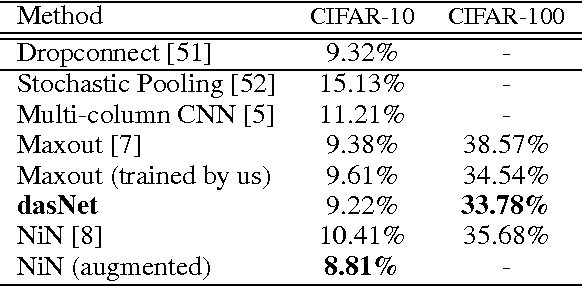

Traditional convolutional neural networks (CNN) are stationary and feedforward. They neither change their parameters during evaluation nor use feedback from higher to lower layers. Real brains, however, do. So does our Deep Attention Selective Network (dasNet) architecture. DasNets feedback structure can dynamically alter its convolutional filter sensitivities during classification. It harnesses the power of sequential processing to improve classification performance, by allowing the network to iteratively focus its internal attention on some of its convolutional filters. Feedback is trained through direct policy search in a huge million-dimensional parameter space, through scalable natural evolution strategies (SNES). On the CIFAR-10 and CIFAR-100 datasets, dasNet outperforms the previous state-of-the-art model.
A Clockwork RNN
Feb 14, 2014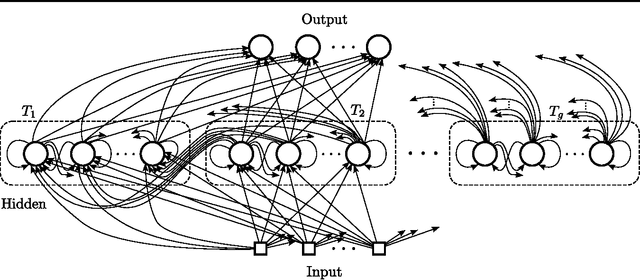
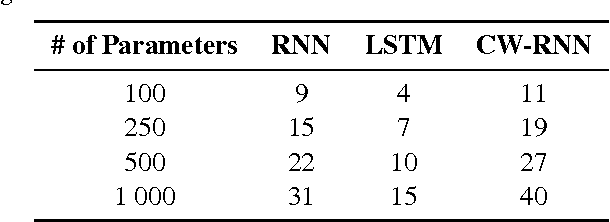
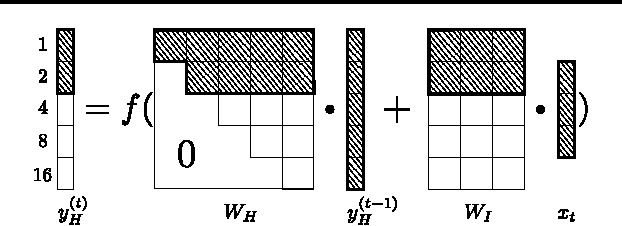
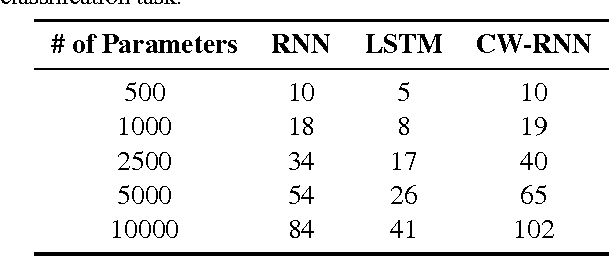
Sequence prediction and classification are ubiquitous and challenging problems in machine learning that can require identifying complex dependencies between temporally distant inputs. Recurrent Neural Networks (RNNs) have the ability, in theory, to cope with these temporal dependencies by virtue of the short-term memory implemented by their recurrent (feedback) connections. However, in practice they are difficult to train successfully when the long-term memory is required. This paper introduces a simple, yet powerful modification to the standard RNN architecture, the Clockwork RNN (CW-RNN), in which the hidden layer is partitioned into separate modules, each processing inputs at its own temporal granularity, making computations only at its prescribed clock rate. Rather than making the standard RNN models more complex, CW-RNN reduces the number of RNN parameters, improves the performance significantly in the tasks tested, and speeds up the network evaluation. The network is demonstrated in preliminary experiments involving two tasks: audio signal generation and TIMIT spoken word classification, where it outperforms both RNN and LSTM networks.
