Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving approximate RPCA with a k-sparsity prior
Paper and Code
Dec 29, 2014
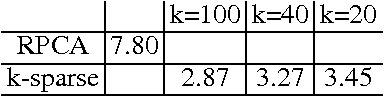

A process centric view of robust PCA (RPCA) allows its fast approximate implementation based on a special form o a deep neural network with weights shared across all layers. However, empirically this fast approximation to RPCA fails to find representations that are parsemonious. We resolve these bad local minima by relaxing the elementwise L1 and L2 priors and instead utilize a structure inducing k-sparsity prior. In a discriminative classification task the newly learned representations outperform these from the original approximate RPCA formulation significantly.
View paper on