 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudget-Aware Pruning: Handling Multiple Domains with Less Parameters
Sep 20, 2023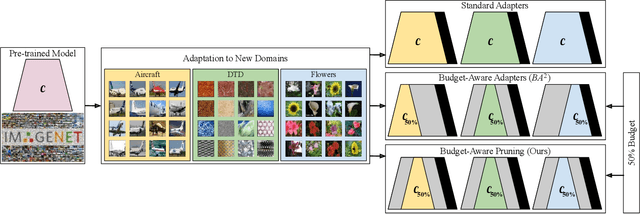
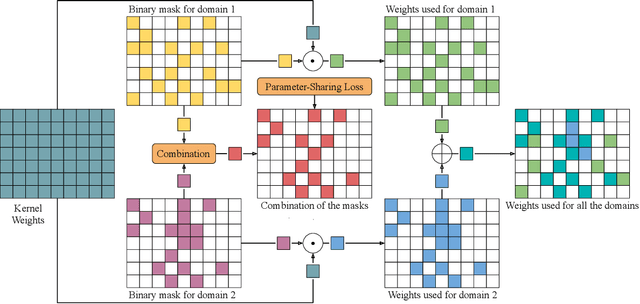
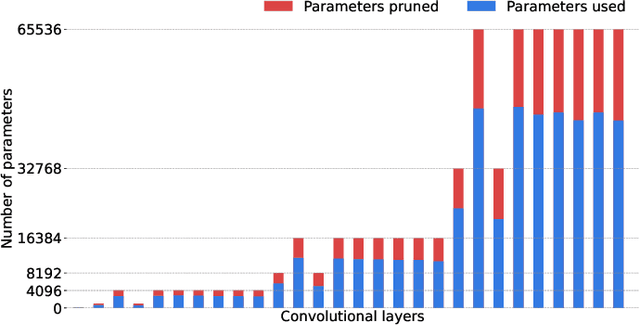
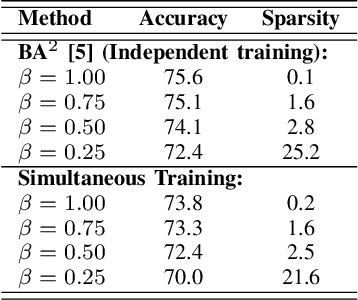
Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still has a high computational cost and demands a significant amount of parameters. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Another limitation is that deep models are usually specialized into a single domain or task, requiring them to learn and store new parameters for each new one. Multi-Domain Learning (MDL) attempts to solve this problem by learning a single model that is capable of performing well in multiple domains. Nevertheless, the models are usually larger than the baseline for a single domain. This work tackles both of these problems: our objective is to prune models capable of handling multiple domains according to a user-defined budget, making them more computationally affordable while keeping a similar classification performance. We achieve this by encouraging all domains to use a similar subset of filters from the baseline model, up to the amount defined by the user's budget. Then, filters that are not used by any domain are pruned from the network. The proposed approach innovates by better adapting to resource-limited devices while, to our knowledge, being the only work that handles multiple domains at test time with fewer parameters and lower computational complexity than the baseline model for a single domain.
