 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparator-Transducer-Segmenter: Streaming Recognition and Segmentation of Multi-party Speech
May 10, 2022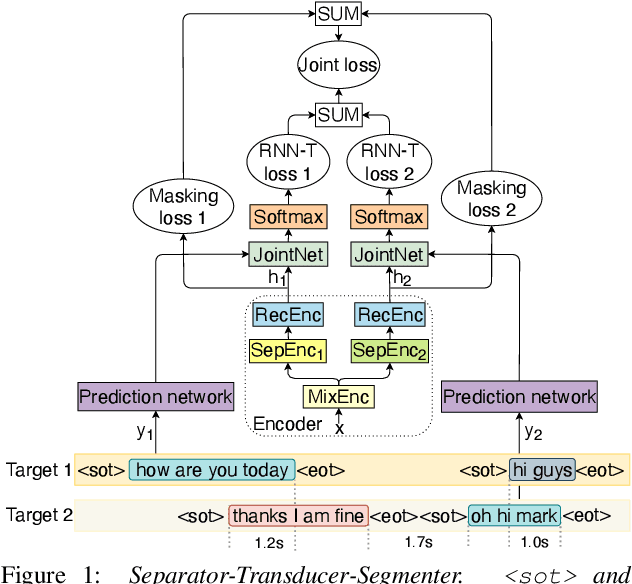


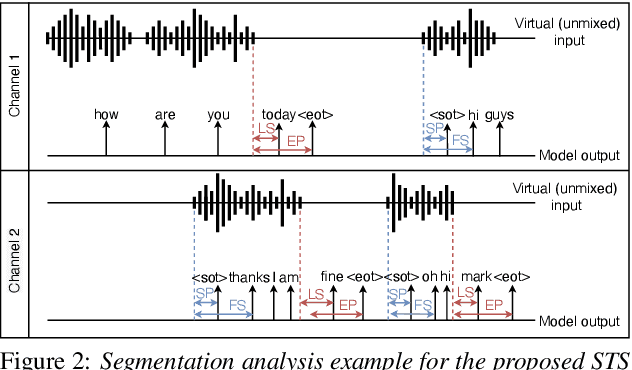
Streaming recognition and segmentation of multi-party conversations with overlapping speech is crucial for the next generation of voice assistant applications. In this work we address its challenges discovered in the previous work on multi-turn recurrent neural network transducer (MT-RNN-T) with a novel approach, separator-transducer-segmenter (STS), that enables tighter integration of speech separation, recognition and segmentation in a single model. First, we propose a new segmentation modeling strategy through start-of-turn and end-of-turn tokens that improves segmentation without recognition accuracy degradation. Second, we further improve both speech recognition and segmentation accuracy through an emission regularization method, FastEmit, and multi-task training with speech activity information as an additional training signal. Third, we experiment with end-of-turn emission latency penalty to improve end-point detection for each speaker turn. Finally, we establish a novel framework for segmentation analysis of multi-party conversations through emission latency metrics. With our best model, we report 4.6% abs. turn counting accuracy improvement and 17% rel. word error rate (WER) improvement on LibriCSS dataset compared to the previously published work.
No Representation without Transformation
Dec 09, 2019
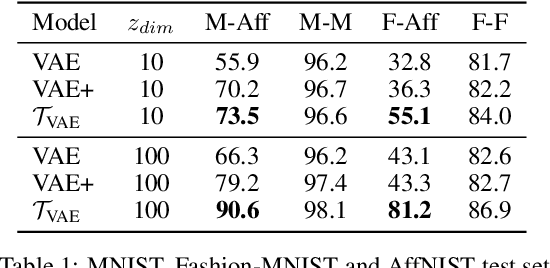
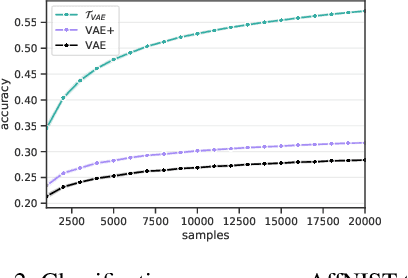