A Frequency-Domain Encoding for Neuroevolution
Dec 28, 2012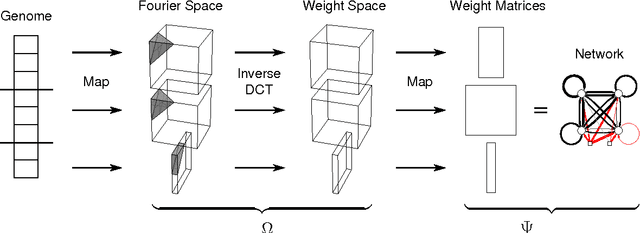
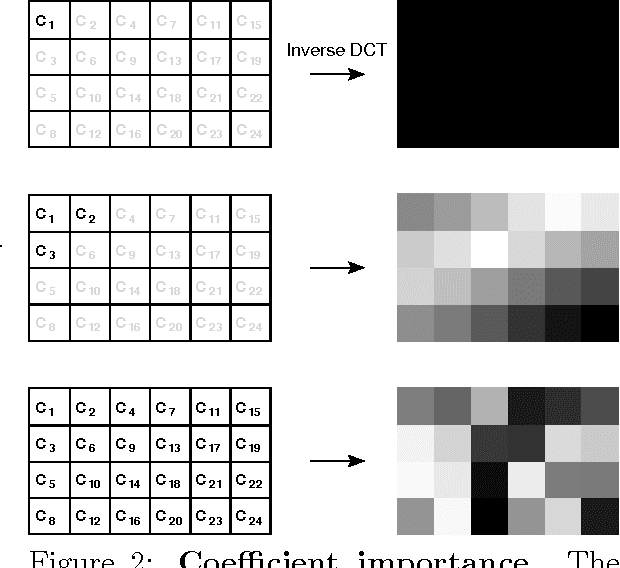
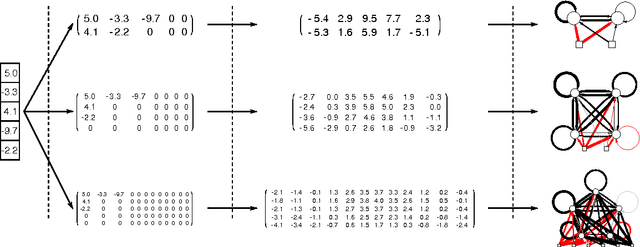
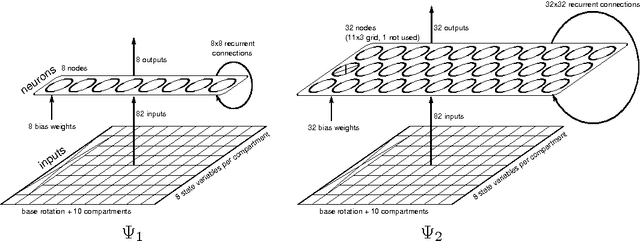
Neuroevolution has yet to scale up to complex reinforcement learning tasks that require large networks. Networks with many inputs (e.g. raw video) imply a very high dimensional search space if encoded directly. Indirect methods use a more compact genotype representation that is transformed into networks of potentially arbitrary size. In this paper, we present an indirect method where networks are encoded by a set of Fourier coefficients which are transformed into network weight matrices via an inverse Fourier-type transform. Because there often exist network solutions whose weight matrices contain regularity (i.e. adjacent weights are correlated), the number of coefficients required to represent these networks in the frequency domain is much smaller than the number of weights (in the same way that natural images can be compressed by ignore high-frequency components). This "compressed" encoding is compared to the direct approach where search is conducted in the weight space on the high-dimensional octopus arm task. The results show that representing networks in the frequency domain can reduce the search-space dimensionality by as much as two orders of magnitude, both accelerating convergence and yielding more general solutions.