Parameter Sharing in Budget-Aware Adapters for Multi-Domain Learning
Oct 14, 2022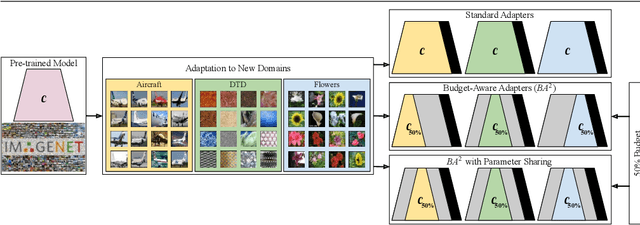
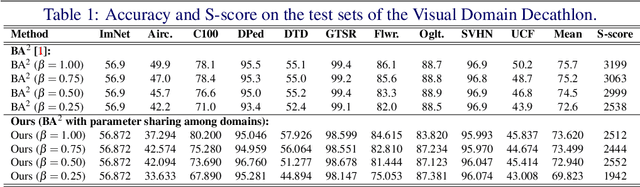
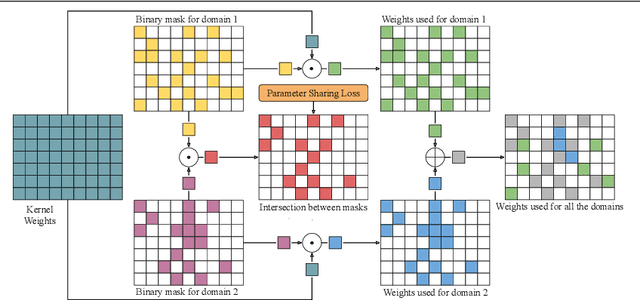
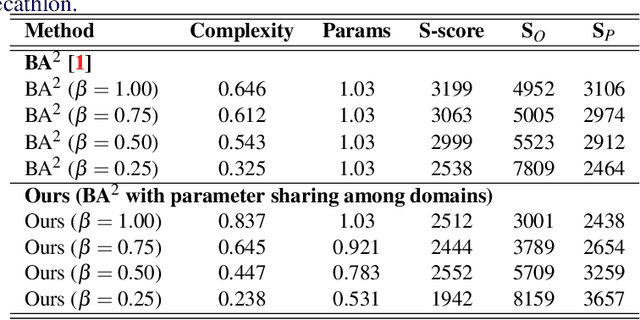
Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still demands a high computational cost and a significant amount of parameters that need to be learned for each new domain. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Multi-domain learning addresses this problem by adapting to new domains while retaining the knowledge of the original domain. One limitation of most multi-domain learning approaches is that they usually are not designed for taking into account the resources available to the user. Recently, some works that can reduce computational complexity and amount of parameters to fit the user needs have been proposed, but they need the entire original model to handle all the domains together. This work proposes a method capable of adapting to a user-defined budget while encouraging parameter sharing among domains. Hence, filters that are not used by any domain can be pruned from the network at test time. The proposed approach innovates by better adapting to resource-limited devices while being able to handle multiple domains at test time with fewer parameters and lower computational complexity than the baseline model.
Deep Learning-based Type Identification of Volumetric MRI Sequences
Jun 06, 2021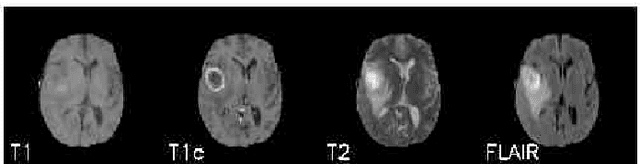
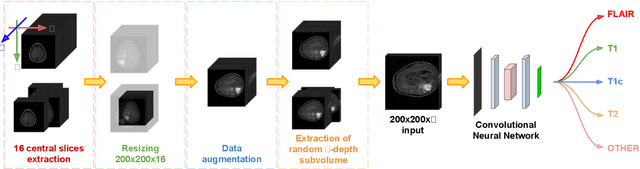
The analysis of Magnetic Resonance Imaging (MRI) sequences enables clinical professionals to monitor the progression of a brain tumor. As the interest for automatizing brain volume MRI analysis increases, it becomes convenient to have each sequence well identified. However, the unstandardized naming of MRI sequences makes their identification difficult for automated systems, as well as makes it difficult for researches to generate or use datasets for machine learning research. In the face of that, we propose a system for identifying types of brain MRI sequences based on deep learning. By training a Convolutional Neural Network (CNN) based on 18-layer ResNet architecture, our system can classify a volumetric brain MRI as a FLAIR, T1, T1c or T2 sequence, or whether it does not belong to any of these classes. The network was evaluated on publicly available datasets comprising both, pre-processed (BraTS dataset) and non-pre-processed (TCGA-GBM dataset), image types with diverse acquisition protocols, requiring only a few slices of the volume for training. Our system can classify among sequence types with an accuracy of 96.81%.