We propose to extend Latent Variable Models with a simple idea: learn to encode not only samples but also transformations of such samples. This means that the latent space is not only populated by embeddings but also by higher order objects that map between these embeddings. We show how a hierarchical graphical model can be utilized to enforce desirable algebraic properties of such latent mappings. These mappings in turn structure the latent space and hence can have a core impact on downstream tasks that are solved in the latent space. We demonstrate this impact on a set of experiments and also show that the representation of these latent mappings reflects interpretable properties.
Recurrent Neural Processes
Jun 13, 2019
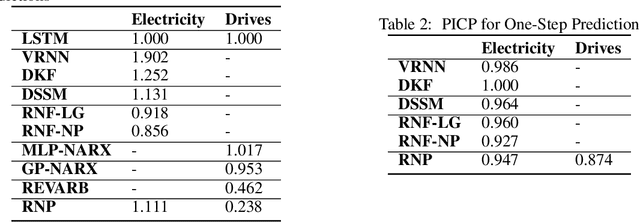
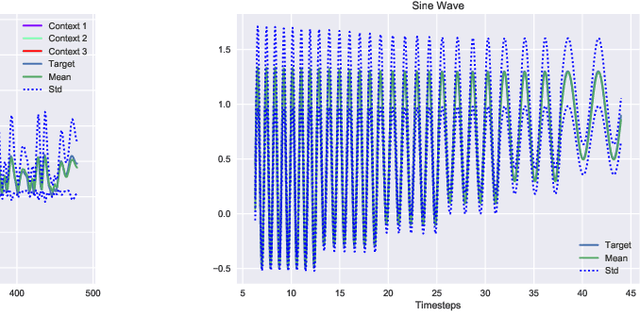
We extend Neural Processes (NPs) to sequential data through Recurrent NPs or RNPs, a family of conditional state space models. RNPs can learn dynamical patterns from sequential data and deal with non-stationarity. Given time series observed on fast real-world time scales but containing slow long-term variabilities, RNPs may derive appropriate slow latent time scales. They do so in an efficient manner by establishing conditional independence among subsequences of the time series. Our theoretically grounded framework for stochastic processes expands the applicability of NPs while retaining their benefits of flexibility, uncertainty estimation and favourable runtime with respect to Gaussian Processes. We demonstrate that state spaces learned by RNPs benefit predictive performance on real-world time-series data and nonlinear system identification, even in the case of limited data availability.
Conditional Neural Style Transfer with Peer-Regularized Feature Transform
Jun 10, 2019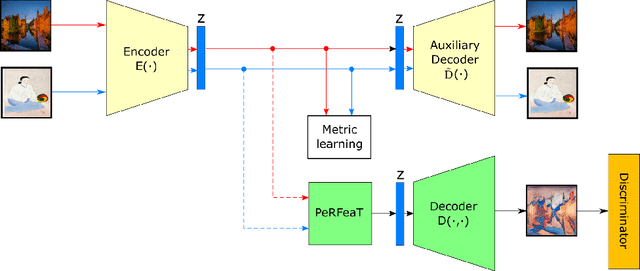
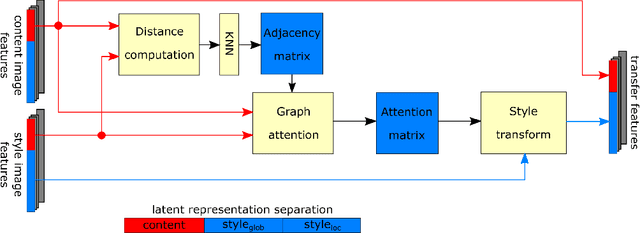


