 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTM: A Search Space Odyssey
Oct 04, 2017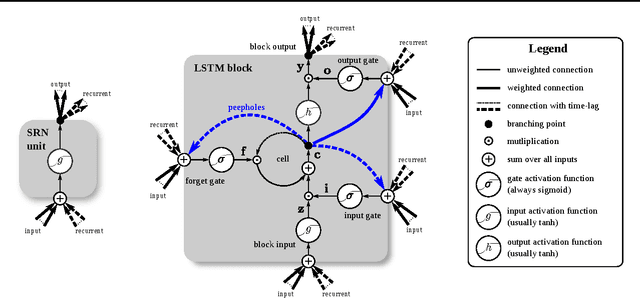
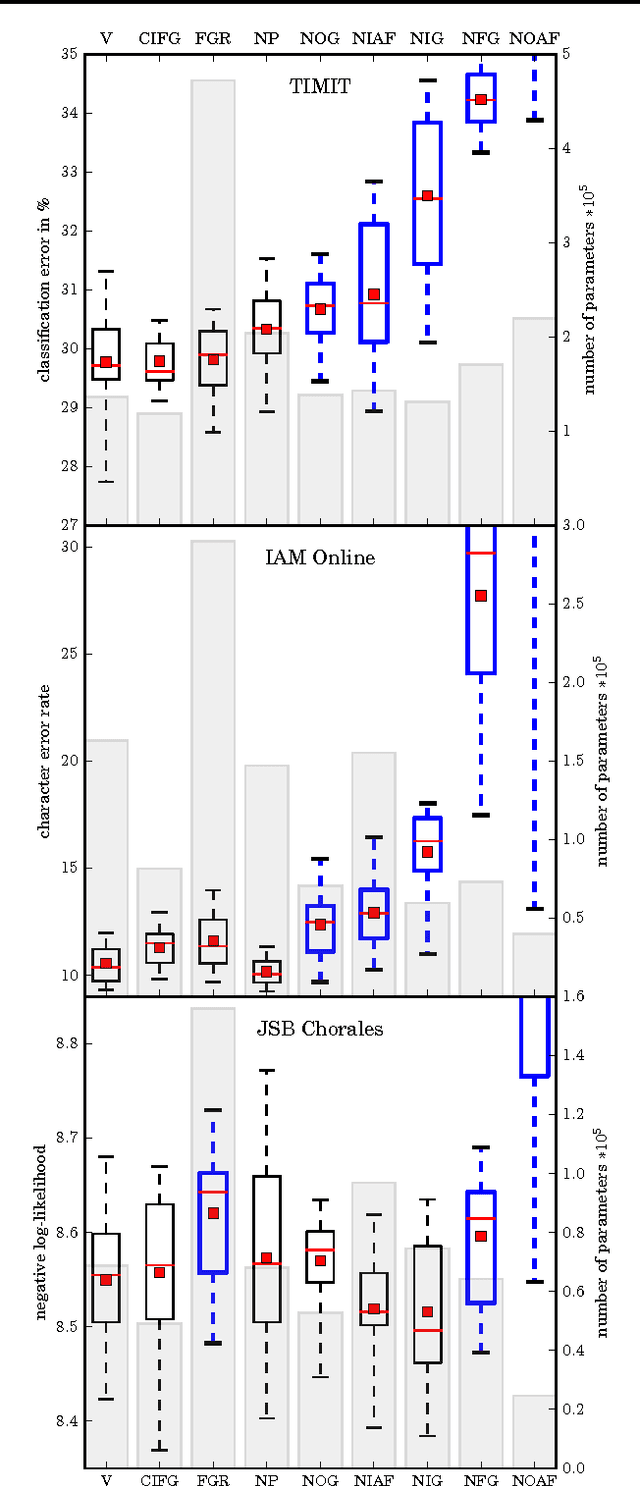
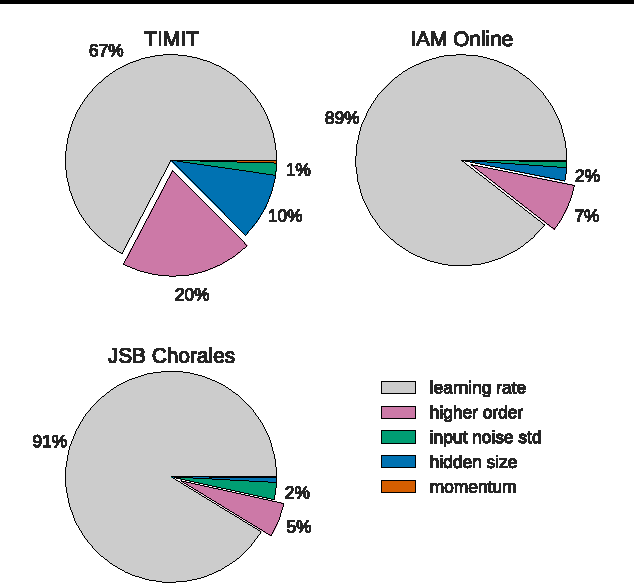
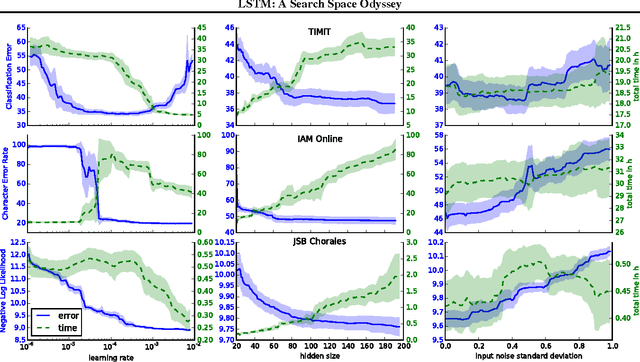
Several variants of the Long Short-Term Memory (LSTM) architecture for recurrent neural networks have been proposed since its inception in 1995. In recent years, these networks have become the state-of-the-art models for a variety of machine learning problems. This has led to a renewed interest in understanding the role and utility of various computational components of typical LSTM variants. In this paper, we present the first large-scale analysis of eight LSTM variants on three representative tasks: speech recognition, handwriting recognition, and polyphonic music modeling. The hyperparameters of all LSTM variants for each task were optimized separately using random search, and their importance was assessed using the powerful fANOVA framework. In total, we summarize the results of 5400 experimental runs ($\approx 15$ years of CPU time), which makes our study the largest of its kind on LSTM networks. Our results show that none of the variants can improve upon the standard LSTM architecture significantly, and demonstrate the forget gate and the output activation function to be its most critical components. We further observe that the studied hyperparameters are virtually independent and derive guidelines for their efficient adjustment.