Keep your Eyes on the Lane: Attention-guided Lane Detection
Oct 22, 2020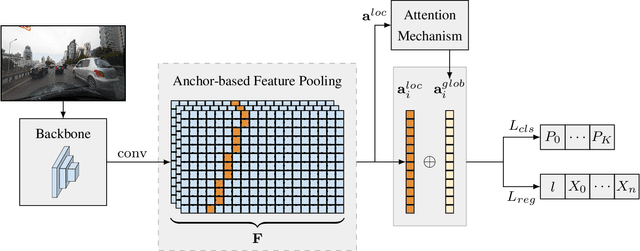
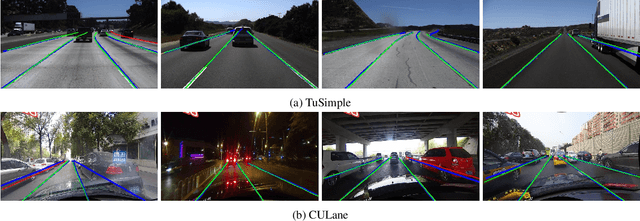
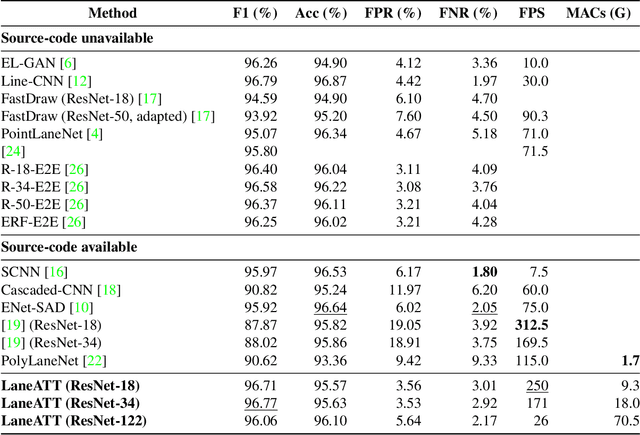
Modern lane detection methods have achieved remarkable performances in complex real-world scenarios, but many have issues maintaining real-time efficiency, which is important for autonomous vehicles. In this work, we propose LaneATT: an anchor-based deep lane detection model, which, akin to other generic deep object detectors, uses the anchors for the feature pooling step. Since lanes follow a regular pattern and are highly correlated, we hypothesize that in some cases global information may be crucial to infer their positions, especially in conditions such as occlusion, missing lane markers, and others. Thus, we propose a novel anchor-based attention mechanism that aggregates global information. The model was evaluated extensively on two of the most widely used datasets in the literature. The results show that our method outperforms the current state-of-the-art methods showing both a higher efficacy and efficiency. Moreover, we perform an ablation study and discuss efficiency trade-off options that are useful in practice. To reproduce our findings, source code and pretrained models are available at https://github.com/lucastabelini/LaneATT
Deep Traffic Sign Detection and Recognition Without Target Domain Real Images
Jul 30, 2020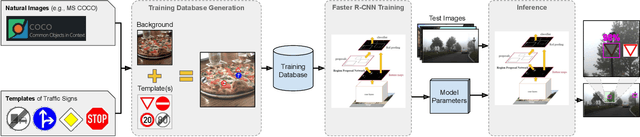
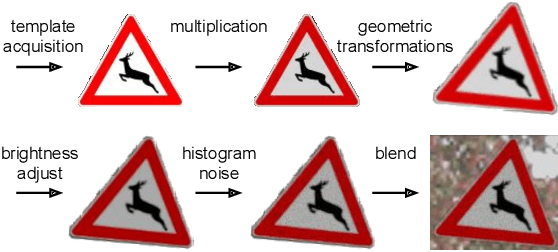


Deep learning has been successfully applied to several problems related to autonomous driving, often relying on large databases of real target-domain images for proper training. The acquisition of such real-world data is not always possible in the self-driving context, and sometimes their annotation is not feasible. Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. Particularly, traffic sign detection is a challenging problem in which these three issues are seen altogether. To address these challenges, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the target-domain, and (ii) templates of the traffic signs. The method does not aim at overcoming the training with real data, but to be a compatible alternative when the real data is not available. The effortlessly generated database is shown to be effective for the training of a deep detector on traffic signs from multiple countries. On large data sets, training with a fully synthetic data set almost matches the performance of training with a real one. When compared to training with a smaller data set of real images, training with synthetic images increased the accuracy by 12.25%. The proposed method also improves the performance of the detector when target-domain data are available.