This paper introduces a neural style transfer model to conditionally generate a stylized image using only a set of examples describing the desired style. The proposed solution produces high-quality images even in the zero-shot setting and allows for greater freedom in changing the content geometry. This is thanks to the introduction of a novel Peer-Regularization Layer that recomposes style in latent space by means of a custom graph convolutional layer aiming at separating style and content. Contrary to the vast majority of existing solutions our model does not require any pre-trained network for computing perceptual losses and can be trained fully end-to-end with a new set of cyclic losses that operate directly in latent space. An extensive ablation study confirms the usefulness of the proposed losses and of the Peer-Regularization Layer, with qualitative results that are competitive with respect to the current state-of-the-art even in the challenging zero-shot setting. This opens the door to more abstract and artistic neural image generation scenarios and easier deployment of the model in. production
Differentiable Iterative Surface Normal Estimation
Apr 15, 2019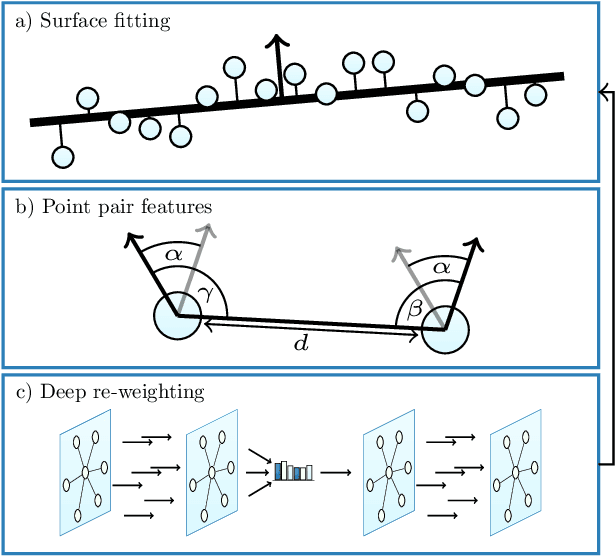
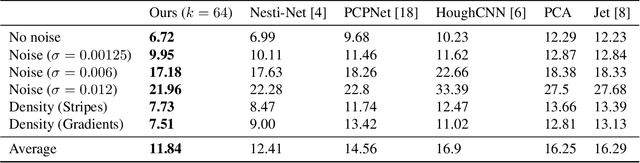
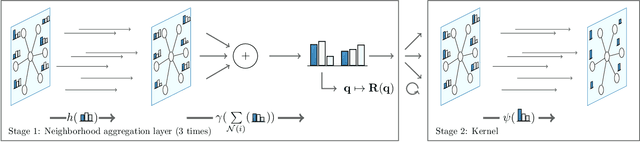

This paper presents an end-to-end differentiable algorithm for anisotropic surface normal estimation on unstructured point-clouds. We utilize graph neural networks to iteratively infer point weights for a plane fitting algorithm applied to local neighborhoods. The approach retains the interpretability and efficiency of traditional sequential plane fitting while benefiting from a data-dependent deep-learning parameterization. This results in a state-of-the-art surface normal estimator that is robust to noise, outliers and point density variation and that preserves sharp features through anisotropic kernels and a local spatial transformer. Contrary to previous deep learning methods, the proposed approach does not require any hand-crafted features while being faster and more parameter efficient.
NAIS-Net: Stable Deep Networks from Non-Autonomous Differential Equations
Nov 03, 2018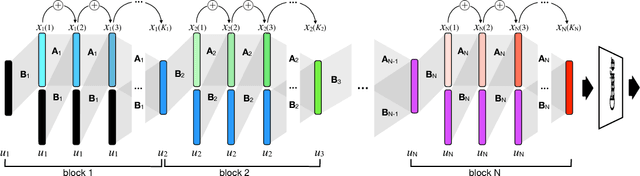