* 12 pages, 6 figures
Why Artificial Intelligence Needs a Task Theory --- And What It Might Look Like
May 12, 2016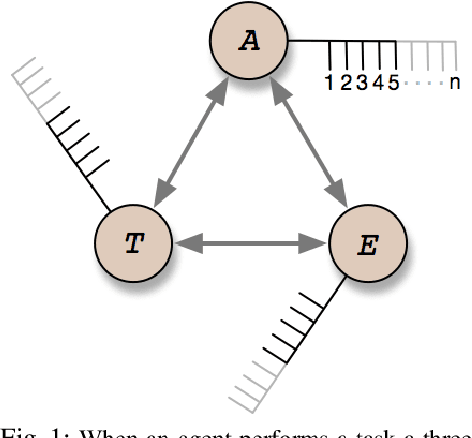
The concept of "task" is at the core of artificial intelligence (AI): Tasks are used for training and evaluating AI systems, which are built in order to perform and automatize tasks we deem useful. In other fields of engineering theoretical foundations allow thorough evaluation of designs by methodical manipulation of well understood parameters with a known role and importance; this allows an aeronautics engineer, for instance, to systematically assess the effects of wind speed on an airplane's performance and stability. No framework exists in AI that allows this kind of methodical manipulation: Performance results on the few tasks in current use (cf. board games, question-answering) cannot be easily compared, however similar or different. The issue is even more acute with respect to artificial *general* intelligence systems, which must handle unanticipated tasks whose specifics cannot be known beforehand. A *task theory* would enable addressing tasks at the *class* level, bypassing their specifics, providing the appropriate formalization and classification of tasks, environments, and their parameters, resulting in more rigorous ways of measuring, comparing, and evaluating intelligent behavior. Even modest improvements in this direction would surpass the current ad-hoc nature of machine learning and AI evaluation. Here we discuss the main elements of the argument for a task theory and present an outline of what it might look like for physical tasks.
First Experiments with PowerPlay
Oct 31, 2012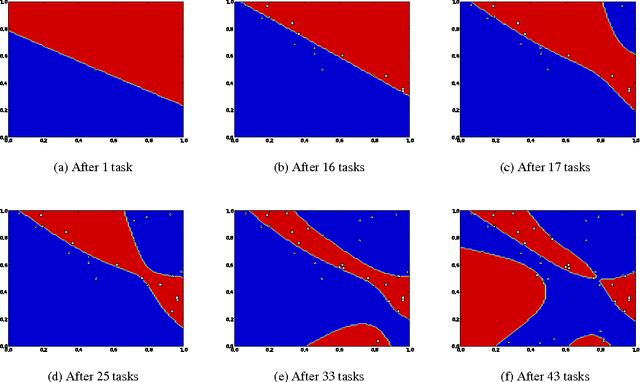


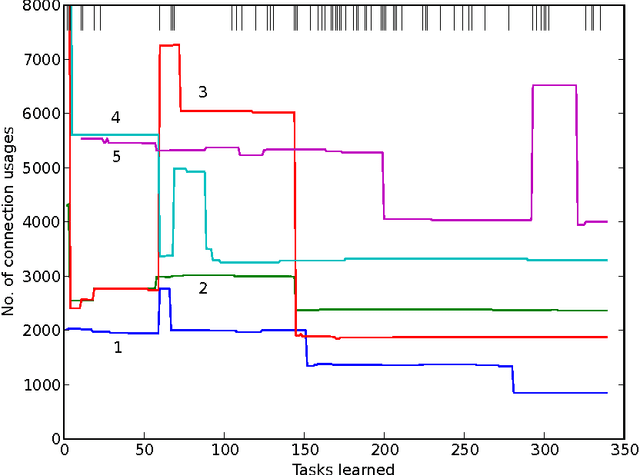
Like a scientist or a playing child, PowerPlay not only learns new skills to solve given problems, but also invents new interesting problems by itself. By design, it continually comes up with the fastest to find, initially novel, but eventually solvable tasks. It also continually simplifies or compresses or speeds up solutions to previous tasks. Here we describe first experiments with PowerPlay. A self-delimiting recurrent neural network SLIM RNN is used as a general computational problem solving architecture. Its connection weights can encode arbitrary, self-delimiting, halting or non-halting programs affecting both environment (through effectors) and internal states encoding abstractions of event sequences. Our PowerPlay-driven SLIM RNN learns to become an increasingly general solver of self-invented problems, continually adding new problem solving procedures to its growing skill repertoire. Extending a recent conference paper, we identify interesting, emerging, developmental stages of our open-ended system. We also show how it automatically self-modularizes, frequently re-using code for previously invented skills, always trying to invent novel tasks that can be quickly validated because they do not require too many weight changes affecting too many previous tasks.