PolyLaneNet: Lane Estimation via Deep Polynomial Regression
Apr 23, 2020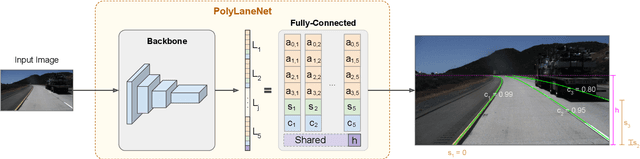


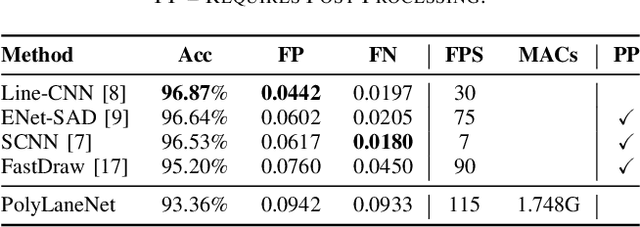
One of the main factors that contributed to the large advances in autonomous driving is the advent of deep learning. For safer self-driving vehicles, one of the problems that has yet to be solved completely is lane detection. Since methods for this task have to work in real time (+30 FPS), they not only have to be effective (i.e., have high accuracy) but they also have to be efficient (i.e., fast). In this work, we present a novel method for lane detection that uses as input an image from a forward-looking camera mounted in the vehicle and outputs polynomials representing each lane marking in the image, via deep polynomial regression. The proposed method is shown to be competitive with existing state-of-the-art methods in the TuSimple dataset, while maintaining its efficiency (115 FPS). Additionally, extensive qualitative results on two additional public datasets are presented, alongside with limitations in the evaluation metrics used by recent works for lane detection. Finally, we provide source code and trained models that allow others to replicate all the results shown in this paper, which is surprisingly rare in state-of-the-art lane detection methods.
Budget-Aware Adapters for Multi-Domain Learning
May 15, 2019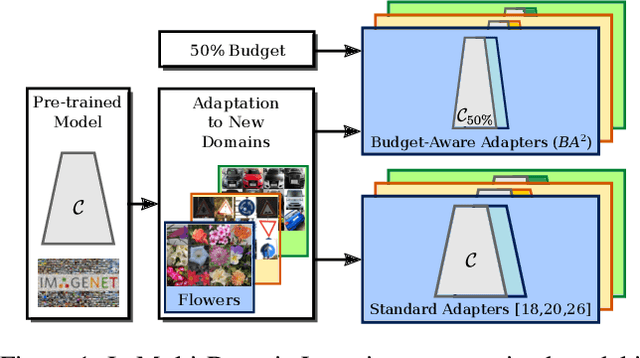
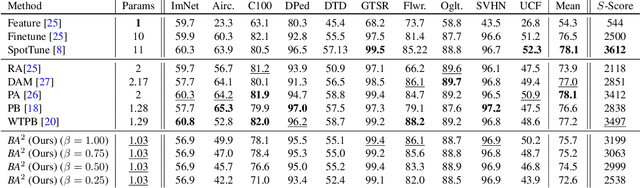


Multi-Domain Learning (MDL) refers to the problem of learning a set of models derived from a common deep architecture, each one specialized to perform a task in a certain domain (e.g., photos, sketches, paintings). This paper tackles MDL with a particular interest in obtaining domain-specific models with an adjustable budget in terms of the number of network parameters and computational complexity. Our intuition is that, as in real applications the number of domains and tasks can be very large, an effective MDL approach should not only focus on accuracy but also on having as few parameters as possible. To implement this idea we derive specialized deep models for each domain by adapting a pre-trained architecture but, differently from other methods, we propose a novel strategy to automatically adjust the computational complexity of the network. To this aim, we introduce Budget-Aware Adapters that select the most relevant feature channels to better handle data from a novel domain. Some constraints on the number of active switches are imposed in order to obtain a network respecting the desired complexity budget. Experimentally, we show that our approach leads to recognition accuracy competitive with state-of-the-art approaches but with much lighter networks both in terms of storage and computation.