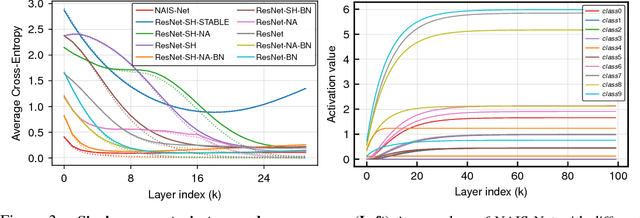
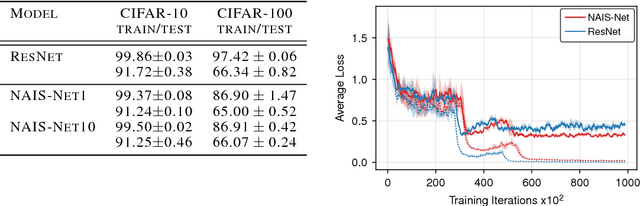
This paper introduces Non-Autonomous Input-Output Stable Network (NAIS-Net), a very deep architecture where each stacked processing block is derived from a time-invariant non-autonomous dynamical system. Non-autonomy is implemented by skip connections from the block input to each of the unrolled processing stages and allows stability to be enforced so that blocks can be unrolled adaptively to a pattern-dependent processing depth. NAIS-Net induces non-trivial, Lipschitz input-output maps, even for an infinite unroll length. We prove that the network is globally asymptotically stable so that for every initial condition there is exactly one input-dependent equilibrium assuming tanh units, and multiple stable equilibria for ReL units. An efficient implementation that enforces the stability under derived conditions for both fully-connected and convolutional layers is also presented. Experimental results show how NAIS-Net exhibits stability in practice, yielding a significant reduction in generalization gap compared to ResNets.
Learning Stochastic Recurrent Networks
Mar 05, 2015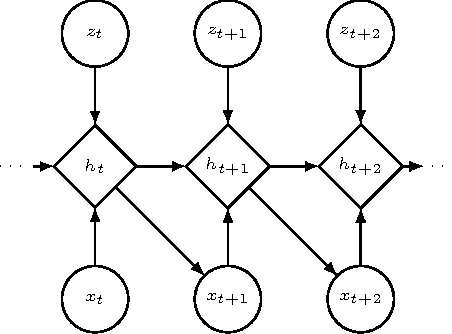

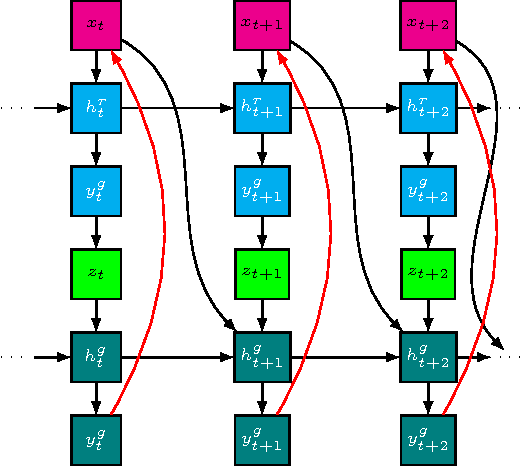
Leveraging advances in variational inference, we propose to enhance recurrent neural networks with latent variables, resulting in Stochastic Recurrent Networks (STORNs). The model i) can be trained with stochastic gradient methods, ii) allows structured and multi-modal conditionals at each time step, iii) features a reliable estimator of the marginal likelihood and iv) is a generalisation of deterministic recurrent neural networks. We evaluate the method on four polyphonic musical data sets and motion capture data.
Improving approximate RPCA with a k-sparsity prior
Dec 29, 2014
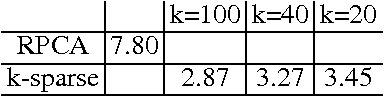

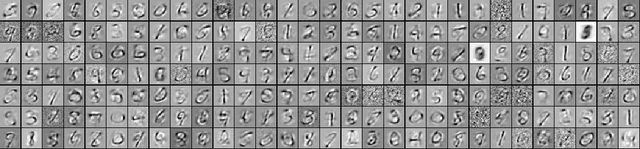
A process centric view of robust PCA (RPCA) allows its fast approximate implementation based on a special form o a deep neural network with weights shared across all layers. However, empirically this fast approximation to RPCA fails to find representations that are parsemonious. We resolve these bad local minima by relaxing the elementwise L1 and L2 priors and instead utilize a structure inducing k-sparsity prior. In a discriminative classification task the newly learned representations outperform these from the original approximate RPCA formulation significantly.
Variational inference of latent state sequences using Recurrent Networks
Sep 30, 2014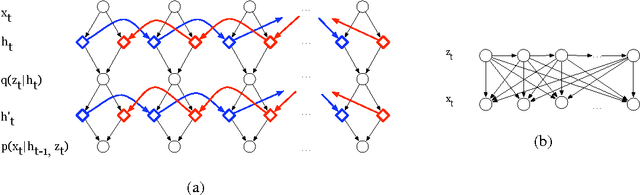


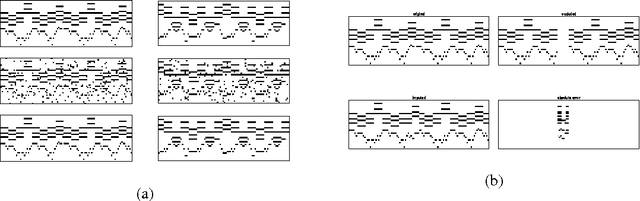
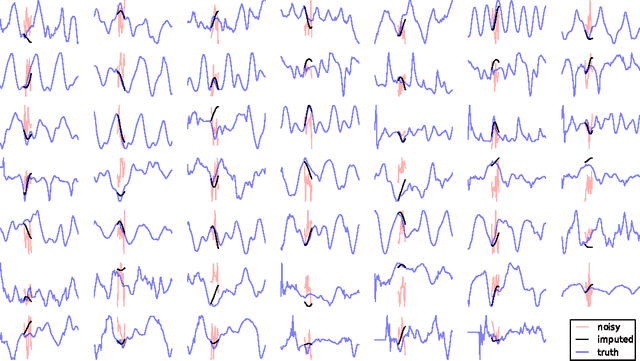
Recent advances in the estimation of deep directed graphical models and recurrent networks let us contribute to the removal of a blind spot in the area of probabilistc modelling of time series. The proposed methods i) can infer distributed latent state-space trajectories with nonlinear transitions, ii) scale to large data sets thanks to the use of a stochastic objective and fast, approximate inference, iii) enable the design of rich emission models which iv) will naturally lead to structured outputs. Two different paths of introducing latent state sequences are pursued, leading to the variational recurrent auto encoder (VRAE) and the variational one step predictor (VOSP). The use of independent Wiener processes as priors on the latent state sequence is a viable compromise between efficient computation of the Kullback-Leibler divergence from the variational approximation of the posterior and maintaining a reasonable belief in the dynamics. We verify our methods empirically, obtaining results close or superior to the state of the art. We also show qualitative results for denoising and missing value imputation.
On Fast Dropout and its Applicability to Recurrent Networks
Mar 05, 2014
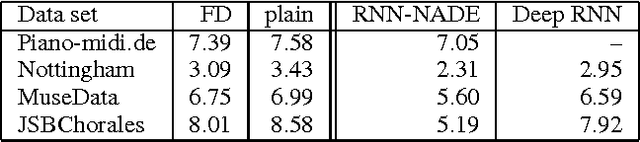

Recurrent Neural Networks (RNNs) are rich models for the processing of sequential data. Recent work on advancing the state of the art has been focused on the optimization or modelling of RNNs, mostly motivated by adressing the problems of the vanishing and exploding gradients. The control of overfitting has seen considerably less attention. This paper contributes to that by analyzing fast dropout, a recent regularization method for generalized linear models and neural networks from a back-propagation inspired perspective. We show that fast dropout implements a quadratic form of an adaptive, per-parameter regularizer, which rewards large weights in the light of underfitting, penalizes them for overconfident predictions and vanishes at minima of an unregularized training loss. The derivatives of that regularizer are exclusively based on the training error signal. One consequence of this is the absense of a global weight attractor, which is particularly appealing for RNNs, since the dynamics are not biased towards a certain regime. We positively test the hypothesis that this improves the performance of RNNs on four musical data sets.